
ゆるゆる機械学習① 〜 教師あり学習(回帰)編 〜

ゆるゆる機械学習とは
「これからはAIだ!」と言われて久しいこのご時世。
ゆるい感じでAIの取っ掛かりとしてイメージをつかんでもらうことを目的にした記事です。
このAIと呼ばれている技術は、機械学習と呼ばれる分野に基礎をおいています。
なので、この機械学習について解説をいきます。
この記事のターゲット
機械学習をはじめようと思ったがイマイチわからずに挫折した人
これを読み終わった頃には「機械学習って具体的になにをどう学習してるの?」のイメージがつくようになるはずです!
機械学習とはなんぞや
機械学習(きかいがくしゅう、英: machine learning)とは、人工知能における研究課題の一つで、人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法のことである。by 機械学習 - ウィキペディア
ざっくりと言い換えると「人間の学習能力をエミュレーションする機械を作るチャレンジしてみよか」みたいな感じです。
ここ最近のAIと呼ばれる代物は、この技術を応用することでこれまで人間にしかできなかったような仕事が機械でもできるようになるかも、と考えて作られたものです。
機械学習にはざっくりと大分すると教師あり学習と教師なし学習と呼ばれるものに別れます。
「学習」というからには両方ともデータを何らかの方法で学んでいきます。
この2つのカテゴリ分けの違いは、データの学習方法にあります。
教師あり学習とは、正解データを用意して「こんな感じのデータをもらったら、こういう感じの正解を予測・分類できるようになっといてくれ」と学習をさせる方法です。
教師なし学習とは、正解のない単なるデータのみをポンと渡して「ここからパターンを勝手に見つけといてくれ」と任せる手法です。
今回の範囲は前者の教師あり学習にしぼって「学習するってなに?」ということを説明します。
教師あり学習はモデルを見つける作業
さきほど「こんな感じのデータをもらったら、こういう感じの正解を予測できるようになっといてくれ」と学習させる方法と説明しました。
これをもっと掘り下げていきます。
教師あり学習と分類される手法もたくさんあって、
・線形回帰
・サポートベクターマシン
・ニューラルネットワーク(の一部)
・...etc
と並べきれないくらいあります。
どの手法もやっていることの本質的な部分は同じだったりします。
なので、今回は簡単に説明するため、線形回帰のうち単回帰と呼ばれる手法を用いて説明します。
単回帰がどんな手法なのかは、この話の中では知っている必要はありません。
気になる方は調べてみてください。
また、教師あり学習でやれることは基本的に2つ。
「回帰」と「分類」です。
今回は説明をしやすさを考慮して「回帰」のみを解説します。
回帰
正解データの傾向を表しそうくれそうな線(以下、「モデル」と呼ぶ)を見つけていく方法です。
これによって得られるモデルは、新しいデータを与えると元の学習されたデータの傾向を元に予測値を計算してくれます。
地価からランチの価格設定を予測するモデルを例にしてみました。
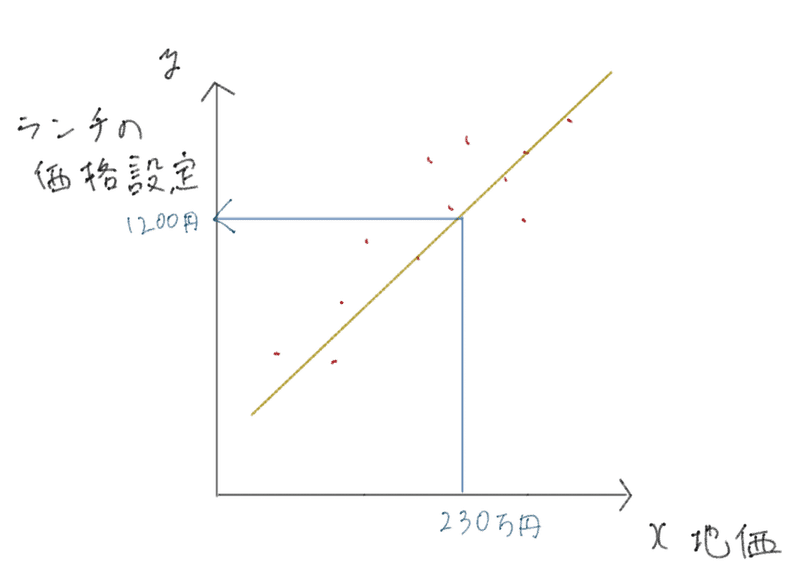
上図を用いて説明すると、回帰は赤色の点を学習データとして用意すると、データから黄色い線を見つけてくれる手法です。
この図の赤色の点は地価とランチの価格設定をセットにした正解データだと思ってください。
例えば、こんな感じのデータです。
これを利用して、データにフィットしそうな黄色い線(学習済みモデルというのですが、以下「モデル」と呼びます)を見つけていきます。
そして、この学習によって得られたモデルは「地価が230万円だったら、ランチの価格設定はいくら?」と聞くと、「多分、1200円くらいだよ。」と返してくれるようになるわけです。
学習するとは「可能な限り予測の誤差を無くす」こと
学習をするとはデータにフィットするモデルを探すことと説明しました。
では、どうやってこのようなモデルを探すのでしょうか。
回帰のケースを使って、より具体的に説明します。
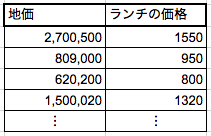
最初は上図のように正解データだけがあると考ましょう。
さきほどの例で言えば、地価とそれに対応するランチ価格です。
学習のはじめの段階では、とりあえずこの図に適当に線を引いてみます。
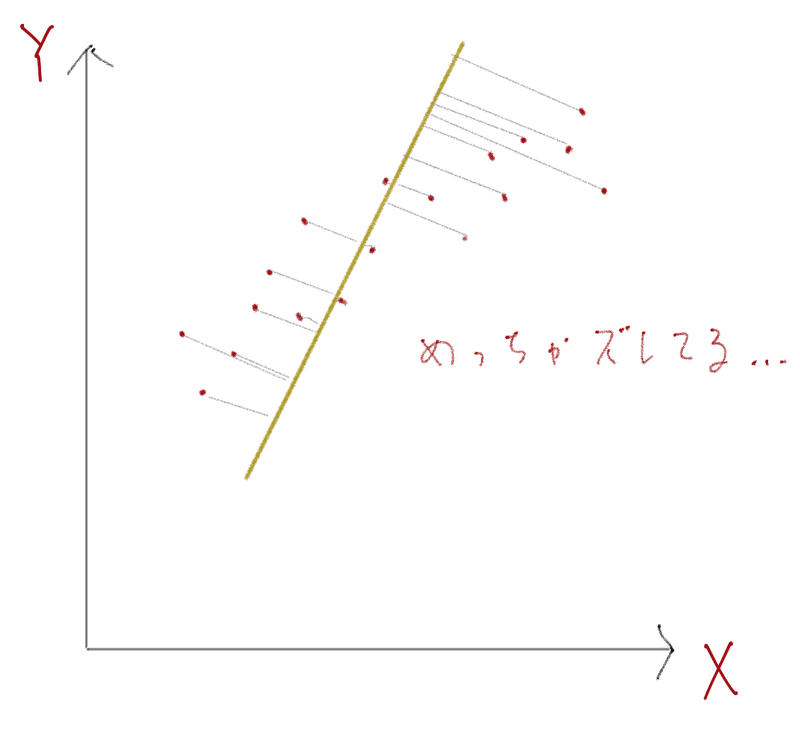
すると、上図のように正解データの傾向と引いた線がだいぶズレていることがわかりますよね。
これらの正解データたちと引いた線のズレを誤差と呼びます。
この誤差を減るように少しずつ線を引き直していき、誤差を可能な限り最小にできる線を見つけていきます。
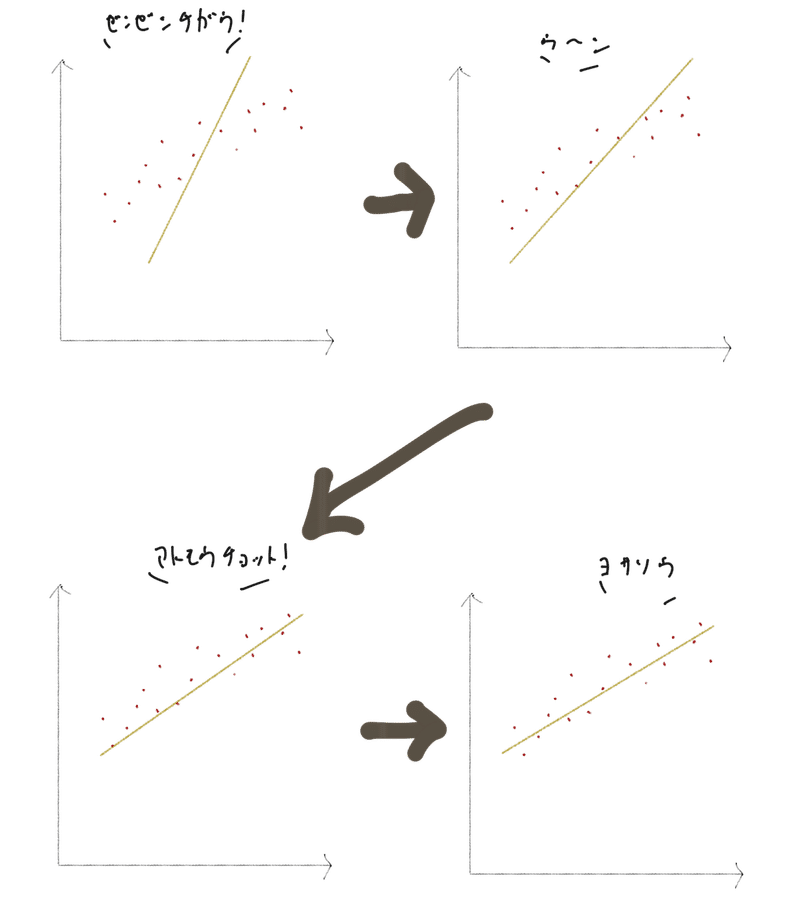
こうして与えられたデータにフィットする黄色い線(モデル)を見つけます。
このズレを修正しながら、良さげなモデルを探す計算していく手法を最急降下法と呼びます。
最急降下法 is 何
最急降下法は、モデルと実データの誤差を可能な限り小さくしていく手法だと説明しました。
この手法を説明するためには、まずは「モデルとはなにか」「誤差とはなにか」をもう少し知る必要があります。
モデル is 何
これまで黄色い線だとかなんだとか説明したわけですが、実のところモデルとは「データの傾向をいい感じに表してくれそうな関数」のことを指します。
関数は数式次第で表現できる傾向の形が変わります。
この記事で利用した例は単回帰なので、下図の①を利用しています。

ちなみに...、例示をした関数もほんの一例に過ぎず、無限に存在します。
どういう関数を利用するかは、自身が利用したいデータの傾向を考えながら決める必要があります。
誤差 is 何
誤差とは正解データたちと引いた線のズレと説明しました。
このズレを計算するには「損失関数」と呼ばれる関数を利用する必要があります。
この損失関数の計算結果は学習された正解データとモデルの計算結果のズレの合計を表します。
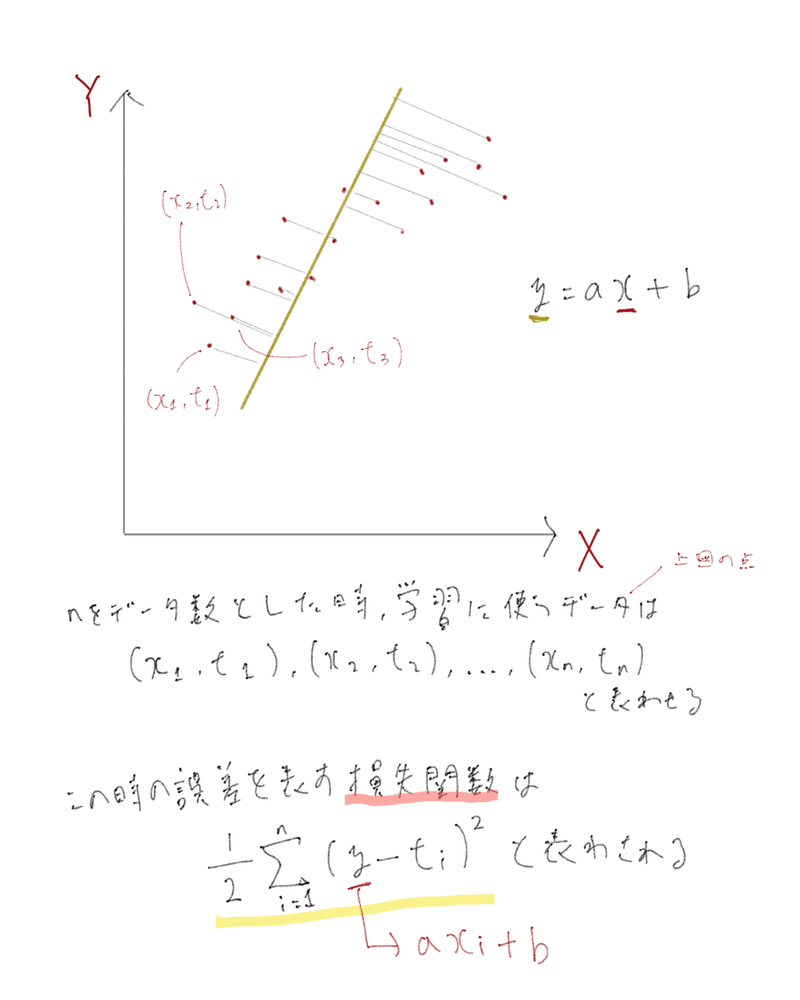
具体的に説明すると、学習データを一つ取り出して(例えば( x1, t1 ))、xを使ってモデルの関数(y = ax + b)を計算したときに、yがデータの結果(t)からどれくらいズレているのかを計算してくれます。
つまり、この関数のうちaやbがモデルの計算結果のカギを握るわけです。
なので、初期の説明で「適当に黄色い線を引く」と説明した部分は、aやbに適当な値をいれておく、ということを意味します。
誤差の減らし方
モデルと誤差についてもう少し掘り下げました。
それではいよいよ最急降下法について解説します。
「最急降下法」は「正解データにモデルが一番フィットするパラメータを探していく作業」です。
誤解を恐れずに具体的に説明すれば、上図で表されているモデルの関数(y = ax + b)の中のちょうど良いaやbを探してくる作業なのです。
適当に選ばれたaやbで作られたモデルによって誤差は生まれます。
この誤差を減らすためには、パラメータであるaやbの中身の数字を変えたときに損失関数の結果がどれくらい減りそうか具合を調べる必要があります。
「どれくらい減りそうか具合」とは変化率のことです。
変化率を計算するのは微分という数学的な操作によってなされます。
そのため、aやbで損失関数で微分する必要があります。
微分に関する解説はこのエントリでは省きます。
このどれくらい変わりそうか具合を使って、aやbの中身の数字を調整していきます。
こうしてを計算を繰り返していく、誤差が一番小さくなるちょうど良いaやbが見つかれば、学習は成功といえます。
この一連の流れがいい感じに何かを予測してくれる予測モデルを作るプロセスなのでした。
最後に
機械学習のアルゴリズムに関するおおまかな内容を説明しました。
手法の詳細な説明や、学習の成功に必要なキーポイント(過学習など)に関する説明を省いたりしています。
「もっともっとちゃんと学習をしたい!」という方には、Courseraの機械学習コースをオススメします。
Courseraの機械学習コースについてはコチラのエントリにて感想を書いています。
そして、私自身は機械学習の勉強をしはじめたばかりの人間です。
もしかして、説明に間違いがあるかもしれないです.......。
あればすぐに訂正いたしますので、コメントやTwitterでドンドンご指摘ください!
お待ちしております。
また、noteが数式に対応したときには、次はより数学的な解説込みでの記事にチャレンジしたいなと思います。
参考文献
・https://ja.coursera.org/learn/machine-learning
・https://ja.wikipedia.org/wiki/機械学習
・「機械学習プロフェッショナルシリーズ 深層学習」
次回予告
いつにするかは未定ですが、次回は「分類問題」について書きたいと思います。
そしてゆくゆくは「順伝播型ニューラルネットワーク」について書きたいと考えています。
いわゆる、「順伝播(フィードフォワード)」と「誤差逆伝播法(バックプロパゲーション)」について、ゆるゆるに解説したいです。
面白かったと感じた方!
よろしければ、Twitterをフォローしていただけると嬉しいです!
ウェッブのエンジニャーをやっております。 Web技術に限らず、機械学習や自然言語処理、数学、マーケティング、グロースハックなどにも興味を持っていて、勉強したことをまとめる記事を書いていく展望。