
Procgen Benchmark

以下の記事を参考に書いてます。
1. はじめに
「Procgen Benchmark」は、強化学習エージェントが汎化スキルをどれだけ速く学習するかを測定する、16個の強化学習環境です。
2. Procgen環境
◎ bigfish
プレイヤーは小さな魚から始まり、自分より小さい魚を食べることで大きくなります。自分より大きな魚と接触すると、プレイヤーは食べられ、エピソード完了となります。魚を食べると小さな報酬を受け取ります。他のすべての魚よりも大きくなると大きな報酬を受け取り、エピソード完了となります。

◎ bossfigh
プレイヤーは小さな宇宙船を操作し、大きなボス宇宙船を破壊します。ボスは、考えられる攻撃セットからランダムに選択します。プレイヤーは発射物をかわすか、破壊する必要があります。流星で防ぐこともできます。時間がくると、ボスのシールドが下がります。この時点で、プレイヤーはボスにダメージを与えられます。ボスが一定量のダメージを受けると、プレイヤーは報酬を受け取り、ボスはシールドを復活させます。ボスに数回ダメージを与えると、ボスは破壊され、プレイヤーは大きな報酬を受け取り、エピソード完了となります。

◎ caveflyer
船を出口に到達させるために洞窟内をナビゲートします。船の動きはAtariゲームの「Asteroids」に似ています。船は現在の軸に沿って前後に回転および移動できます。報酬の多くはレベルの最後に到達したことに由来しますが、船のレーザーで道に沿ってターゲットオブジェクトを破壊することで、追加の報酬を得ることができます。 レベル全体に静止した動いている障害物があります。

◎ chaser
Atariゲームの「MsPacman」に触発されました。Kruskalのアルゴリズムを使用して迷路を生成し、迷路に行き止まりがなくなるまで壁を削除します。プレイヤーは、すべての緑のオーブを集めます。敵を短時間脆弱にする3つの大きな星が出現します。脆弱ではない敵と衝突すると、プレイヤーは死にます。脆弱な敵を食べると、マップ内で卵が生成され、新しい敵が生まれます。プレイヤーは、オーブを集めると小さな報酬を受け取り、レベルを完了すると大きな報酬を受け取ります。

◎ climber
プレイヤーは一連の足場に登り、星を集めます。星を集めると小さな報酬が与えられ、レベル内のすべての星を集めると大きな報酬が与えられます。すべての星を収集すると、エピソード完了となります。レベル全体に散らばる敵がいます。

◎ coinrun
プレイヤーの目的は、レベルの右端のコインを収集することです。プレイヤーは、障害物、敵、割れ目をかわす必要があります。以前にリリースしたバージョンでは、速度情報が観察に描画されましたが、現在のバージョンでは描画されないことに注意してください。これにより、環境が著しく難しくなります。

◎ dodgeball
Atariのゲームの「Berzerk」に触発されました。プレイヤーは、壁と敵がランダムに配置された部屋に出現します。壁に触れるとゲームオーバーで、エピソード完了となります。プレーヤーは比較的ゆっくり移動し、部屋全体を移動できます。時々プレイヤーにボールを投げる敵もいます。プレーヤーはボールを投げることもできますが、彼らが向いている方向にのみになります。すべての敵にボールをヒットさせた場合、レベルの完了ボーナスを獲得できます。
◎ fruitbot
プレイヤーがロボットを操作するスクロールゲームです。壁の隙間を移動し、途中で果物を集めるます。果物を集めた場合はプラスの報酬を受け取り、果物以外を誤って集めた場合はマイナスの報酬を受け取ります。出現するオブジェクトの半分は果物(正の報酬)であり、半分は非果物(負の報酬)になります。プレイヤーは、レベルの最後に到達すると大きな報酬を受け取ります。場合によっては、プレーヤーはキーを使用して、道を塞ぐゲートのロックを解除する必要があります。

◎ heist
プレイヤーは、通路の鍵扉の奥に隠された宝石を盗みます。3色の鍵扉があり、開くために必要な鍵はレベル全体に散らばっています。迷路は、クラスカルのアルゴリズムによって生成しています。プレーヤーが特定の色の鍵を収集すると、プレーヤーはその色の鍵扉を開けることができます。プレイヤーが所有するキーは、画面の右上隅に表示されます。

◎ jumper
プレーヤーはウサギを操作し、ニンジンを集めます。プレーヤーは「ダブルジャンプ」が可能で、高い足場まで到達できます。接触するとプレイヤーを破壊するスパイク障害があります。画面には、ニンジンの方向と距離を表示するコンパスが含まれています。ゲームでの唯一の報酬は、ニンジンを集めることで、その時点でエピソード完了となります。

◎ leaper
古典的なゲーム「Frogger」に触発されました。プレーヤーはゴールに到達して報酬を得るために、複数のレーンを横断します。最初のグループには、車が走っています。2番目のグループには、川の丸太が流れています。プレイヤーが車と衝突したり川に落ちた場合、エピソード完了となります。

◎ maze
プレイヤーはネズミを操作して、迷路内のチーズを集めて、報酬を獲得します。迷路はクラスカルのアルゴリズムによって生成され、サイズは3x3〜25x25の範囲になります。迷路の寸法は、この範囲で均一にサンプリングされます。プレイヤーは、迷路内を上下左右に移動できます。

◎ miner
古典的なゲーム「BoulderDash」に触発されました。プレイヤーはロボットを操作し、泥を掘って世界を移動できます。世界には重力があり、土は岩やダイヤモンドを支えています。岩とダイヤモンドは自由空間を通って落下し、互いに転がり落ちます。ボルダーまたはダイヤモンドがプレーヤーに落ちたら、ゲームオーバーです。目標は、レベル内のすべてのダイヤモンドを収集し、出口を通過することです。プレイヤーは、ダイヤモンドを集めると小さな報酬を受け取り、レベルを完了すると大きな報酬を受け取ります。

◎ ninja
プレイヤーは忍者を操作し、爆弾の障害物を避けながら、狭い棚を飛び越えなければなりません。プレーヤーは、必要に応じて爆弾を取り除くために、いくつかの角度で星を投げることができます。ジャンプは、その効果を高めるために、複数ステップにわたって貯めることができます。レベルの終わりにキノコを収集したことに対する報酬を受け取り、その時点でエピソード完了となります。

◎ plunder
プレイヤーは、画面の下部にある自分の船から砲弾を発射して敵の海賊船を破壊します。画面上のタイマーがカウントダウンします。このタイマーが切れると、エピソード完了となります。プレイヤーが発砲するたびに、タイマーは数ステップ先に進み、プレイヤーに弾薬を節約するように促します。友軍の船にぶつからないように注意しなければなりません。敵の船に命中するとプラスの報酬を受け取り、友軍の船に命中すると大きなタイマーペナルティを受け取ります。左下隅のターゲットは、ターゲットとする敵船の色を識別します。

◎ starpilot
シンプルな横スクロールシューティングゲームです。すべての敵がプレイヤーを直接標的とする発射物を発射するため、人間がプレイするのは比較的困難です。かわせないと、すぐゲームオーバーになります。速い敵と遅い敵、ライフが多い固定砲台、プレイヤーの視界を遮る雲、通過できない流星があります。

3. 入門
あなたが人間であろうとAIであろうと、環境の使い方は簡単です。
$ pip install procgen # インストール
$ python -m procgen.interactive --env-name starpilot # 人間
$ python <<EOF # ランダムAIエージェント
import gym
env = gym.make('procgen:procgen-coinrun-v0')
obs = env.reset()
while True:
obs, rew, done, info = env.step(env.action_space.sample())
env.render()
if done:
break
EOF全ての「Procgen環境」では、新しいレベルに汎化する前に500〜1000の異なるレベルでの訓練が必要であることがわかりました。これは、標準RLベンチマークが各環境内でより多くの多様性を必要とすることを示唆しています。「Procgen Benchmark」は、OpenAI RLチームが使用する標準の研究プラットフォームになりました。より良いRLアルゴリズムの作成において、コミュニティを加速することを願っています。
4. 環境の多様性がカギ
いくつかの環境では、エージェントが著しく大規模な訓練セットにオーバーフィットできていることが観察されています。その証拠として、強化学習の定番である「Arcade Learning Environment」(ALE)では過剰適合する可能性を高めています。ALEの異なるゲーム間の多様性はこのベンチマークの最大の強みですが、汎化をあまり重視していないことは大きな欠点になります。エージェントは、関連するスキルをしっかりと学習しているのか、それとも特定の軌道をほぼ記憶しているのか、問い正す必要があります。
「CoinRun」は、プロシージャル生成(Procedural generation : 手動ではなくアルゴリズムでデータを作成する方法)によって訓練レベルとテストレベルで異なるレベルを構築することにより、この問題に対処するように設計されました。「CoinRun」はRLの汎化の定量化に役立ちましたが、それでも1つの環境にすぎません。「CoinRun」は、RLエージェントが直面しなければならない多くの課題の完全な代表ではない可能性があります。
私たちは両方の長所を求めています。「多様」な環境で構成されるベンチマークであり、それぞれが基本的に「汎化」を必要とするもの。このニーズを満たすために、「Procgen Benchmark」を作成しました。「CoinRun」は現在、「Procgen Benchmark」の最初の環境として機能しています。
「Obstacle Tower Challenge」や「GVGAI GYM」などの以前の研究では、プロシージャル生成を使用してRLの汎化をより適切に評価することも推奨されています。「GVGAI GYM」から直接インスピレーションを得た2つの「Procgen環境」を使用して、同様の精神で環境を設計しました。「Dota」や「StarCraft」のような他の環境も環境ごとの複雑さを多く提供しますが、これらの環境を迅速に反復することは困難です。
「Procgen Benchmark」を使用して、実験的利便性、環境内の高度な多様性、環境全体の高度な多様性のすべてに努めています。
5. Procgen Benchmark
「Procgen Benchmark」は、強化学習における「サンプル効率」と「汎化」の両方を測定するように設計された16の強化学習環境を提供しています。
このベンチマークは、各環境で個別の訓練セットとテストセットを生成できるため、汎化の評価に最適です。すべての環境がRLエージェントにとって多様で魅力的な課題を提起するため、「サンプル効率」を評価するのにも適しています。環境の本質的な多様性は、エージェントが堅牢なポリシーを学習することを要求します。状態空間の狭い領域への過剰適合は十分ではありません。言い換えると、エージェントが絶えず変化するレベルに直面している場合、「汎化」は成功に不可欠な要素になります。
6. 設計基準
以下の基準を満たすように、「Procgen環境」を設計しました。
・高度な多様性
環境生成ロジックには、基本的な設計上の制約に従って最大限の自由度が与えられます。結果のレベル分布の多様性は、エージェントに意味のある汎化の課題を提示します。
・高速評価
環境の難易度は、Baselinesエージェントが200Mステップの訓練後に大幅に進歩するように調整されます。さらに、環境は単一のCPUコアで毎秒数千ステップを実行するように最適化されており、高速な実験的パイプラインが可能になります。
・調整可能な難易度
すべての環境は、簡単に調整できる難易度の高い2つの難易度設定をサポートしています。ハードな難易度設定を使用して結果を報告しますが、計算能力へのアクセスが制限されているユーザーは簡単な難易度設定を利用できます。簡単な環境では、訓練に約8分の1のリソースが必要です。
・視覚認識と運動制御の重視
先例に合わせて、環境は多くの「Atari」および「Gym Retro」のゲームスタイルを模倣しています。うまく機能するかどうかは、主に、観察空間で重要な特徴を特定し、適切な低レベルの行動を実施することにかかっています。
7. 汎化の評価
「Retroコンテスト」の実施により、RLの汎化がどれほど困難であるかを認識しました。後に、「CoinRun」の実験により、エージェントの汎化の闘いのより明確な絵が描かれました。「Procgen Benchmark」の16の環境すべてを使用して、RLの「汎化」に関する徹底的な調査を実施しました。
最初に、「訓練セットのサイズ」が汎化に与える影響を測定しました。各環境で、サイズが100〜100,000レベルの訓練セットを生成しました。PPOを使用して200Mステップの訓練を行い、未見のテストレベルでパフォーマンスを測定しました。
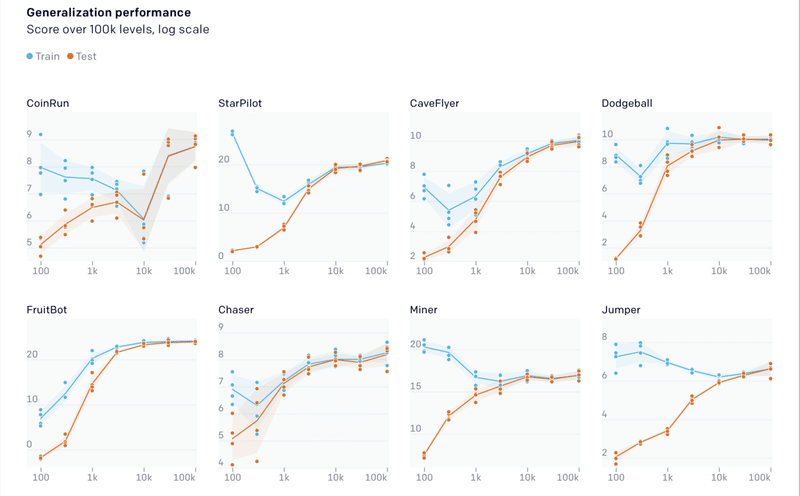
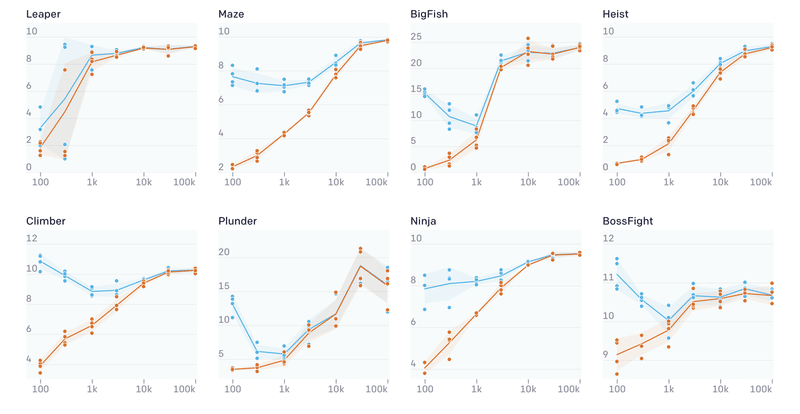
エージェントは、ほとんどすべての環境で小規模な訓練セットに強く適合していることがわかりました。場合によっては、エージェントは10kものレベルにアクセスして、汎化のギャップを埋める必要があります。また、多くの環境で、特定のしきい値を超えると、訓練セットが大きくなるにつれて訓練のパフォーマンスが向上するという傾向が見られました。これは、教師あり学習で見られる傾向に反するもので、通常、訓練のパフォーマンスは、訓練セットのサイズとともに低下します。この訓練のパフォーマンスの向上は、さまざまなレベルによって提供される暗黙的なカリキュラムによるものと考えています。エージェントが訓練セットのレベル全体で汎化を学習する場合、訓練セットを大きくすると訓練のパフォーマンスが向上します。以前、「CoinRun」で気づいたこの効果は、多くの「Procgen環境」でも頻繁に発生することがわかりました。
8. 決定論的なレベルでのアブレーションスタディ
プロシージャル生成の重要性を強調するために、単純なアブレーションスタディ(各構成要素を1つだけ抜いた手法を比較)を実施しました。すべてのエピソードの開始時に新しいレベルを使用する代わりに、一定のレベルのシーケンスでエージェントを訓練しました。エージェントは最初のレベルで各エピソードを開始し、レベルを正常に完了すると、次のレベルに進みます。エージェントがいずれかの時点で失敗すると、エピソードは終了します。エージェントは、任意の多くのレベルに到達できますが、実際には、どの環境でも20番目のレベルを超えることはめったにありません。
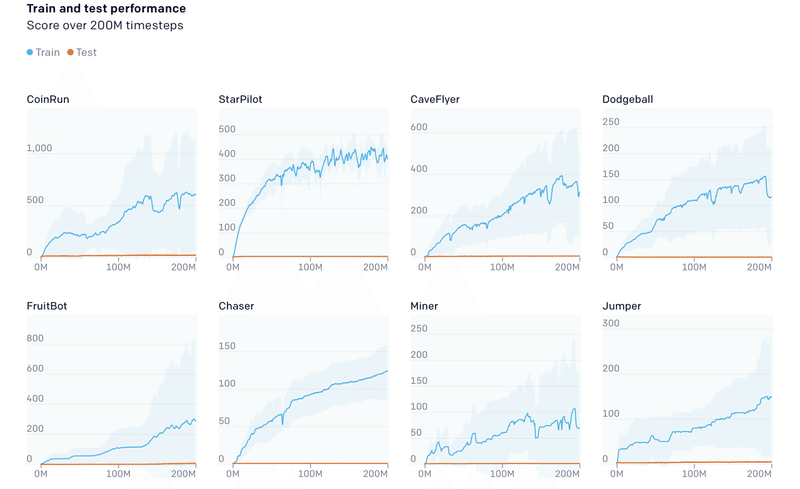
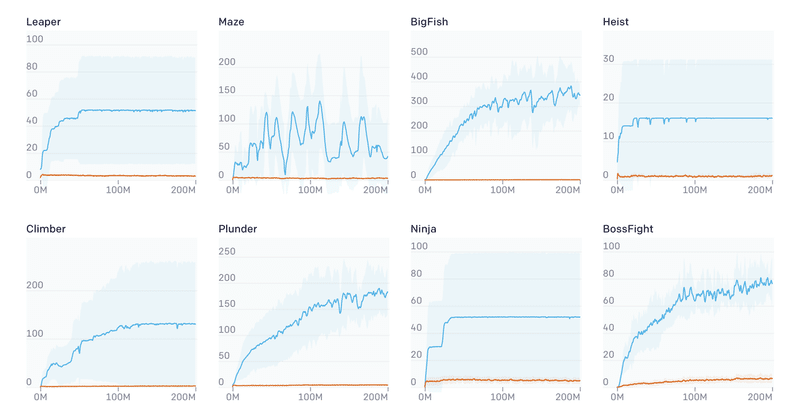
テスト時には、レベルのシーケンスの決定論を削除し、代わりにランダムにレベルのシーケンスを選択します。エージェントはほとんどのゲームの最初のいくつかの訓練レベルで有能になり、有意義な進歩の錯覚を与えます。ただし、テストのパフォーマンスは、エージェントが実際に基礎となるレベル分布についてほとんど何も学習していないことを示しています。訓練とテストのパフォーマンスのこの大きなギャップは強調する価値があると考えています。レベルの固定シーケンスに従う環境での訓練の隠れた重大な欠陥を明らかにします。これらの結果は、RLエージェントを訓練および評価する際に、多様な環境分布を使用することがいかに重要であるかを示しています。
9. 次のステップ
このベンチマークから収集された多くの洞察がより複雑な設定に適用されることを期待しており、これら新しい環境を使用してより有能で効率的なエージェントを設計できることを楽しみにしています。
この記事が気に入ったらサポートをしてみませんか?