オフライン強化学習における未解決の課題への取り組み

以下の記事を参考に書いてます。
・Tackling Open Challenges in Offline Reinforcement Learning
1. はじめに
ここ数年にわたっての、「ゲームプレイ」と「ロボット制御」での成功によって、「強化学習」への関心が高まっています。
1度収集した大量のデータセットから学習する「教師あり学習」とは違い、「強化学習」は試行錯誤のフィードバックループから学習します。このループは学習中にアクティブな相互作用を必要とし、新しいポリシーを学習するたびにデータを収集します。そのため、試行錯誤によるデータ収集に、「コストがかかる」「時間がかかる」「責任が負えない」といった多くの実世界タスク(ヘルスケア、自動運転、対話システムなど)は、このアプローチは適用できません。
アクティブなデータ収集を使用できるタスクであっても、データセットのサイズと多様性が制限されてしまいます。
「オフライン強化学習」は、それ以上の操作なしに、以前に収集されたデータセットのみで学習します。意思決定戦略を自動的に学習するために、以前に収集されたデータセット(以前の強化学習実験、人間によるデモンストレーション、手動で設計した探索戦略など)を利用する方法を提供します。
原則として、オフポリシーはオフラインで使用できますが(完全オフポリシー)、通常はアクティブな環境の相互作用で使用した場合にのみ成功します。直接的なフィードバックを受け取れないと、望ましくないパフォーマンスを示すことがよくあります。
「オフライン強化学習」には非常に大きな可能性がありますが、この重要なアルゴリズムの課題を解決しない限り、その可能性に到達することはできません。
「オフライン強化学習:未解決の問題に関するチュートリアル、レビュー、および展望」では、「オフライン強化学習」の課題に取り組むための包括的なチュートリアルを提供し、残っている多くの問題について説明します。これらの問題に対処するために、ベンチマークフレームワーク「D4RL」(Deep Data-Driven Reinforcement Learning)のデータセットと、シンプルで効果的なオフライン強化学習アルゴリズム「CQL」(conservative Q-learning)をリリースしました。
2. オフライン強化学習のベンチマーク
現在のアプローチを理解し、将来に導くためには、まず効果的なベンチマークが必要です。以前の研究での一般的なアプローチは、成功した「オンライン強化学習」によって生成したデータを単に使用することでした。このデータ収集アプローチは単純ですが、「オンライン強化学習」を適用できない実世界タスクも存在するため、人工的なものになります。タスクを適切にカバーする多様なデータから、現在よりも優れたポリシーを学習したいと考えています。たとえば、ロボットアームの手動設計されたコントローラーからデータを収集し、「オフライン強化学習」を使用して改良されたコントローラーを訓練することができます。現実的な設定でこの分野を進歩させるには、これらの設定を正確に反映するベンチマークが必要になります。
「D4RL」は、標準化された環境、データセット、評価プロトコル、およびこれの達成に役立つアルゴリズムの参照スコアを提供します。これは「batteries-included」なリソースであり、誰でも簡単に始めて、手間をかけずに始めることができます。
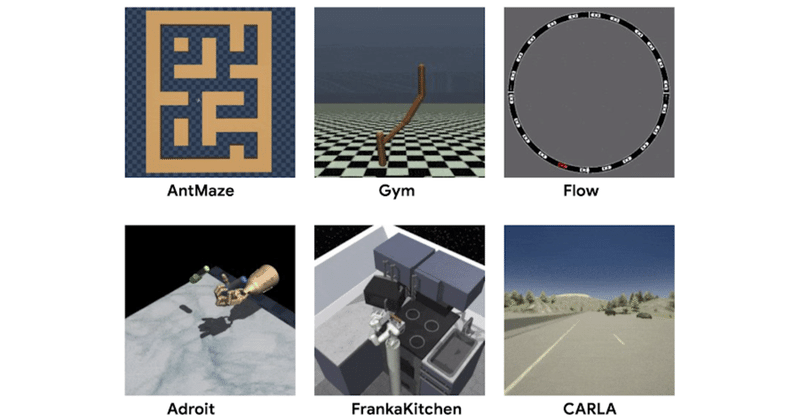
「D4RL」の主な目標は、実際のデータセットの課題と実際のアプリケーションの両方を反映するタスクを開発することでした。以前のデータセットは、「ランダムエージェント」または「強化学習で訓練されたエージェント」から収集されたデータを使用していました。代わりに「自動運転」「ロボット工学」およびその他のドメインでの潜在的なアプリケーションを検討することにより、「オフライン強化学習」の実際のアプリケーションが、「人間のデモンストレーション」または「ハードコードされたコントローラー」から生成されたデータ、異種ソースから収集されたデータ、およびデータの処理をどのように必要とするかを検討しました。
広く利用されている「MuJoCo」タスクの他に、「D4RL」にはより複雑なタスクのデータセットが含まれています。例えば、ハンマーを使用するために現実的なロボットハンドを操作する「Adroit」は、これらのタスクが非常に困難で、限られた人間のデモンストレーションでの課題を示しています。以前の研究では、既存のデータセットでは競合するメソッドを区別できないことがわかりましたが、「Adroit」はそれらのメソッド間の明確な欠陥が明らかになりました。
実世界のタスクのもう1つの一般的なシナリオは、訓練に使用されるデータセットが、対象のタスクに関連しているが特に対象としていない様々なアクティビティを実行するエージェントから収集するシナリオです。
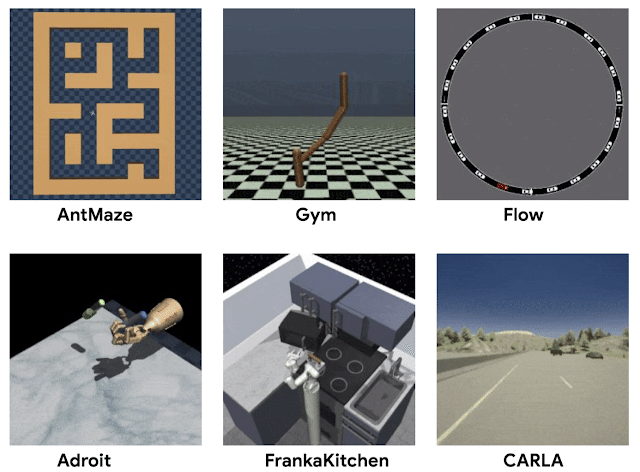
例えば、人間のドライバーからのデータは、車をうまく運転する方法を示しているかもしれませんが、必ずしも特定の目的地に到達する方法を示しているわけではありません。この場合、「オフライン強化学習」を使用して、運転データセット内のルートの一部を「ステッチ」して、実際にはデータに表示されなかったタスク(ナビゲーション)を実行できます。説明的な例として、下の図で「A」と「B」のラベルが付いたパスが与えられた場合、「オフライン強化学習」はパスを「リミックス」してパスCを生成できるはずです。
パスAとBを観察したので、これらを組み合わせて最短パス(C)を形成。
この「ステッチ」機能を実行するために、ますます困難になる一連のタスクを作成しました。以下に示す迷路環境では、一連の迷路内の場所に移動するために2つのロボット(「ボール」または「蟻」ロボット)が必要です。

「D4RL」の迷路ナビゲーション環境。データセットには見られなかった新しいナビゲーション目標を達成するためにパスの「ステッチ」部分が必要。
より複雑な「スティッチング」シナリオは、(Adept環境に基づいた)「FrankaKitchen」によって提供されます。VRインターフェースを使用した人間によるデモンストレーションはマルチタスクデータセットで構成され、「オフライン強化学習」ではこのデータを再度「リミックス」する必要があります。

「FrankaKitchen」では、シミュレートされたキッチンでさまざまなタスクを実行する人間のデモンストレーションを使用する必要がある。
最後に「D4RL」には、既存のドライビングシミュレータに基づく「オフライン強化学習」の現実的なアプリケーションの可能性を、より正確に反映するための2つのタスクが含まれています。1つは、Intelで開発された広く使用されている運転シミュレータ「CARLA」を利用したデータセットで、現実的な運転領域で写実的な画像を提供します。もう1つは、交通管理シミュレータ「Flow」のデータセットです。 自動運転車を制御して効果的な交通を促進します。

D4RLには、「CARLA」を使用した運転(左)および「Flow」を使用した交通管理(右)の現実的なシミュレータに基づくデータセットが含まれています。
これらのタスクと標準化されたデータセットをPythonパッケージ化して、研究を加速しました。さらに、新しいアプローチのベースラインとして、関連する従来の方法(BC、SAC、BEAR、BRAC、AWR、BCQ)を使用してすべてのタスクのベンチマーク番号を提供します。「オフライン強化学習ベンチマーク」を提案するのは私たちが最初ではありません。これまでの多くの研究で、実行中の強化学習アルゴリズムに基づく単純なデータセットが提案されています。ただし、「D4RL」のより現実的なデータセットは、効果的に進歩を促進すると考えています。
3. オフライン強化学習のアルゴリズム
ベンチマークタスクを開発したところ、既存の方法では、より困難なタスクを解決できないことがわかりました。主な課題は分散シフトから生じます。履歴データを改善するために、「オフライン強化学習アルゴリズム」は、データセットで行われた決定とは異なる決定を行うことを学習する必要があります。ただしこれは、良い決断の結果をデータから推定できない場合に問題を引き起こす可能性があります。迷路の中でこの特定のターンを行ったエージェントがいない場合、それが目標に繋がるかはどのように判断すれば良いのでしょうか。この分布シフトの問題を処理しないと、オフライン強化学習は誤って、めったに見られない行動について楽観的な結論を下す可能性があります。これとは対照的に、好奇心と驚きに基づいてモデル化された報酬ボーナスがエージェントに楽観的にバイアスをかけて、潜在的に価値のあるすべての経路を探索するオンライン設定と比較してください。エージェントはインタラクティブなフィードバックを受け取るため、行動がやりがいのないものであることが判明した場合は、将来の経路を単純に回避できます。
これに対処するために、個別の動作モデルの明示的な構築を回避し、重要度の重みを使用せずに過大評価を防ぐように設計されたオフライン強化学習アルゴリズム「CQL」を開発しました。標準のQ学習(およびActor-Critic)は以前の推定値からブートストラップしますが、「CQL」は基本的に悲観的なアルゴリズムであるという点でユニークです。特定の行動で良好な結果が見られなかった場合、その行動は 良いものになります。「CQL」の中心的な考え方は、期待リターンを概算することを学ぶのではなく、ポリシーの期待リターン(Q関数と呼ばれる)の下限を学ぶことです。その後、CQ関数に基づいてポリシーを最適化すると、その値がこの推定よりも低くならず、過大評価によるエラーを防ぐことができます。
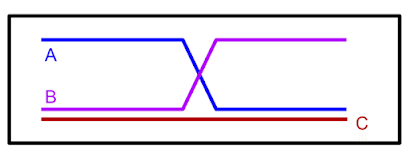
私たちは、「CQL」がより困難な「D4RL」タスクの多くで最先端の結果を達成していることを発見しました。「CQL」は、「AntMaze」「キッチンタスク」「8つのAdroitタスク」のうち6つの他のアプローチよりも優れていました。特に、「Ant」ロボットで迷路をナビゲートする必要のある「AntMazeタスク」では、「CQL」が重要なポリシーを学習できる唯一のアルゴリズムであることがよくあります。「CQL」は、Atariゲームなどの他のタスクでもうまく機能します。 AgarwalらのAtariタスクでは、データが制限されている場合(「1%」のデータセット)、「CQL」は以前の方法よりも優れています。 さらに、「CQL」は、追加のニューラルネットワークを訓練することなく、既存のアルゴリズム(QR-DQNやSACなど)の上に簡単に実装できます。
Agarwalらの1%データセットを使用したAtariゲームでのCQLのパフォーマンス。
4. おわりに
「オフライン強化学習」は、標準的なベンチマークへの第一歩を踏み出しましたが、明らかに改善の余地がまだあります。アルゴリズムの改善に伴い、ベンチマークタスクを再評価し、より困難なタスクを開発する必要があると考えています。コミュニティと協力して、ベンチマークと評価プロトコルを進化させることを楽しみにしています。
この記事が気に入ったらサポートをしてみませんか?