
Tableau備忘録 | Data Saberを目指して Ord7編

こんにちは。
石川県のシビックテック団体Code For NotoのSKです。
Data Sabar認定を目指して、Tableauを鋭意学習中でございます。
今回は以下動画の内容のポイントをまとめていきたいと思います。
パフォーマンスの考え方
なぜパフォーマンスが大事
フローが途切れてしまう
集中できない
イライラしちゃう
早く解決したい。次のアイデアに結びつかない
大事な理由
迅速に答えを見つけることができる
分析のFlowに乗れる
似たようなワークブックを量産せずにすむ
Fast workbook = Happy users
パフォーマンスを決める要素
やりたいこと
だれが
なんのために
どのように使うのか
Too muchになるダッシュボードを作る必要はない
知識
どういう操作が遅くなるか知る
データ量
全RAWデータ
集計データ
絞ったデータ
処理能力(お金で解決できやすい)
ハードウェア
DB製品
チューニング
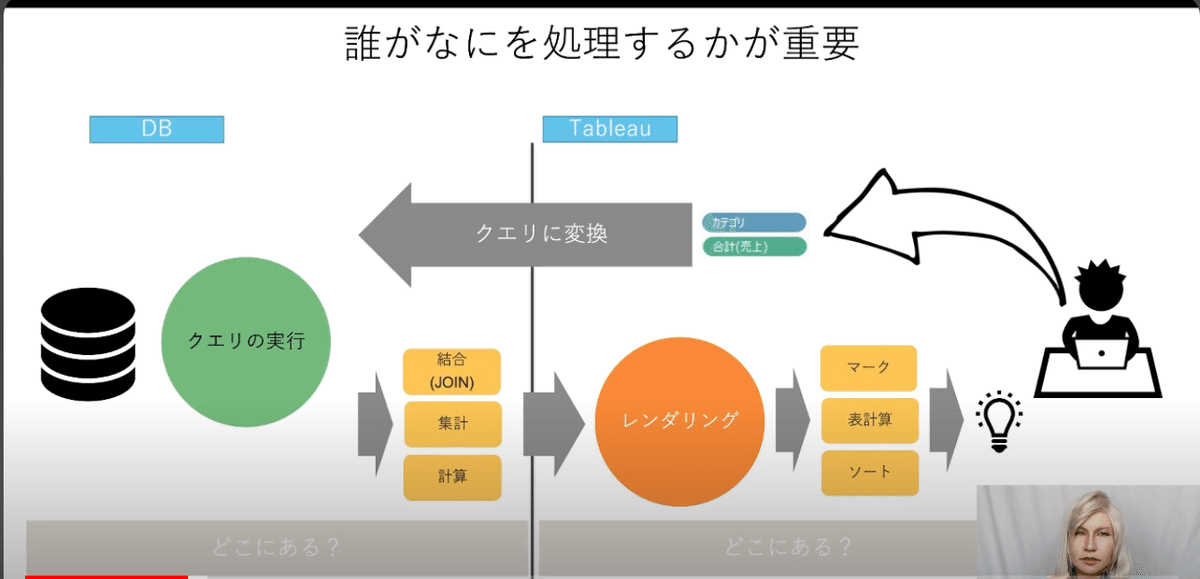
だれがなにを処理するかが重要
DB
クエリの実行
JOIN
集計
計算
Tableau
レンダリング
表計算
マーク
ソート
ベストプラクティス
データが遅ければ、Tableauで早くなることはない
Desktopで遅ければ、Serverで早くなることはない
入れすぎ厳禁(シンプルに)
我々もTableauの気持ちをくみとっていこう!!
ヘルプタブからパフォーマンスを見ることができる
データソース
増えるデータ vs ハードウェア
対象データの件数
レコード数
行数が多い vs 集計され行数が少ない
フィルターを使用し、件数を削減
抽出フィルター
データソースフィルター
リレーショナルデータベース
インデックス
表の結合キーの列
フィルターで使用される列
パーティショニング(テーブル内のデータを分割して保持する)
ディメンション項目
NULL
ディメンション項目ではNULLを避ける
NULLがあると遅い原因となる
NULLを無くしてインデックス効果を向上
DB側でテーブルを準備
集計データを事前準備
Tableauで複雑な計算をさける
結合 vs ブレンド
結合
複数のテーブルをひとつのテーブルにする
同じデータベースであれば、表の結合が望ましい
インデックスを有効利用
1本のクエリ
クロスデータベース結合
データベースが違くても結合できる
ブレンド
レコード数が多く、表の結合に適さない場合
集計ビュー
抽出vs ライブ接続
データエンジンの性能は相対的なもの
データエンジンが比較的速いケース
最適化されていないデータベース
PCファイル形式のデータソース
データエンジンが比較的遅いケース
高速マシンのクラスター
抽出のパフォーマンス
抽出のパフォーマンスに影響する要因
行数
列数(抽出ファイル作成時に影響)
データ濃度(カーディなりティ、ディメンションメンバーの数)
ディメンション vs メジャー
⭐️集計された抽出
ドラッグアンドドロップで集計する際に、それより細かい粒度っていらないよね、、だから集計してもっておくことができる。あまりに細かすぎるディメンションを持たない
集計された抽出を集計分析に使用
DWHから負荷分散
明細データはDWHに保持し、ライブ接続
抽出を高速化
表示単位に集計
不要なディメンションメンバーをフィルター
使用していないフィールドを非表示 計算
計算フィールド
計算
行レベル計算(IF 〇〇とか)と集計計算(SUM,AVGとか)
データベース側で計算処理
行レベル計算はスケーラビリティが高い
DBチューニング施策が効果を出しやすい
行レベル計算と集計計算を分割しよう!!(再利用しやすい)
行レベル計算を1つの計算フィールドに
集計計算を2つめの計算フィールドに
表計算
クエリ結果を受け取り、Tableauが計算処理
計算フィールドよりもTableauの計算負荷が高い
計算フィールドVSネイティブ機能
ネイティブ機能は計算フィールドよりも速いことが多い
ディメンションメンバーのグルーピング
グループが有効
ディメンションメンバーの名前変更
別名の編集が有効
メジャー値のカテゴリ化
ビンが有効
⭐️計算フィールド
データ型はパフォーマンスへの影響が大きい
整数はブールより速い
整数・ブールは文字よりも速い
ロジック計算にはブーリアンを使用する
悪い例
IF [DATE]=TODAY() THEN "TODAY" ELSE "NOT TODAY" END
良い例
[DATE]=TODAY()
文字の検索
CONTAINS()はFIND()より速い
条件式で参照するパラメータ
表示名を利用
整数として計算ロジックで参照
日付計算
初手は右クリックでDATE型になるかどうか確かめる
次にDATEPARSE
フィルター
不連続フィルターは遅い
TableauはDBにクエリを発行し、すべてのディメンションを取得しにいく
不連続だと全部一個ずつ取得しにいく(1〜10を不連続で取得するとき、いちいち2があるかとか3があるかなどを確認しながら取りに行くため遅くなる)
範囲(連続)フィルターは早い
大量の不連続の値を取り込むより早い
データの濃度(1列に入っている値の種類)が高い場合、範囲フィルターのほうがはやい
ディメンションフィルター
保持・除外フィルターは遅い
インデックスやパーティションが有効に作用する
日付フィルター
不連続日付
遅い
連続日付の範囲指定
範囲で取得するのでクエリ結果が早い
⭐️相対日付はさらに早い
クイックフィルター(項目が表示されているフィルター)
項目が表示されたクイックフィルターは遅い
表示する必要のある項目はすべて取得しなければいけない
複数の値(ドロップダウン)
単位値
数値フィルター
範囲日付フィルター
項目がデータに依存しないクイックフィルターは早い
フィルターのための項目を探す必要がない
複数の値
ワイルドカード照合
相対日付フィルター
期間を参照フィルター
クイックフィルターの表示項目
2種のクイックフィルター
データベース内のすべての値
他のフィルターが変更されたとしても影響されない
関連値のみ
例)カテゴリえらんだら、サブカテゴリのフィルタになる
ほかのフィルターが関連してくる
クエリだらけになって重くなる。
パフォーマンス vs ビジュアルナビゲーションはトレードオフ
ダッシュボード上のクイックフィルター
大量のクイックフィルターは遅い原因
クイックフィルターの代わりにguided Analyticsを活用する
異なるディメンションレベルで複数のシートを作る
フィルターアクションを活用する
クイックフィルターの代わりに・・・
フィルターアクションを活用する
PROS
複数項目選択をサポート
選択項目はデータに応じてダイナミックに変動
データソース間を跨いでフィルターできる
フィルター用のソースシートからもインサイトを得られる
CONS?
設定がちょっと難しい
UIがクイックフィルターやパラメータの感じとちょっと違う(むしろ使いやすい)
ソースシートはデータソースからクエリされる必要がある(クイックフィルターと同じだしむしろリッチに見せることができる)
パラメータを活用
PROS
フィルター項目表示用のクエリが不要
データソース間を跨いでフィルターできる
CONS
単一項目の身しか選択できない
パラメータ*計算フィールド=複雑になりがち
クイックフィルターはない方がいい!!(極論)
フィルターなんかせずに欲しい情報が取得できることが望ましい。
いきなり欲しい情報を提供しようよ
フィルターの種類と順番を意識する!!
抽出フィルター
データソースフィルター
コンテキストフィルター
FIXED
セットフィルター
ディメンションフィルター
EXCLUDE/INCLUDE
メジャーフィルター
表計算フィルター
抽出フィルター、データソースフィルターはワークブックにも運ばれてこない。絶対使わないものはここで
ダッシュボードデザイン
ビュー
本当に必要なものだけを取得する
不要な"詳細"は外す
チャート vs クロス集計
行列の少ないマーク表示は表形式のものより早く表示できる
テキストテーブルは描画するには大量のメモリが必要
詳細なクロス集計を表示するにはGuided Analysisを使うこと
不要な地理的役割は設定しない
生成された緯度経度を参照する時間を省く
ダッシュボードの場合
シートやクイックフィルターを少なくする
1シートにつき少なくとも1クエリ
1クイックフィルターにつき少なくとも1クエリ
タブを非表示にする
タブの表示されているビューはすべてプロセスが走る
タブを減らすとパフォーマンスが上がる
フィルターアクションの"すべての値を除外"
すべてのデータを取得する重たいクエリを避ける
サイズを固定したダッシュボード
異なるウィンドウサイズで毎回描画しなければいけない
VizQL Serverはユーザーごとにレンダリング
自動はキャッシュヒット率が低い
この記事が気に入ったらサポートをしてみませんか?