とりあえずクラスタリングしたくなった時に試すコード

よくわからないデータを見ると何も考えずクラスタリングして特徴を読み取ろうとする思考停止人間です。
せっかくなら手も動かしたくないのでコピペコード作ってみました。
内容
k-means法を使用し、非階層クラスタリングを実施
クラスター数はエルボー法を使用して、何となくよさそうな数を決定
クラスタリングの性能評価関数の一つ、SSE(クラスタ内誤差平方和)値を「Distortion」として表示
仕事したかのようなグラフを表示
コードの参考:SSEとエルボー法
コード
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# データセットの作成
# クラスター数を指定した分だけデータ内でクラスターが生成出来るmake_blobsを使う
X, Y = make_blobs(n_samples=250, # サンプル点の総数
n_features=2, # 特徴量(次元数)の指定 default:2
centers=8, # クラスタの個数
cluster_std=.8, # クラスタ内の標準偏差
shuffle=True, # サンプルをシャッフル
random_state=42) # 乱数生成器の状態を指定
'''
エルボー法の実施
'''
distortions = []
best_clusters = 0
for i in range(1, 11): # クラスター数1~10を一気に計算
km = KMeans(n_clusters=i,
init="k-means++", # k-means++法によりクラスタ中心を選択
n_init=10,
max_iter=300,
random_state=0)
km.fit(X) # クラスタリングのを実行
distortions.append(km.inertia_) # km.fitするとkm.inertia_が得られる
# 良さげなクラスタ数を格納
for i in range(2, 11):
if((distortions[i-1] - distortions[i]) < 100):
best_clusters = i
break
# グラフのプロット
plt.plot(range(1, 11), distortions, marker="o")
plt.xticks(np.arange(1, 11, 1))
plt.xlabel("Number of clusters")
plt.ylabel("Distortion")
plt.show()
print("ベストクラスタ数 ", best_clusters)
'''
k-mean法の実装
'''
# KMeansクラスからkmインスタンスを作成
km = KMeans(n_clusters=best_clusters, # エルボー法で求めたベストクラスターの個数
init="k-means++", # セントロイドの初期値をk-means++法によりクラスタ中心を選択
n_init=1, # 異なるセントロイドの初期値を用いたk-meansの実行回数
max_iter=300, # k-meansアルゴリズムを繰り返す最大回数
tol=1e-04, # 収束と判定するための相対的な許容誤差
random_state=42) # 乱数発生初期化
# fit_predictメソッドによりクラスタリングを行う
km_pred = km.fit_predict(X)
# SSE値を出力
print("Distortion: ", km.inertia_)
# プロット
for n in range(np.max(km_pred)+1):
plt.scatter(X[km_pred == n, 0], X[km_pred == n, 1], s=25, c=cm.hsv(
float(n) / 10), marker="o", label="cluster"+str(n+1))
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[
:, 1], s=100, marker="*", c="black", label="centroids")
plt.legend(bbox_to_anchor=(1.05, 0.7), loc="upper left")
plt.grid()
plt.show()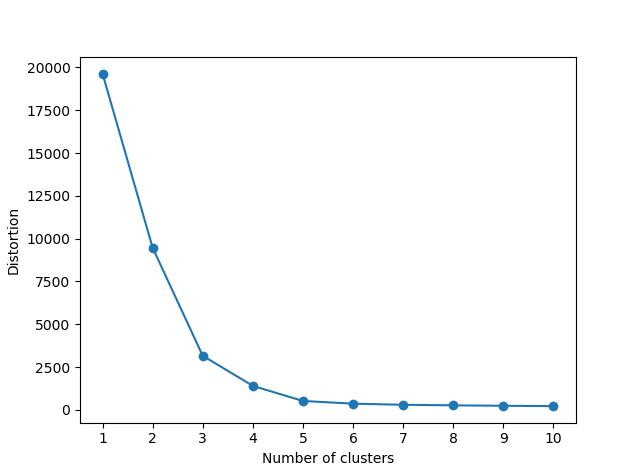
ベストクラスタ数 6
Distortion: 363.17333951246775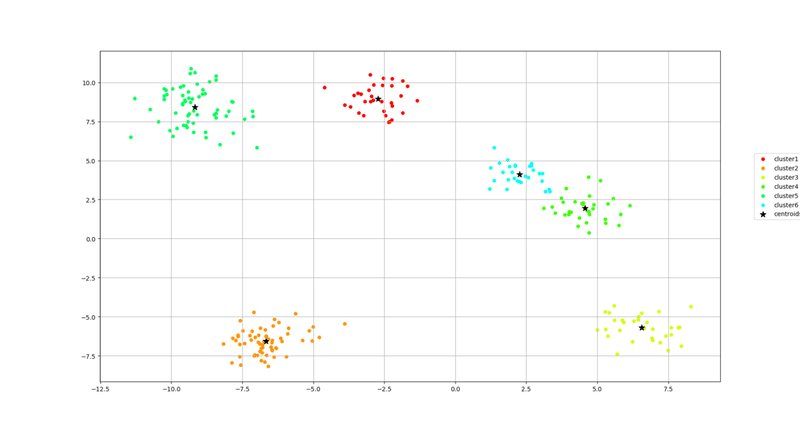
ただ散布図作るより価値があればよいのです。と言い聞かせる。
この記事が気に入ったらサポートをしてみませんか?