
物体認識モデルYOLOv3に完全勝利したM2Detの紹介

はじめに
一般物体認識はここ数年で大きな進化を遂げました。その中でも実用的に使いやすい&よく使われている(気がする)のはYOLO v3だと思います。それは、ある程度の予測精度を持ちながら推論速度もはやいというモデルになっているためです。
今回説明するのはそのYOLOv3に対して、予測精度も推論速度も上回るようなモデルのM2Detです。予測精度と推論速度はトレードオフはありますが、どちらをとっても、下記の図のように他のモデルに優位性があることが分かります。
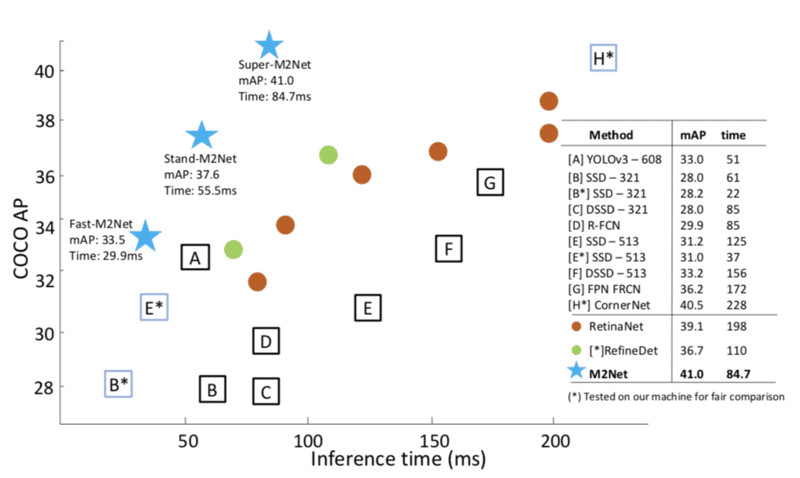
M2DetはAAAI2019に採録された論文のモデルでこれから使われる機会も増えるのではないかと思います。YOLOv3は著者実装や様々なフレームワークの実装、そして学習済みのモデルまで公開されていて非常に使いやすくなっていますが、M2Detも著者実装、学銃済みモデルの公開が予定されていて、公開されれば利用が増えると思います。公開予定のレポジトリ→qijiezhao/M2Det。2019/04/01には一通り公開される予定になっています。
全体像
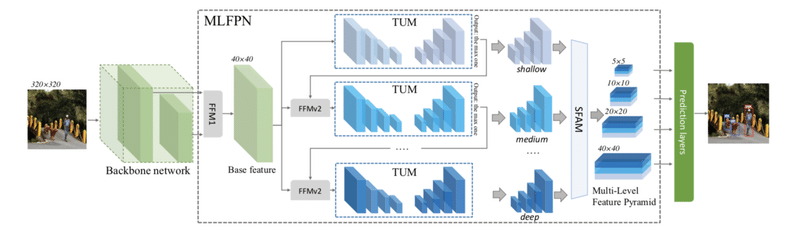
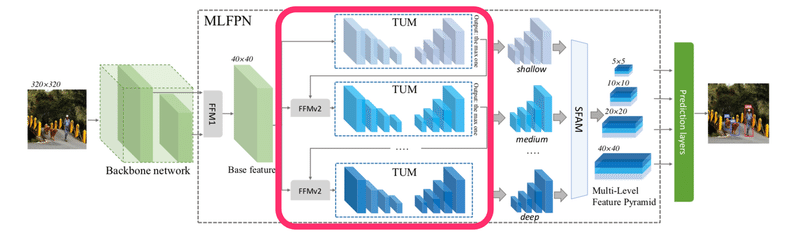
全体像は以下の図のようになっています。基本的には物体認識では一般的なモデルであるSSDの拡張であり、ネットワークの構造を物体認識に適する形に変更し、各スケールの特徴マップを利用できるようなピラミッドの構造を導入しています。以下ではネットワークの順に「Backbone networkとFFM1」、「TUMとFFMv2」、「SFAM」を説明していきます。
Backbone networkとFFM1
まず、以下の赤枠のBackbone networkとFeature Fusion Modules(FFM)1について説明します。
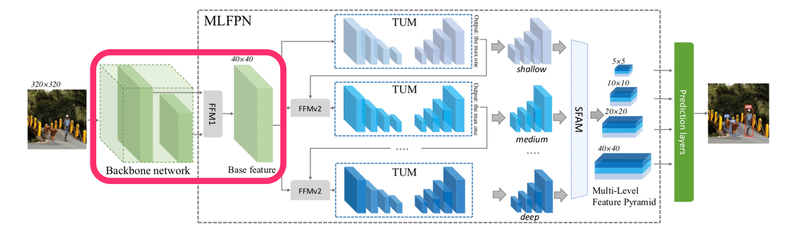
Backbone networkは特徴抽出器にあたり、ここではVGGの学習済みモデルを使います。その中のネットワーク中の2層(conv4_3、conv5_3)の特徴マップを使用します。この2層をFFM1によって結合処理を行い、Base featureとします。この特徴マップがモデル内のベースとなる特徴量になります。
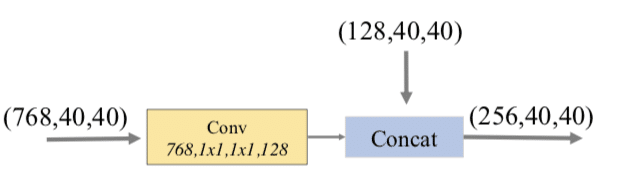
FFM1は以下のような構成になっています。それぞれの層を畳み込み層に通した後に、小さいサイズの特徴マップにUpsamleを行い、Concatします。
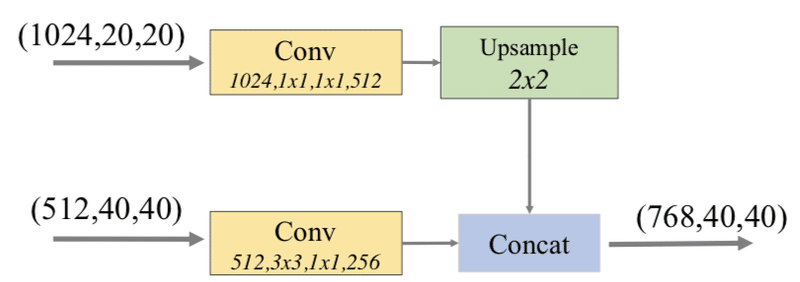
この出力がBase featureになり、続くTUMで利用されます。
TUMとFFMv2
次に、Thinned U-shape Modules(TUM)とFFMv2について説明します。以下の赤枠にあたります。
TUMは以下のような構成になっています。各TUMは複数の特徴マップを出力します。(図では6つの特徴マップを出力)
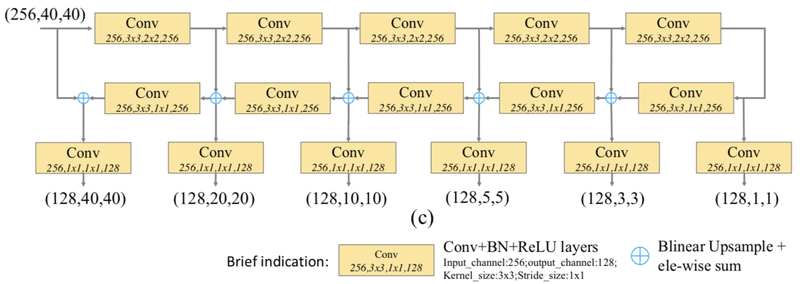
この構造はFPN(Feature Pyramid Networks for Object Detection)のFeature Pyramid構造をヒントにしていると思います。そして、このモデルのポイントはスケールの異なる特徴マップを足し合わせる構造になっていることとそのブロックを多段に積み重ねることにあると思います。筆者によると、これまでのFeature Pyramid構造の問題点として、①クラス分類で学習したBackbone networkに依存が大きく物体認識のタスクのための特徴が表現されていないことと②一つのレイヤーからの情報に依存していて他のレベルのレイヤーの情報が生かしきれていないこと、が挙げられています。異なるスケールの特徴マップを足し合わせ、ネットワークを多段に積み重ねることによって、物体認識のタスクに十分な表現を学習でき、さらに、マルチレベルの情報を認識に利用されるようになります。
FFMv2はTUMのつなぎに利用されていて、直前のTUMのサイズの最大の特徴マップ(40x40)とBase featureをconcatして新たなTUMの入力とします。
各TUMの特徴マップが次のSFAMで使用されます。
SFAM
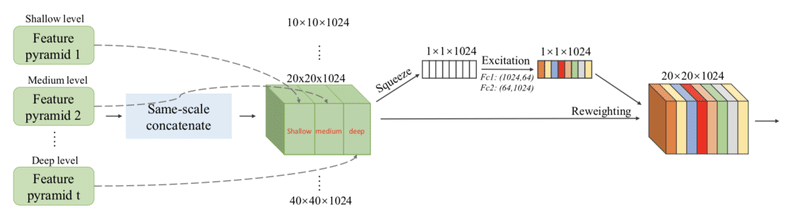
そして次のScale-wise Feature Aggregation Module(SFAM)が以下の赤枠にあたります。
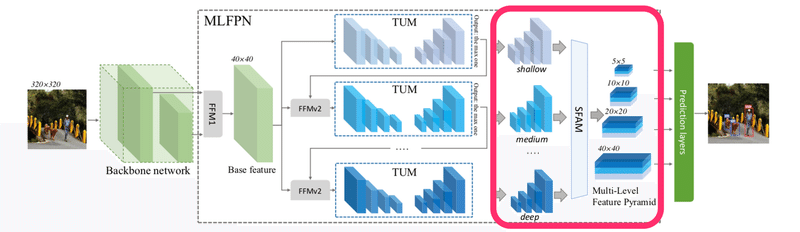
SFAMは各TUMの出力の特徴マップをサイズごとにconcatし、それにSE blockを使ったattentionの機構を取り入れています。ただ、concatするだけでは不十分だったということです。下記の図のような手順となります。
考察
この考察は私的な考察となります。M2Detは一見複雑そうには見えますが、発想としては納得感があるものだと思います。以下の図の上がSSDで下がDSSD(Deconvolution SSD)です。DSSDのSSDからの改良としてはDeconvolution層が付いたことですが、これによって出力の赤い層は各青い層の情報を加味できるようになっています。M2Detはこの青と赤の層の構造を改良し、それを多段に積み上げたものと解釈できます。
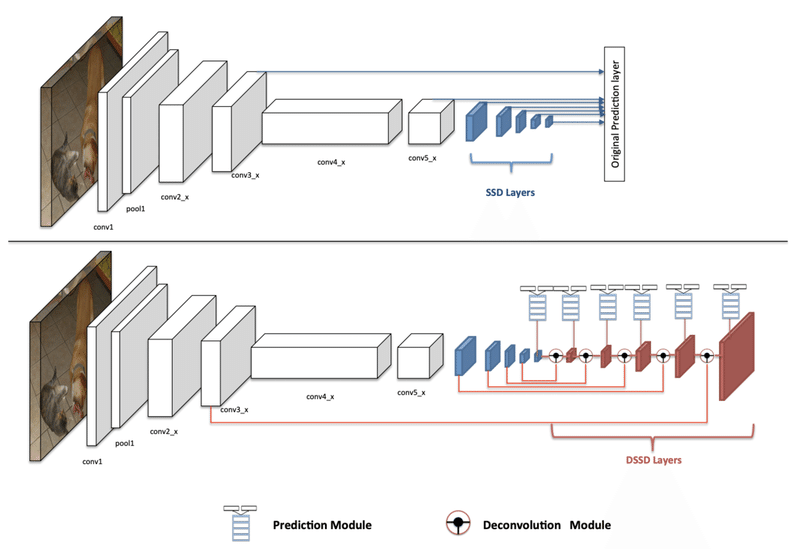
図参照: DSSD : Deconvolutional Single Shot Detector
以下はAblation studyの精度比較で、1列目がDSSDとなっています。s-TUMとはTUMの出力の1x1 Convがないものです。DSSDのDeconvの構造をs-TUMに変えたものが2列目、それを8個積み上げたのが3列目、s-TUMをTUMに変えたのが4列目、あとは提案手法のBase feature、SFAMの有無、BackBornのモデルの変更で比較されています。
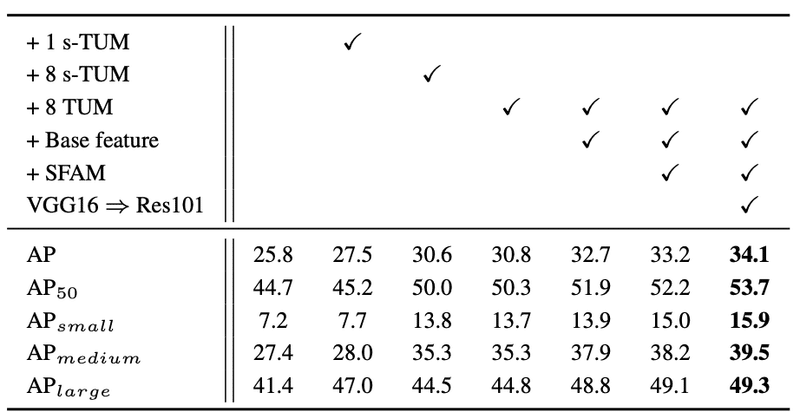
提案手法の各モジュールが有効に機能していることが分かります。
まとめ
今回はYOLOv3より高性能な新しく提案された物体認識のモデルであるM2Detについて解説しました。実装や学習済みモデルの公開も予定されているので、是非使ってみたいですね。
最後に
私が所属している株式会社ACESでは、Deep Learningを用いた画像認識技術を中心に、APIによるアルゴリズムパッケージの提供や、共同研究開発を行なっています。特に、ヒトの認識・解析に強みを持って研究開発を行っておりますので、ご興味のある方は、ぜひお問い合わせください!
【詳細・お問い合わせはこちら】 acesinc.co.jp sharon.jp
◆画像認識アルゴリズム「SHARON」について
ヒトの行動や感情の認識、モノの検知などを実現する画像認識アルゴリズムを開発しています。スポーツにおけるパフォーマンス分析やマーケティングにおけるヒトの心の動きの可視化、ストレスなどの可視化による健康状態の管理を始めとするAIアルゴリズムを提供しています。
この記事が気に入ったらサポートをしてみませんか?