
良いアルゴリズムの定義って?

昨今のソフトウェアエンジニアリングの業界では、プログラム言語とフレームワークばかりが注目されている中、そこにローコードやノーコードがどんどん進出してきてる…そんな勢力図が見え隠れしている気がしてならないのですが、案外誰もまともに取り合っていないように見えるのが
『アルゴリズム』
です。
プログラム言語を活かすも殺すも、変更容易性や試験容易性にも深く関わってくるも、すべてパッケージやクラス、モジュールなどの構成とアルゴリズムの美しさ…というか出来次第だと思うのですが、そういったところがずいぶん軽視されている気がしてなりません。
アルゴリズムは非常に奥が深い技術です。
そもそもアルゴリズムとは、「問題を解決するための手順や計算方法」を指す言葉です。「算法」と呼ばれることもありますが、答えを求めるときの手順を具体的かつ明確に示したものだと言えます。つまり、アルゴリズムとは、その手順に沿っていれば誰でも同じ答えが得られるものを指します。
当たり前のことですが、正しく理解すれば簡単なアルゴリズムは特段IT業界でなくても有用です。要するに「再現性の高い、論理的な手続き」のことですから、日常の中に取り入れるのは何も難しいことではありません。
極論すれば、
1+1=2
というのもアルゴリズムなわけです。算数の世界においては「誰が」「いつ」「どこで」「何度」計算しても同じ結果が再現されますよね。「1に1を足す」という手続きをすれば、「2になる」という結果を導き出せるわけです(算数に限った話ですけど(数学の世界ではまた別))。
もう少し現実的な例をあげるなら、料理のレシピなどもアルゴリズムと言って差し支えないでしょう。家電製品の取扱説明書もそうかもしれませんね。
そんななじみの深いアルゴリズムですが、人が読み解こうとするからか安易に「わかりやすいアルゴリズム」が「良いアルゴリズム」であると勘違いされがちです。
たとえば、一昔前はIT業界の中で新人教育によく題材とされていた「検索」のアルゴリズムを考えてみましょう。
アルファベット大文字26文字のカードから「A」を探し当てる
検索そのものはそう難しいことではありません。もし仮にカードが最初にアルファベット順に並べてあれば、最初の1枚目が「A」に決まっています。
ひらがな50音カードから「ん」を探し当てるのも、そう難しいことではありません。もしカードがあいうえお順に並べてあれば、最後の1枚が「ん」に決まっています。
性能的な要件やスマートさを考えなければバブルソートだろうが、ヒープソートだろうが、二分木探索だろうが、はたまた全く新しい検索方法だろうがまぁ何かしら思いつくことでしょう。
しかし、カードが10,000種類あったらどうでしょう。
1枚のカードをめくるのに1秒かかるとしても、最後のカードに行き着くには10,000秒、約3時間が必要です。できるかどうか以前に嫌気がさしてしまって人手で検索してみたいという気にもならないでしょう。
100万種類だったら?
1億種類だったら?
コンピュータに検索させるとしても嫌気がさしてきそうです。検索に時間がかかるため待ち時間が長くなるからです。この「端からめくっていって探しあてる」方法をアルゴリズムの用語では"逐次探索"と呼びます。
ん-…昨今のソフトウェア開発において「逐次」という言葉自体が死語になりつつある気がしますね。記憶媒体に磁気テープが使われていた頃はまだまだ普通に使われていましたけども。
『探索』と『整列』はアルゴリズムにおいて、切っても切り離せない最も重要な要素です。
逐次探索は非常にシンプルでわかりやすいものの、検索方法としては最も古典的で効率の悪い方法の1つといえます。効率が悪いうえに、大きな課題/問題に対してはその問題の大きさに比例して(実際にはそれ以上に)時間がかかります。
ここで、二分木探索というアルゴリズムを採用してみることにしましょう。
二分木探索を簡単に説明すると、データを
「親1つの下に子が2つ」
「右の子は左の子より大きい」
という形式で整理するというものです。これも「基本情報技術者資格」程度の知識があれば知らない人はいないと言われるアルゴリズムの基本ですよね。
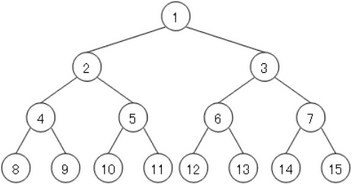
データを探索するのに必要なのは最上位の親から最下位の子まで、二分木構造をたどるだけの時間です。データが10,000個だったら二分木構造の深さはだいたい14段。1億個だったらだいたい19段くらいでしょう。
「問題の大きさに比例して恐ろしい時間が必要になる」ということはありません。このような探索アルゴリズムはシンプルな探索方法の延長では理解できません。当然ながらほんの少し検索について勉強している人でないと、思いつくこともないでしょう。
しかし、理解すれば逐次探索のような途方もない労力の必要性がない、ということはなんとなくわかるのではないでしょうか。「とっつきにくい」というイメージのある二分木探索ですが、基本的な考え方は非常にシンプルです。
ここで挙げた「逐次探索」「二分木探索」はそれぞれ
「一番わかりやすいけれども、一番効率が悪い」(逐次探索)
「かなりわかりにくいけれども、非常に効率的」(二分木探索)
という特徴を持っています。
どう使い分けていけばよいのでしょうか?
逐次検索のもつメリットは、
「わかりやすい」
「検索を始める前に準備をする必要がない」
「特殊な学習も必要としない」
ということです。
ですから、検索する対象がたかだか「アルファベット26文字のカード」
「50音それぞれで始まるカルタ」「最大100枚しかない百人一首」程度のデータ量であれば、検索に逐次検索を使用したからといって全体の効率が下がる心配はしなくてよいでしょう。
逆に言えば、人間が手でカードをめくっていっても現実的な時間で探せるわけです。逆に、"対象の総数が将来にわたって増えない"というお墨付きでもないかぎり逐次検索は「ちょっと待て、本当にこれでいいのか?」と考えたほうがよいということです。毎年何百、何千、何万と増え続けるのであれば、将来的に圧倒的に負担が大きくなるということですからね。
二分木探索の持つ特徴は、
「わかりにくい」
「検索を始める前に、二分木構造を作る必要がある」
「二分木探索について、あらかじめ理解しておく必要がある」
ということです。
対象の総数が多ければ、「二分木を作る」ことそのものがかなり負荷の高い処理になることもあります。いわゆる「イニシャルコストが高い」というデメリットがあるわけですね。
しかし、このあと探索を繰り返していけばいくほど、最初の「二分木を作る」処理の負荷は相対的に下がっていきますので、将来にわたって予想される探索回数が「数回」というのであれば、もしかすると「二分木を作る」負荷が無視できなくなるかもしれません。
以上をまとめると次のようになります。

決して「逐次探索は悪」「二分木探索は善」ではないことが、おわかりいただけるでしょう。「どこでも有効」「どこでも妥当」なアルゴリズムはありません。状況や条件に応じて、常に最適解を検討する必要があります。
さきほどの「1+1=2」という計算についても同様です。
以前触れましたが、そもそも「1+1=2」という計算が成り立つのは、実はある条件を満たす時だけ…つまり計算の対象となるものが同じ属性や単位を持っている場合の話です。
わかりやすく言えば、
リンゴ1個とみかん1個を足しても、リンゴ2個にはならない
リンゴ1個と別のリンゴ1個を足すからこそ、リンゴ2個になる
ということです。このようにアルゴリズムにはそのアルゴリズムを採用するために必要な条件を整えることができて、はじめて最適解となりうるわけです。
これは個人として、企業として、他人からあるいは社会から「信用」を得るために安定した成果をあげる…ひいては再現性の高い成果を出し続けるためにも大事な考え方となります。
だからこそ、多くのビジネスシーンにおいて「自ら考える力」がとても重要だといわれているわけです。
そう言う意味でも様々なアルゴリズムに触れ、身につけ、取捨選択する機会を持ち続けることはとても大切なことだということがわかります。
思考することを放棄してしまって
「〇〇さんがこれで良いといったから」
「以前はこれで成功したから」
みたいな発想しかできない人には、一生アルゴリズムを使いこなすことは難しいのではないでしょうか。
いただいたサポートは、全額本noteへの執筆…記載活動、およびそのための情報収集活動に使わせていただきます。