
Pythonでコースデータの整理
小回り適性を測る指標として、以下の記事で直線距離の扱いを紹介しましたがそのデータ作成のプロセスを記します。
コースデータを整理
コースデータを整理したものを一度整理しておくと、種牡馬や個別の馬など、あらゆる成績データと結合して分析に使えます。
ツール:TargetとPython
1.データの取り込み
Targetから障害を除く全てのレースについて1着馬に限定して取得します。
データ範囲を広げれば、たくさんのコースが取得できますが、今回は中京コースの改修後の2011年~2020年に限定します。
import pandas as pd
crs = pd.read_csv('course_data_2011to2020.csv')
crs.head(10)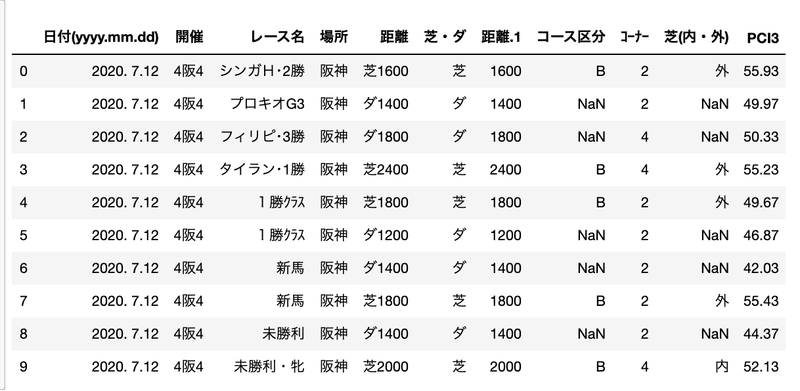
ここからさらにデータを整えていきましょう。
2.データの整形
crs['コース区分'].fillna('なし', inplace=True)
crs['芝(内・外)'].fillna('なし', inplace=True)
crs['place_sur_long'] = crs['場所'] + crs['距離'] \
+ crs['コース区分'] + crs['芝(内・外)']
crs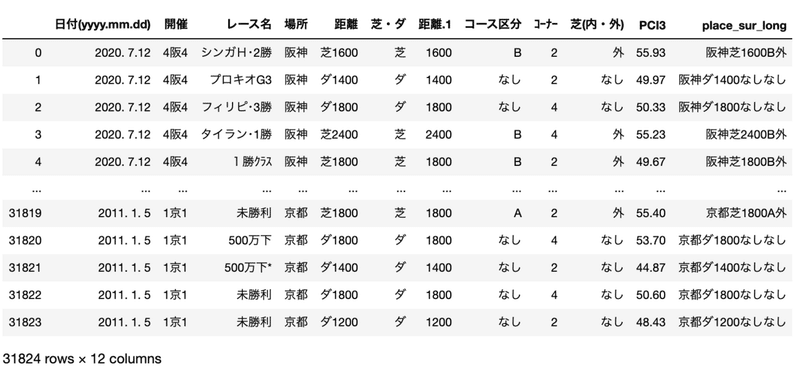
欠損値があると後々面倒なので「なし」で埋めておきます。
また芝コースの直線距離については、京都などはAコースとBコースで直線距離が異なるので、場所、距離、コース区分、芝(内・外)をキーとしてコースIDを作ります。(ここではplace_sur_longの列です)
コースのパターンがいくつあるか確認しておきましょう。
#コースの重複列を削除
crs = crs[~crs.duplicated(subset='place_sur_long')]
crs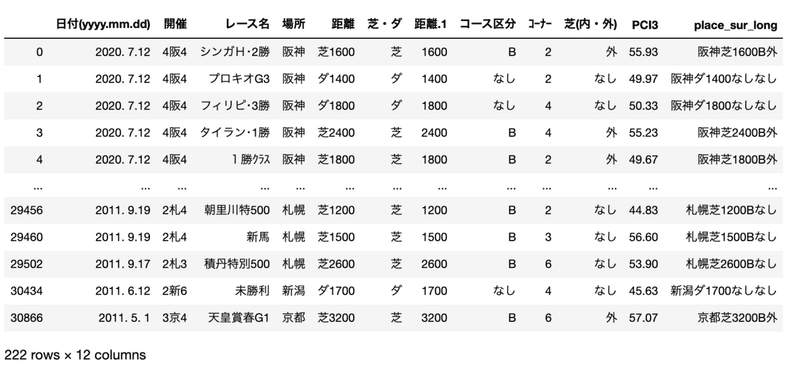
この期間では222パターンのコース設定があるようです。
3.コースの特徴の追加
tmp = crs.copy()として以下では処理しています。
まずは直線距離のデータを追加します。
#直線距離を追加
#中山
tmp.loc[tmp['place_sur_long'].str.contains('中山芝'), '直線距離'] = 310
tmp.loc[tmp['place_sur_long'].str.contains('中山ダ'), '直線距離'] = 308
#東京
tmp.loc[tmp['place_sur_long'].str.contains('東京芝'), '直線距離'] = 525.9
tmp.loc[tmp['place_sur_long'].str.contains('東京ダ'), '直線距離'] = 501.6
#札幌
tmp.loc[(tmp['place_sur_long'].str.contains('札幌芝')) & (tmp['コース区分'] =='A') , '直線距離'] = 266.1
tmp.loc[(tmp['place_sur_long'].str.contains('札幌芝')) & (tmp['コース区分'] =='B') , '直線距離'] = 267.6
tmp.loc[(tmp['place_sur_long'].str.contains('札幌芝')) & (tmp['コース区分'] =='C') , '直線距離'] = 269.1
tmp.loc[tmp['place_sur_long'].str.contains('札幌ダ'), '直線距離'] = 264
#函館
tmp.loc[(tmp['place_sur_long'].str.contains('函館芝')) & (tmp['コース区分'] =='A') , '直線距離'] = 262.1
tmp.loc[(tmp['place_sur_long'].str.contains('函館芝')) & (tmp['コース区分'] =='B') , '直線距離'] = 262.1
tmp.loc[(tmp['place_sur_long'].str.contains('函館芝')) & (tmp['コース区分'] =='C') , '直線距離'] = 264.5
tmp.loc[tmp['place_sur_long'].str.contains('函館ダ'), '直線距離'] = 260.3
#福島
tmp.loc[(tmp['place_sur_long'].str.contains('福島芝')) & (tmp['コース区分'] =='A') , '直線距離'] = 292.0
tmp.loc[(tmp['place_sur_long'].str.contains('福島芝')) & (tmp['コース区分'] =='B') , '直線距離'] = 297.5
tmp.loc[(tmp['place_sur_long'].str.contains('福島芝')) & (tmp['コース区分'] =='C') , '直線距離'] = 299.7
tmp.loc[tmp['place_sur_long'].str.contains('福島ダ'), '直線距離'] = 295.7
#新潟
tmp.loc[tmp['place_sur_long'].str.contains('新潟ダ'), '直線距離'] = 354
tmp.loc[tmp['place_sur_long'].str.contains('新潟芝') & (tmp['芝(内・外)'] =='内') , '直線距離'] = 358.7
tmp.loc[tmp['place_sur_long'].str.contains('新潟芝') & (tmp['芝(内・外)'] =='外') , '直線距離'] = 658.7
tmp.loc[tmp['place_sur_long'].str.contains('新潟芝1000') , '直線距離'] = 1000 #1行目とかぶるのでこれを最後に書くことでクリア
#中京
tmp.loc[tmp['place_sur_long'].str.contains('中京芝'), '直線距離'] = 412.5
tmp.loc[tmp['place_sur_long'].str.contains('中京ダ'), '直線距離'] = 410.7
#京都
tmp.loc[(tmp['place_sur_long'].str.contains('京都芝')) & (tmp['コース区分'] =='A') & (tmp['芝(内・外)'] =='内'), '直線距離'] = 328.4
tmp.loc[(tmp['place_sur_long'].str.contains('京都芝')) & (tmp['コース区分'] !='A') & (tmp['芝(内・外)'] =='内'), '直線距離'] = 323.4
tmp.loc[(tmp['place_sur_long'].str.contains('京都芝')) & (tmp['コース区分'] =='A') & (tmp['芝(内・外)'] =='外'), '直線距離'] = 403.7
tmp.loc[(tmp['place_sur_long'].str.contains('京都芝')) & (tmp['コース区分'] !='A') & (tmp['芝(内・外)'] =='外'), '直線距離'] = 398.7
tmp.loc[tmp['place_sur_long'].str.contains('京都ダ'), '直線距離'] = 329.1
#小倉
tmp.loc[tmp['place_sur_long'].str.contains('小倉芝'), '直線距離'] = 293
tmp.loc[tmp['place_sur_long'].str.contains('小倉ダ'), '直線距離'] = 291.3
#阪神
tmp.loc[(tmp['place_sur_long'].str.contains('阪神芝')) & (tmp['コース区分'] =='A') & (tmp['芝(内・外)'] =='内'), '直線距離'] = 356.5
tmp.loc[(tmp['place_sur_long'].str.contains('阪神芝')) & (tmp['コース区分'] =='B') & (tmp['芝(内・外)'] =='内'), '直線距離'] = 359.1
tmp.loc[(tmp['place_sur_long'].str.contains('阪神芝')) & (tmp['コース区分'] =='A') & (tmp['芝(内・外)'] =='外'), '直線距離'] = 473.6
tmp.loc[(tmp['place_sur_long'].str.contains('阪神芝')) & (tmp['コース区分'] =='B') & (tmp['芝(内・外)'] =='外'), '直線距離'] = 476.3
tmp.loc[tmp['place_sur_long'].str.contains('阪神ダ'), '直線距離'] = 352.7長いですが要は直線距離を条件ごとに加えているだけです。ここはアナログ作業ですので要注意。
次にダートコースのスタートが芝かダートかについての情報を加えます。
#芝スタートに1('新潟ダ1200', '東京ダ1600','中山ダ1200','中京ダ1400','京都ダ1400','阪神ダ1400','阪神ダ2000')、ダートスタートに0をつける
tmp['ダートスタート(芝・ダ)'] = 0
tmp.loc[(tmp['place_sur_long'] == '福島ダ1150なしなし') | (tmp['place_sur_long'] == '新潟ダ1200なしなし') | (tmp['place_sur_long'] == '東京ダ1600なしなし') | (tmp['place_sur_long'] == '中山ダ1200なしなし') |\
(tmp['place_sur_long'] == '中京ダ1400なしなし' )| (tmp['place_sur_long'] =='京都ダ1400なしなし') | (tmp['place_sur_long'] =='阪神ダ1400なしなし') | (tmp['place_sur_long'] =='阪神ダ2000なしなし') , 'ダートスタート(芝・ダ)'] = 1ここは特に問題ないでしょう。
右周り・左周りも加えましょう。
#左右周りを追記 左を1とする
tmp['左右'] = 0
tmp.loc[(tmp['場所'] == '新潟') | (tmp['場所'] == '東京') | (tmp['場所'] == '中京'), '左右'] = 1本当は1コーナーまでの距離なども追加してもいいでしょう。
平均ペースなどいくらでも応用は効くと思います。
ここまでのデータを確認しましょう。
#必要な列に限定
tmp = tmp[['place_sur_long','場所', '芝・ダ', '距離.1', 'コース区分', '芝(内・外)','直線距離','コーナー', 'ダートスタート(芝・ダ)', '左右']]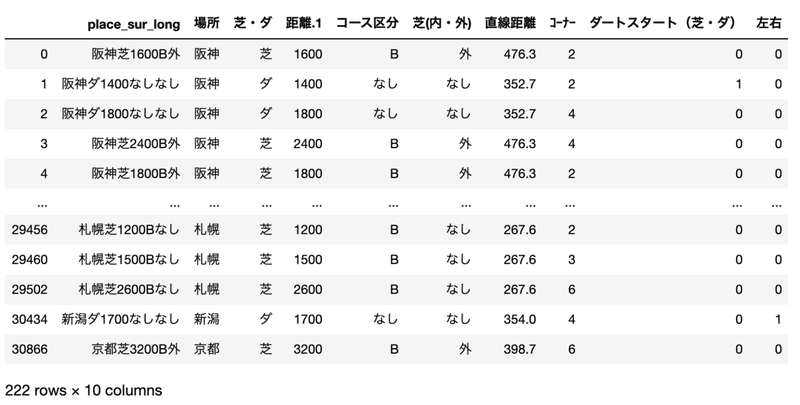
これで一応はコースデータの作成は完了です。
このコースデータを作っておくと、以下のように成績データとコースデータを結合して活用できます。
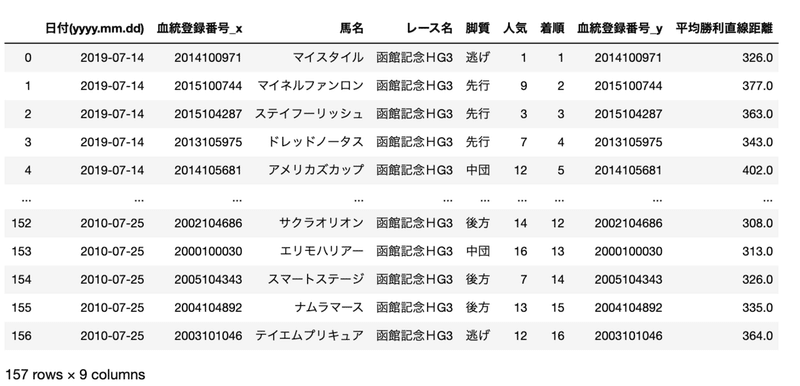
不明な点や改善すべき点があればコメントからお願いします。
今後の記事ではこのコースデータを活用したものをどんどん発信していくのでお楽しみに!吉田しげるでした。
この記事が気に入ったらサポートをしてみませんか?