
[テンプレ有] ChatGPT✖️医療の研究①応急措置は使えそうかも

【注意】前提として、医者が絶対です。ChatGPTはプライドの高い嘘つきです。あくまで参考程度に。存在しない薬や、病気を平気でいいます。
結論
使えるところ
【医者に行けない時に、応急措置の方法を聞く】
そのテンプレ
あなたの専門的役割:
あなたは医者として振る舞ってください。
あなたに解決してほしい問題:
{症状}が出ていますが、すぐに病院に行けません。
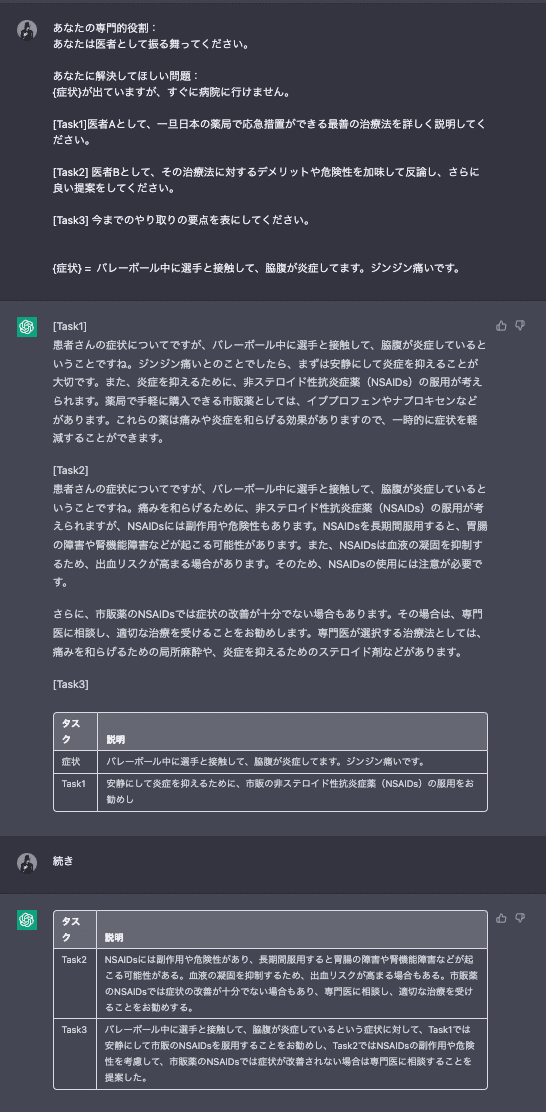
[Task1]医者Aとして、一旦日本の薬局で応急措置ができる最善の治療法を詳しく説明してください。
[Task2] 医者Bとして、その治療法に対するデメリットや危険性を加味して反論し、さらに良い提案をしてください。
[Task3] 今までのやり取りの要点を表にしてください。
{症状} = バレーボール中に選手と接触して、脇腹が炎症してます。ジンジン痛いです。これの結果
より良い使い方
1 症状はできるだけ詳しく書く。これでもかというぐらい書いても良い
2 念の為複数回同じ質問をする
Tiktok動画解説
実験過程と結果
・この聞き方は失敗

・振る舞ってくださいがマスト

・不足情報は聞いてくれる
・特に詳しい命令なくても、ある程度のこと教えてくれる
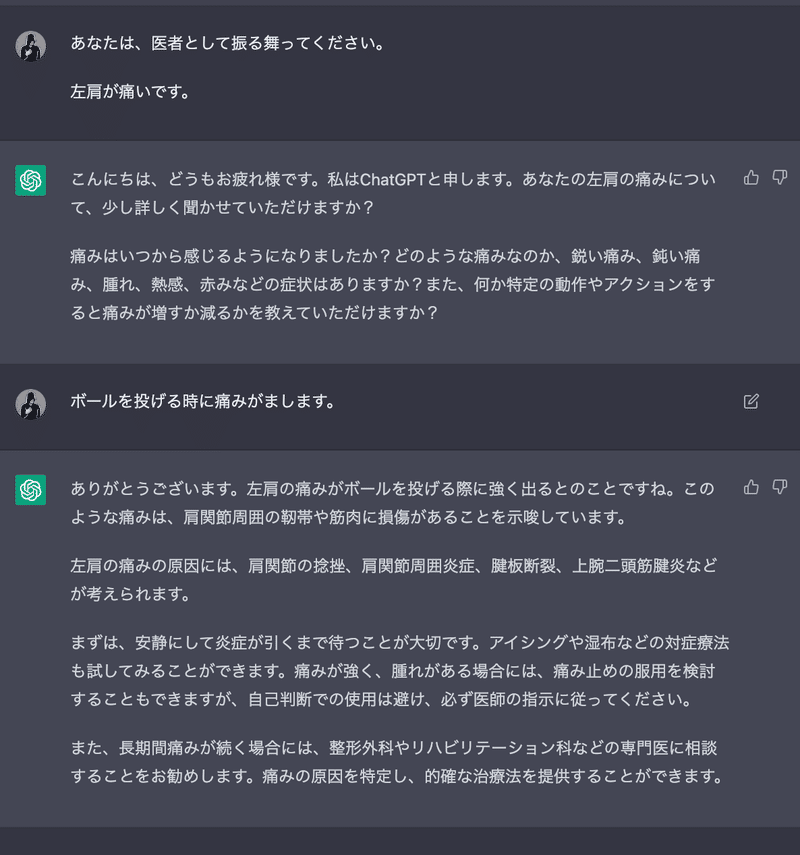
・医者に見せにくいことを一旦聞く

・こちらの具体性を増すと、処置も具体的にしてくれる

・応急措置のときは、
病院に行くつもりですが、一旦日本の薬局で応急措置ができる最善の治療法を教えてください。
と付け加えると、詳しい内容を教えてくれる。
これはおそらく医者を推奨するよーという前提が要らなくなった尺の関係も大きい


・上記をまとめてテンプレ化


これだと、もとから信用ならないにせよ、対策が0すぎると思った
✖️有効性を10段階で評価
何回か安定性がなし、逆に間違って10がでたら最悪だと思って没
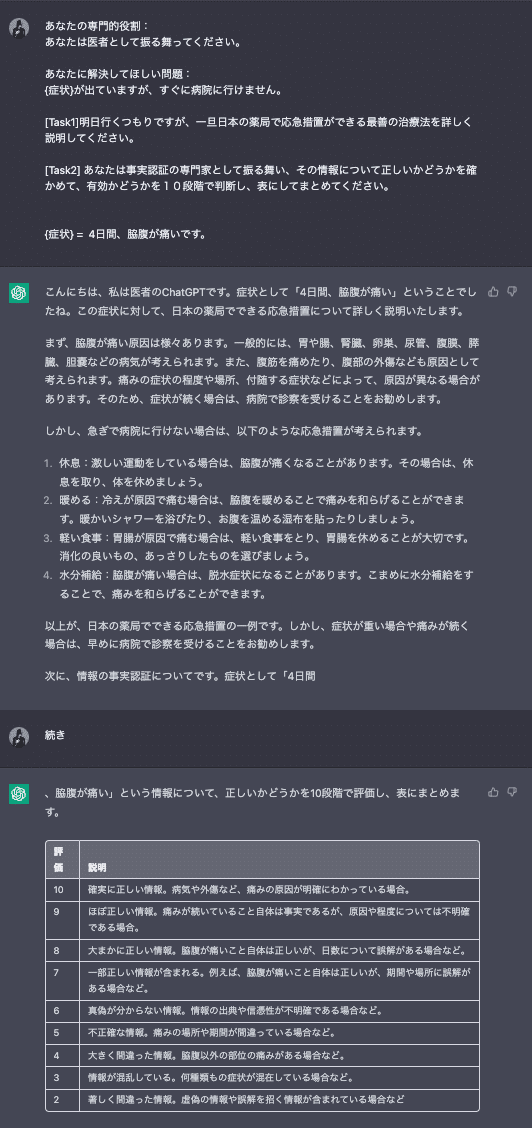

✖️科学的根拠に点数をつける
これも、安定しないし、逆に変な答えに自信つけられると怖いので没

○医者Aを医者Bに全否定させる。
もちろんファクトチェック必須だが、Aを全否定することで少しはマシになると思ったので、取り合えず現状ここでOKにしました。
これの重大な欠点を見つけた場合コメントください!
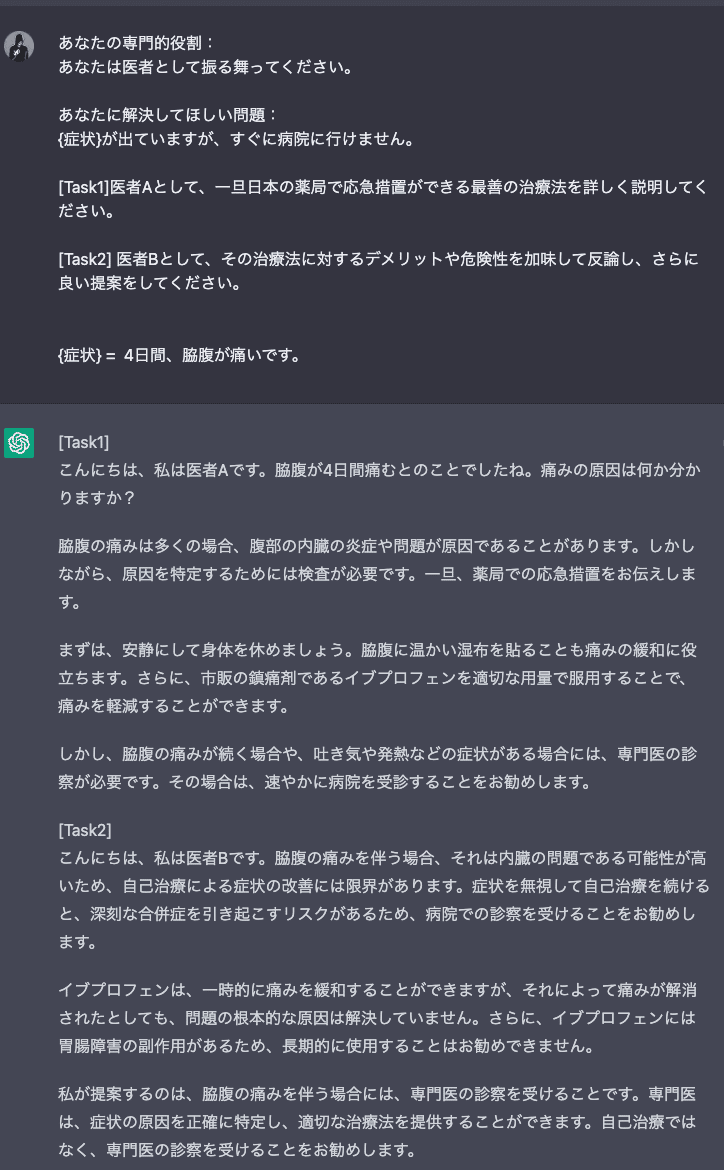
最後に見やすいように表をつける
表の形式は要改善だし、絶対にこれ以上はあります。
方向性は示したので、あとは後続に任せます!俺のやり方超えましたーってメンションツイートしてくれたらみますし、それ僕のTiktokで紹介して頑張ってフックアップします!
みんなでおもろいテンプレ作りましょー

まとめ
はい。ChatGPTを使って医療を改善する方法を探してみました
多くのやり方があると思いますが、応急処置的な意味では、チャットGPTを使うことは有用かもしれません。しかし、これ以上のやり方はもちろんあります。皆さんも是非挑戦してみてください。
ChatGPTに何かを評価させる方法はたまに使われますよね。
ChatGPTの回答そのものを、チャットGPTに評価させる方法です。
しかし、私が今述べたことからも分かるように、この評価方法は役に立たないと思います。安定性がなく、意味がないからです。特に医療の場合重大な欠点になるので、変に自信をつけさせる方が厄介です。
基本的に人間がすべきことを、評価基準がブラックボックスな状態でAIに評価させることは絶対に避けるべきだと思います。
ただし、クリエイティブな分野や専門家が不在の場合など、ChatGPTは非常に有用かもしれません。
将来的には、事実認証に特化したAIが登場する可能性があり、非常に有用なものになるでしょう。しかし、いつまでも医者が一番であり、AIは代替手段でしかないことを忘れてはいけません。医者自身が間違えることもあるため、AIを使用して医者の判断を確認することが必要な場合もあるでしょう。これらの仕組みは今後ますます重要になってくると思います。
このテンプレの今後の改善点
・症状を深掘りしてくれるテンプレを先に作っとくと良い気がします。
ChatGPTについてみんなで話す無料オプチャ↓
オープンチャット「日本ChatGPT研究所ノーベル」
https://line.me/ti/g2/0mYq4TMNPCMdZ7FPkrFsQD4W8-b6-11Qoe3svw?utm_source=invitation&utm_medium=link_copy&utm_campaign=default
ChatGPTの使い方についてのTiktokもやってます。
@sugiruuuhanashi まだリリースされてませんが、されたら絶対動画にします!!!#ChatGPT #gpt3 #blender
♬ Vlog Video work Fashionable BGM(847726) - Tsuyoshi_san
追記 論文
こんなの出てました。
アブスト
大規模言語モデル(LLM)は、医療を含む様々な領域において、自然言語の理解や生成に顕著な能力を発揮している。我々は、最先端のLLMであるGPT-4を、医療能力試験とベンチマークデータセットで包括的に評価した結果を発表する。GPT-4は、トレーニングによって医療問題に特化したものではなく、臨床課題を解決するために設計されたものでもない、汎用的なモデルである。我々の分析は、米国で臨床能力を評価し免許を付与するために使用される3段階の試験プログラムである米国医師免許試験(USMLE)の公式練習教材2セットをカバーしています。また、ベンチマークデータセットであるMultiMedQAシリーズでの性能も評価しました。モデルの性能を測定するだけでなく、テキストと画像の両方を含む試験問題がモデルの性能に与える影響を調査し、トレーニング中のコンテンツの記憶について調べ、医学のような利害関係の強いアプリケーションで極めて重要な確率のキャリブレーションを研究するための実験を行いました。その結果、GPT-4は、特殊なプロンプトを作成することなく、USMLEの合格点を20点以上上回り、初期の汎用モデル(GPT-3.5)や、医学知識に特化して微調整されたモデル(Flan-PaLM 540Bのプロンプト調整版Med-PaLM)よりも優れていることが分かりました。また、GPT-4はGPT-3.5よりも大幅にキャリブレーションが向上しており、正解率の予測能力が大幅に向上していることがわかります。さらに、GPT-4が医学的推論を説明する能力、学生への説明をパーソナライズする能力、医学的ケースにまつわる新しい反事実シナリオをインタラクティブに作成する能力を示すケーススタディを提示することにより、モデルの挙動を定性的に探求しています。また、GPT-4の医学教育、評価、臨床での活用の可能性について、正確性と安全性の課題に適切に配慮しつつ、この知見の意義を議論する。
この記事が気に入ったらサポートをしてみませんか?