
【第1話】 統計分析をRからJuliaにできるか

Juliaというプログラミング言語に注目しています。
PythonからJuliaへ移行する場合を考えて少し書き始めたのですが、データサイエンスやディープラーニング、いろんな分野でどうしてもFirst choice of LanguageはPythonになってしまいますね。TIOBE indexでもPythonは3位。Juliaは42位です。それでも数年以内にどんどん上がってくるでしょう。本当に注目の言語です。
友人と統計分析の「復習」をはじめました。統計の分野ではRが有名です。ちなみにTIOBEではRは15位です。一緒に使っている教材もRを使っています。確かにPythonでも同じことはできるのですが、同じことがRではとてもシンプルにできるように作られています。データサイエンスはほぼ統計分析ですから、Rの使い手もとても多いです。
ではJuliaを使ってどこまでできるかやってみようと思い書いてみます。Julia環境でPythonやRも使えるならJuliaをベースにした方が楽ですからね。
基本的にはスタンフォード大の公開講座で使われている「An Introduction to Statistical Learning with Applications in R」という本とコードをもとにしています。無料でダウンロードできますし、データサイエンスの上でも必読書ではないでしょうか。
Python同様にRもJuliaから読み込んで実行可能です。まずはRCall.jlをインストールしましょう。
import Pkg; Pkg.add("RCall")でRを実行できるようにしましょう。
RのDatasetsも使うので一緒にインストールするといいと思います
import Pkg; Pkg.add(["RCall","RDatasets"])REPL上でドルサイン$をタイプするとRモードに切り替わります
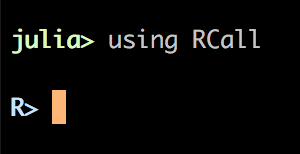
これが確認できればOKです。データも使えるか試してみましょう
using RDatasets
RDatasets.packages()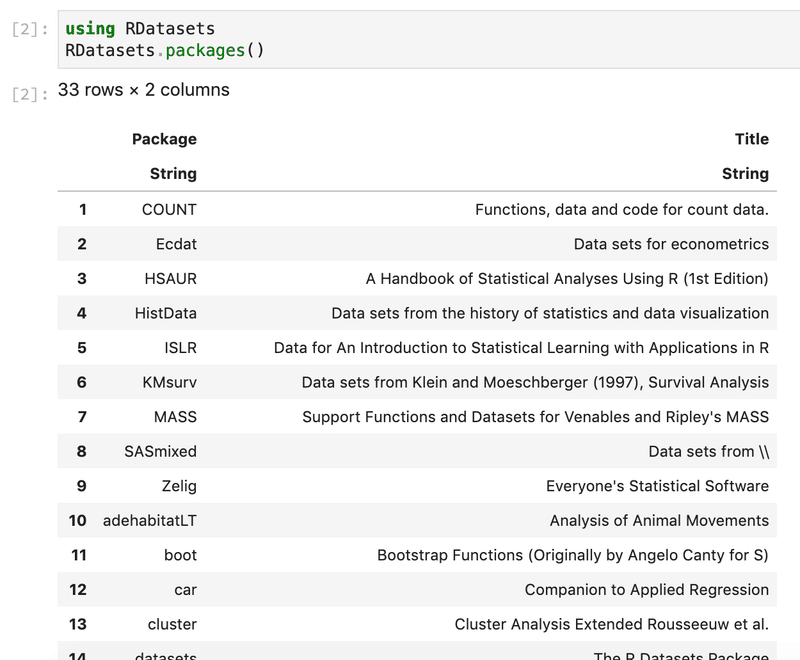
一応私のJulia環境はこんな感じです。
では本のLABセクションに沿ってRのコードをJuliaで置き換えて実行する場合を書いていきます。
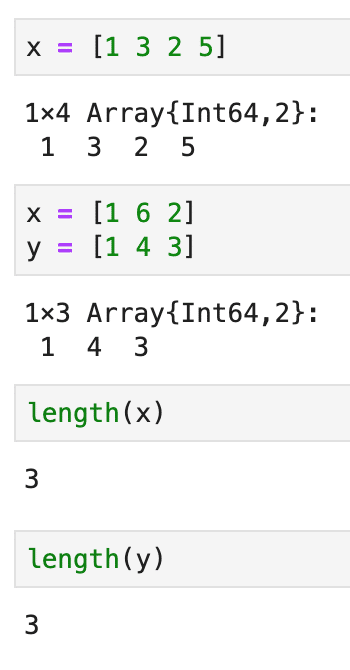
この辺は全く問題ないと思います。ただlsとかpwdといったコマンドラインに似たものはないです。Juliaではセミコロン;をタイプすればコマンドモードに切り替わりlsやpwdが実行できるので分けて考えたほうがいいんでしょう。変数の情報を見る場合は
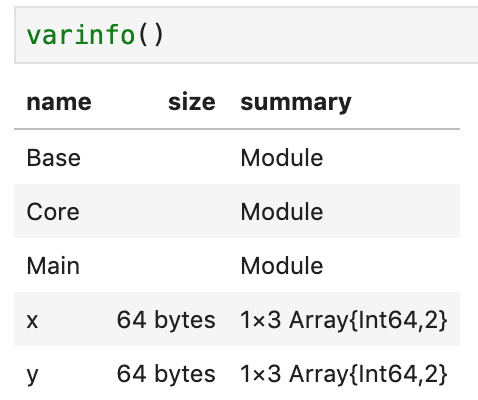
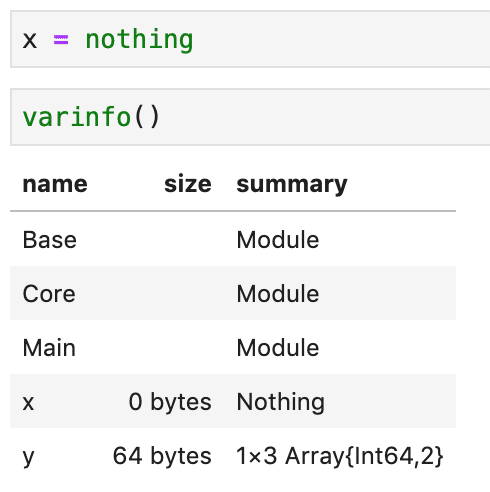
Rのrm()のように変数を削除する方法があるのかどうかはわかりませんでした。まあnothingとしました、現時点では。
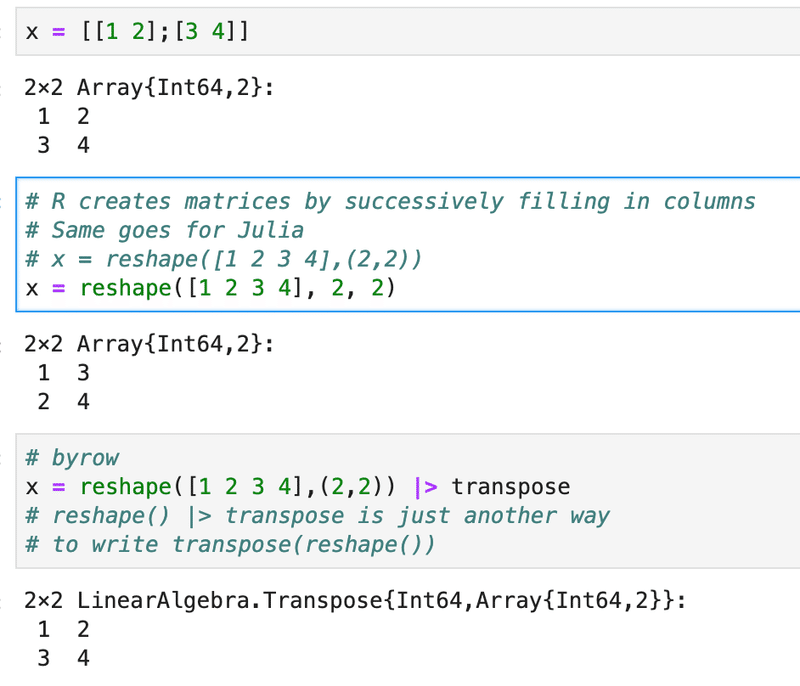
2x2行列をつくる方法ですがカンマを使うか、スペースを使うかで変わってくるので注意が必要です。
Julia & Pythonの所でも書きましたが行列のエレメントごとの計算にはピリオドを使います。

次はJulia Runtime環境下からRのコードを実行する場合です。

本当にそのまんまが実行できます。Rの統計学に関するライブラリは素晴らしくそれを利用しない手はありません。PythonよりRのほうが1から始まるインデックス、列でなく行ベースといった相似点からも変数の受け渡しがとてもスムーズに感じます。ぜひ使ってみてください。
仮にJuliaだけで実行する場合はDistirubtionsというパッケージを利用します。rnorm()と同じ事をする場合はNormal()関数が必要です。

数字が異なるのはランダムで作られた数字が異なるからです。Juliaでもseedは使えるので同じランダム数を作成する場合はRandom.seed!()を使います。その他の関数は一緒です。

次回は基本的なチャートを紹介します。
この記事が気に入ったらサポートをしてみませんか?