
クラウドファンディングの成功率を高める方法を機械学習で検証(Makuake編)

以前の記事「累計調達額100億円、クラウドファンディング マクアケの動向データ」でクラウドファンディングサービスMakuake(マクアケ)の全体動向をWebサイトデータをもとに分析してみました。
今回はマクアケに掲載されているプロジェクトにフォーカスして、以前と同じデータをもとに、成功 or 失敗するプロジェクトを機械学習を使って、予測・分析・考察してみたいと思います。
目標額達成・未達成を予測する機械学習(決定木)の方法
目標額達成 or 未達成となるプロジェクトを予測するために、今回、特徴量としては設定目標額、支援金単価(最小額、平均値、中央値)、プロジェクトのカテゴリ、支援者数を使います。
機械学習のアルゴリズムは、予測精度の点では大きな期待はできませんが、可視化や考察がしやすいという点で決定木にしました。
マクアケのWebサイトから収集した6080件のプロジェクト実績データをトレーニングデータとテストデータに分け、トレーニングデータを使って機械学習させ、テストデータでその機械学習の精度を評価しました。
6080件のプロジェクトのうち、目標額に到達して成功したプロジェクトが3415件(56.2%)、失敗したプロジェクトが2665件(43.8%)という内訳になっていて、比率としてはおよそ半々のサンプルデータとなっていました。
1st try プロジェクト目標額と支援金単価で機械学習

1回目の試みとして、設定する目標額と支援金単価のみを使って機械学習させます。
これらの特徴量はクラウドファンディングを始める前に設定する項目であるため、もしこれらの特徴量のみで目標額達成 or 未達成を精度よく予測することができれば、実際にファンディングを始める前に成功率・失敗率を見積もりやすくなります。
1st try 機械学習の結果

機械学習(決定木)の予測精度評価値として、Accuracy score(正解率)、F1 score(適合率と再現率のバランス)、AUC(偽陽性率と真陽性率で囲む面積)を算出しました。これらの評価値が1に近いほど精度の高いモデルと言えます。
そして、各評価値はStratified K-Fold(層状K分割交差検証:今回は5分割に設定)によって計算した値の平均値を記載しています。
特徴量に目標額と支援金単価を使った1st tryでは、Acuuracy scoreが0.621となっており、あまり高い予測精度にはなりませんでした(今回のような成功か失敗かの2値分類ではランダムに半々に分けた時のAccuracy score=0.5が最低水準になります)。
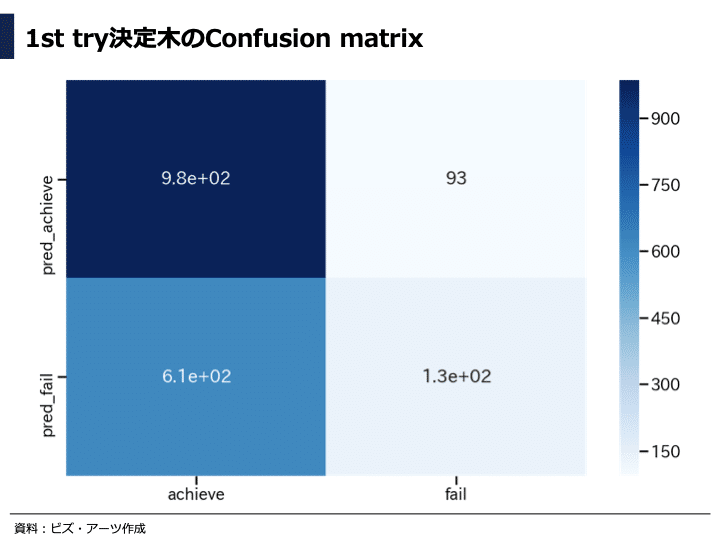
評価用のテストデータ(1824件)を用いてプロジェクト成功と失敗の予測結果(pred_achieve、pred_fail)と実際の結果(achieve、fail)を図示した混同行列(Confusion matrix)を示しました。
結果を見ると、成功と予測したプロジェクトが実際に成功していた件数(985件)は比較的多いですが、失敗と予測したプロジェクトが実際に成功していた件数(614件)も多く、あまり上手く分類できていないことが、この図からも分かります。
1st try 決定木の分類可視化
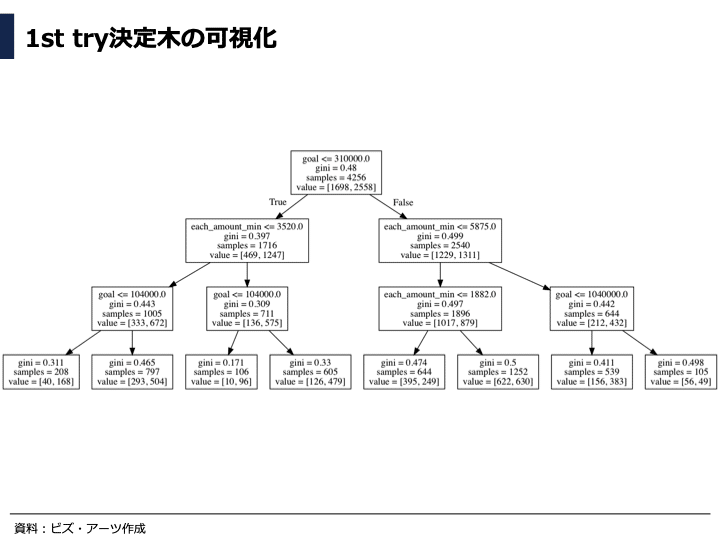
決定木アルゴリズムが、どのようにトレーニングデータを分類しているかを図示しました。
まず、目標額が31万円以下か31万円より大きいかで分けて、次に支援金の最小単価(each_amount_min)で更に分岐させていることが分かります。また、支援金単価の平均値や中央値は今回の分類では使用されていませんでした。
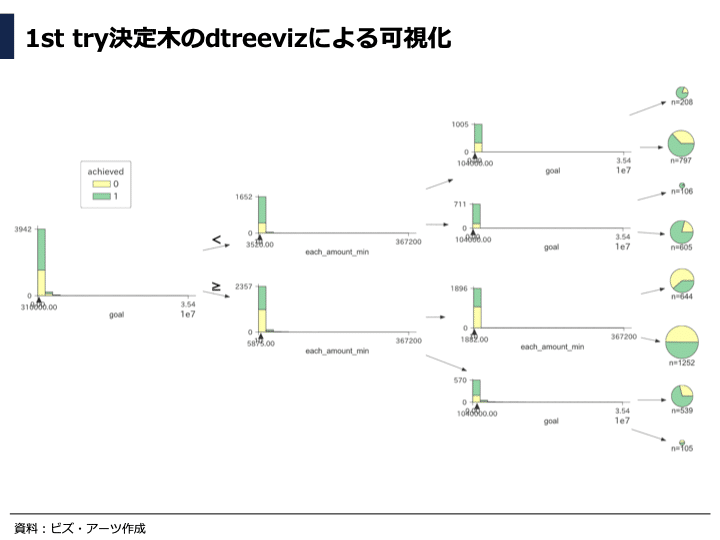
決定木の可視化ライブラリであるdtreevizを使って、先ほどの図をグラフ化しています。薄緑色が成功したプロジェクト、黄色が失敗したプロジェクトを示しており、決定木の分岐によって分類されている様子が視覚的に分かります。
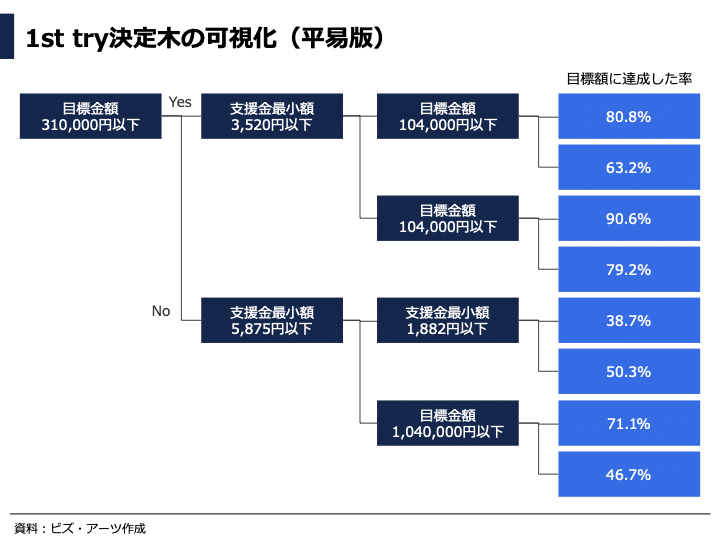
こちらの図は決定木の分類の様子をよりシンプルに示しました。
まず、目標金額が10万4000円以下の場合、支援金の最小額によらず、成功率は比較的高いことが分かります(支援金最小額が3520円以下の場合:80.8%、3520円よりも大きい場合:90.6%)。また、目標金額が10万4000円〜31万円においても、支援金最小額が3520円より大きい場合、成功率は79.2%と割と高い傾向がありました。
目標金額が低い場合であっても、支援金最小額が3520円以下の場合は、成功率が63.2%と少し低めになっていますが、これはプロジェクト規模が小さく、支援する事によるリターン(プロダクトやサービスなど)の魅力も低く、支援するメリットを感じにくいプロジェクトが多いためかもしれません。
一方、目標額が31万円よりも大きくなると、全体的に成功率が低下する傾向がありました(下4つ)。これは、目標額が高くなると、それだけ難易度が高くなりそうという一般的な感覚とも一致するのではないでしょうか。
しかし、この中でも目標額が31万円〜104万円のプロジェクトにおいて、支援金最小額が5875円よりも大きい場合は、成功率が71.1%で高くなっています。これは、先ほどとは逆にある程度高い額の支援金単価になると、支援者が得られるリターンも魅力的に映るものが増え、成功率がアップするのではないかと考えられます。
2nd try プロジェクト目標額・支援金単価・カテゴリで機械学習
次に2回目の試みとして、設定する目標額と支援金単価に加え、プロジェクトのカテゴリ(プロダクト、ファッション、フードなど)もダミー変数を使って追加し、機械学習させました。

結果としては、プロジェクトカテゴリの追加前後で、予測精度に大きな改善は見られませんでした。
カテゴリを単に特徴量として追加するのではなく、カテゴリごとの特徴量スケーリングや機械学習、決定木の深さ調整などによって精度を改善できるかもしれません。
3rd try プロジェクト目標額・支援金単価・支援者数で機械学習
最後に、目標額と支援金単価に加え、支援者数も含めて機械学習させました。
集まる支援者数は、クラウドファンディングを実際に開始してみないと分かりづらく、事前にプロジェクトの成功・失敗を予測する上では、少し使いにくい特徴量ですが、考察を得るためにも検証してみました。
3rt try 機械学習の結果

支援者数も特徴量に含めることで、評価値も大きく改善したことが分かります。
Accuracy score:追加前 0.621 → 追加後 0.849
F1 score:追加前 0.699 → 追加後 0.871
AUC:追加前 0.651 → 追加後 0.904
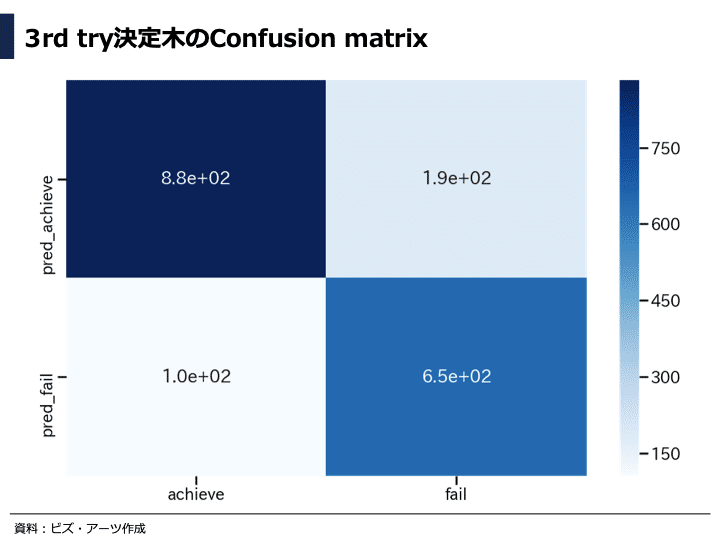
混同行列を見ると、1st tryでは失敗と予測したプロジェクトが実際は成功しているケースが多かったですが、支援者数も特徴量に加えた3rd tryでは失敗と予測したプロジェクトが実際は成功しているケースが大きく減少して、予測精度が上がっていることが分かります(実際に失敗しているプロジェクトを予測で失敗と分類できている)。
ランダムフォレストによる特徴量の重要度比較
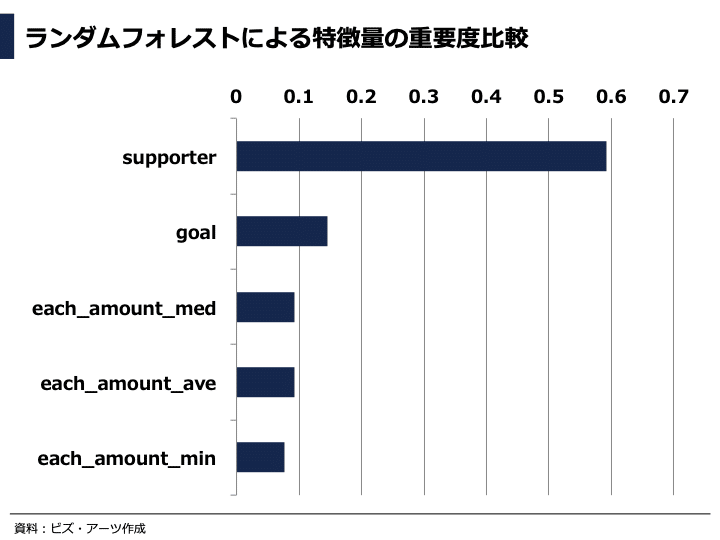
ランダムフォレストという機械学習アルゴリズムで、各特徴量の重要度を出してみると、支援者数(supporter)の重要度が他の特徴量と比べて非常に大きいことが分かります。
その後に目標額(goal)と支援金単価(each_amount_***)が同じ程度の重要度で並んでいます。
ちなみにランダムフォレストを使って学習させたモデルでは、Accuracy scoreが0.91となっており、決定木よりも更に精度よく予測できていました。
3rd try 決定木の分類可視化
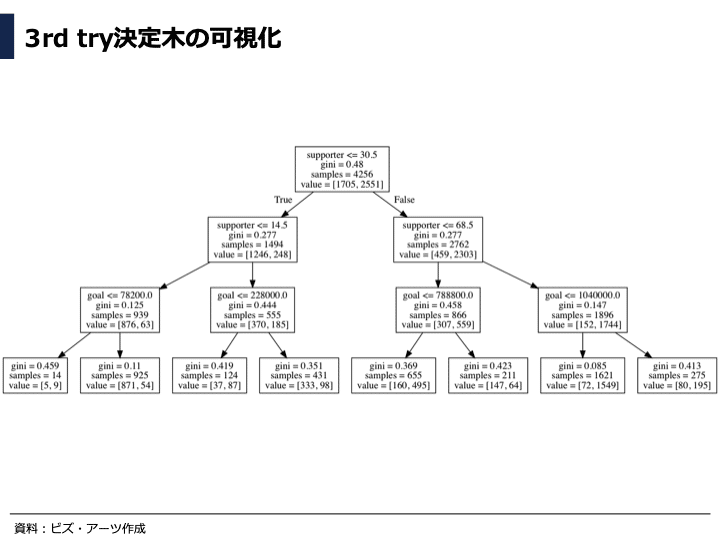
3rd tryの決定木モデルの分類を可視化しました。
今回の決定木の深さでは、支援者数と目標額のみで分類していることが分かります。
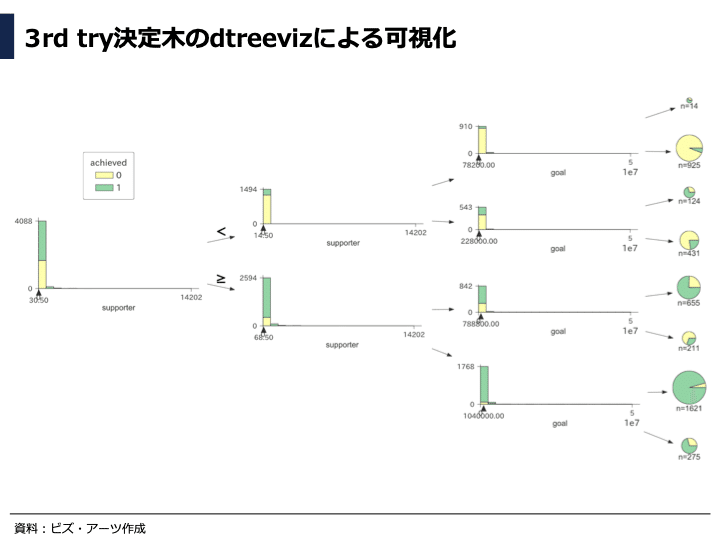
先ほどと同じようにdtreevizを使って、分類の結果をグラフ化しました。
円グラフを見ると、支援者数を特徴量に追加することで、1st tryよりも成功と失敗のプロジェクトがきれいに分かれていて、分類精度が上がっていると考えられます。
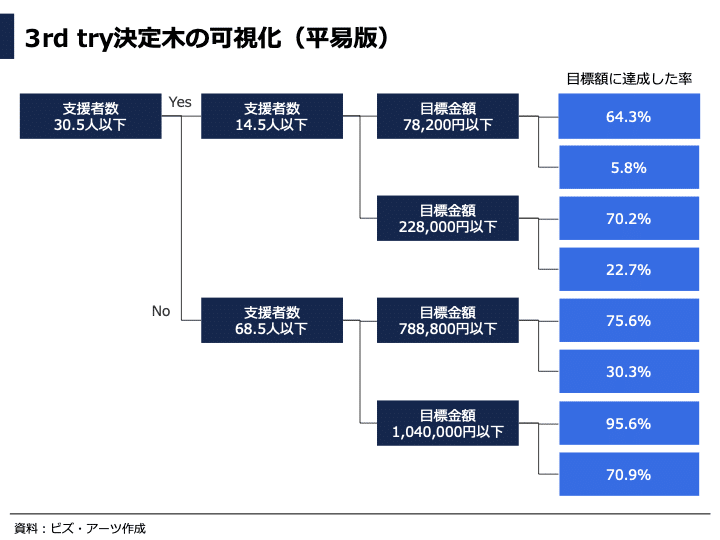
3rd tryの分類を見てみると、まず、目標額が78200円よりも大きい場合、支援者数を14.5人より多く集めることができないと、成功率は5.8%と非常に低くなります。
次に目標額が22万8000円の場合、支援者数を14.5〜30.5人集めることができれば、成功率は70.2%と比較的高いですが、22万8000円よりも大きく目標額を設定すると成功率は22.7%とだいぶ下がってしまいます。
目標額が78万8800円以下の場合、支援者数を30.5〜68.5人集めることができれば、成功率は75.6%となっています。また、支援者数を68.5人よりも多く集められる場合は、目標額が104万円以下であれば、成功率が95.6%となり、かなり高い確率で目標額を集めることができそうです。
まとめ

今回は、クラウドファンディングサービス マクアケのWebサイトに掲載されているプロジェクトデータを使って、機械学習によって目標額達成 or 未達成を予測、考察してみました。
今回の考察としては、プロジェクト成功・失敗を決める要因として、支援者数をどれほど集められそうかの見積りが非常に重要であると考えられます。したがって、プロジェクトを遂行するために必要な目標額と見込み支援者数の両面から目標額や支援金単価を設計できるかが成功率を左右し得るのではないでしょうか。
機械学習については、目標額、クラウドファンディング開始年(前回の記事でも目標額や支援者数が年々変化していた)、プロジェクトカテゴリなどのセグメント別に機械学習したり、特徴量のスケーリングを工夫することで、予測精度を改善できるかもしれません。
最後まで読んでいただき、ありがとうございます。
企業やマーケット関連の話など、ツイッターでもつぶやいてますので、フォローして頂けると喜びます。
昨日ツイートした記事の中の3Dグラフに企業名も入れてみました。売上成長率、EBITDA率、自己資本比率でクラスタリングした時のバランス型クラスタ。
— ぽこしー📊図解ビジネスアナリスト (@biz_arts1) October 27, 2020
Wantedly
カオナビ
チームスピリット
Sansan
HENNGE
サイボウズ
ユーザベース
メドレー
Salesforce
など
👇👇👇記事https://t.co/vAJtYjyUiz pic.twitter.com/IFzooH6VBP
SaaS上場企業の上場直前と直近のBS比率。
— ぽこしー📊図解ビジネスアナリスト (@biz_arts1) September 7, 2020
Wantedly
freee
カオナビ
ロジザード
ユーザーローカル
チームスピリット
サイバーセキュリティクラウド
AI CROSS
スマレジ
Sansan
HENNGE
チャットワーク pic.twitter.com/YU7hQfNhq6
Adobeのサブスク化へのシフトが見事なグラフ pic.twitter.com/cg4qcOqlFl
— ぽこしー📊図解ビジネスアナリスト (@biz_arts1) November 5, 2020
この記事が気に入ったらサポートをしてみませんか?