
AlphaStar : マルチエージェント強化学習を使用したStarCraft IIのグランドマスターレベル

以下の記事が面白かったので、ざっくり訳しました。
・AlphaStar: Grandmaster level in StarCraft II using multi-agent reinforcement learning | DeepMind
1. はじめに
「AlphaStar」は、制限なしでeスポーツのトップリーグの実力に到達した最初のAIです。今年1月、「AlphaStar」の暫定版は、「StarCraft II」の世界トッププレイヤー2人に挑戦しました。「StarCraft II」は、史上最も人気のあるリアルタイムストラテジーゲームの1つです。それ以来、私達ははるかに大きな課題に取り組んできました。
私たちの新しい研究は、いくつかの重要な点で以前の研究と異なります。
(1) 現在「AlphaStar」には、カメラを通して世界を見るなど、人間がプレイするのと同じ種類の制約があり、その動作頻度にも強い制限があります。
(StarCraftプロフェッショナルDario "TLO" Wünschと共同)。
(2)「AlphaStar」は、「StarCraft II」の3つの種族であるProtoss、Terran、Zergとの1対1の対戦でプレーできるようになりました。各エージェントは、単一のニューラルネットワークになります。
(3) リーグトレーニングは完全に自動化されており、過去の実験で訓練されたエージェントからではなく、「教師あり学習」によって訓練されたエージェントからのみ開始しました。
(4)「AlphaStar」は、人間のプレイヤーと同じマップと条件を使用して、公式ゲームサーバーであるBattle.netでプレイします。すべてのゲームのリプレイはここから入手できます。
「AlphaStar」は、「ニューラルネットワーク」「強化学習によるセルフプレイ」「マルチエージェント学習」「模倣学習」などの汎用機械学習手法を使用して、汎用手法でゲームデータから直接学習することを選択しました。
Natureの論文に記載した手法を使用して、はBattle.netのアクティブプレイヤーの99.8%を超えてランク付けされ、「StarCraft II」の3つの種族(Protoss、Terran、Zerg)でグランドマスターレベルを獲得しました。これらの方法は他の多くのドメインに適用できると期待しています。
2. 学習ベースのシステムとセルフプレイ
「学習ベースのシステム」と「セルフプレイ」は、人工知能の顕著な進歩を促進したエレガントな研究概念です。1992年、IBMの研究者は、学習ベースのシステムとニューラルネットワークを組み合わせてバックギャモンのゲームをプレイする「TD-Gammon」を開発しました。「TD-Gammon」は、ハードコーディングされたルールまたはヒューリスティックに従ってプレイする代わりに、強化学習を使用して、試行錯誤を通じて、勝つ可能性を最大化することで勝利する方法を見つけ出すように設計されました。その開発者は、自己再生の概念を使用してシステムをより堅牢にしました。それ自体のバージョンと対戦することにより、システムはゲームでますます熟練しました。「学習ベースのシステム」と「セルフプレイ」の概念を組み合わせると、オープンエンドな学習の強力なパラダイムが提供されます。
それ以来、多くの進歩により、これらのアプローチは段階的に挑戦的なドメインに拡大できることが実証されています。たとえば、「AlphaGo」と「AlphaZero」は、システムが囲碁、チェス、将棋で超人的なパフォーマンスを達成することを学ぶことが可能であることを確立しました。「OpenAI Five」とDeepMindの「FTWは」、Dota 2やQuake IIIなどの現代のゲームでセルフプレイの力を実証しました。
「DeepMind」では、オープンエンドな学習の可能性と限界を理解することに関心があります。これにより、複雑で現実のドメインに対処できる堅牢で柔軟なエージェントを開発できます。「StarCraft」のようなゲームは、これらのアプローチを進めるための優れた訓練の場です。プレーヤーは限られた情報を使用して、複数のレベルとタイムスケールに影響する動的で難しい決定を下す必要があるためです。
3. セルフプレイの欠点
成功にもかかわらず、セルフプレイにはよく知られている欠点があります。
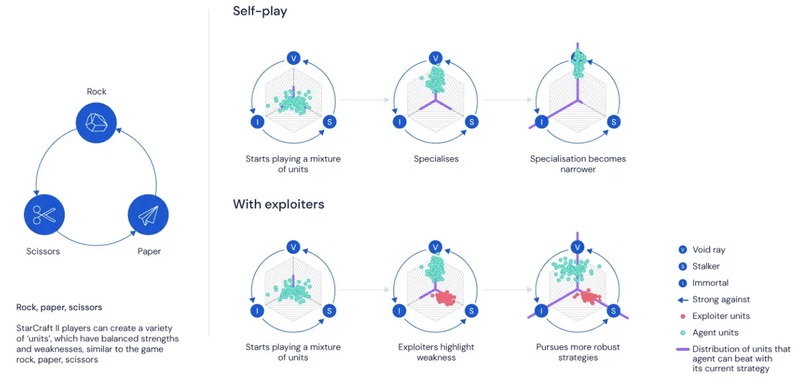
最も顕著なのは忘れることです。自分自身と対戦するエージェントは改善し続けるかもしれませんが、以前のバージョンに対して勝つ方法を忘れることもあります。忘却することで、エージェントが「しっぽを追いかける」サイクルを作り出し、収束することも、真の進歩を遂げることもありません。
たとえば、じゃんけんでは、エージェントは現在、他の手よりもグーを出すことを好む場合があります。セルフプレイが進むにつれて、新しいエージェントはグーに勝つため、パーに切り替えることを選択します。その後、エージェントはチョキに切り替わり、最終的にはグーに戻るというサイクルを作成します。
「Fictitious self-play」(以前のすべての戦略の混合物と対戦する)は、この課題に対処するための1つのソリューションになります。
4. mainエージェントとexploiterエージェント
研究環境として最初に「StarCraft II」をオープンソース化した後、「Fictitious self-play」でも強力なエージェントを作成するには不十分であることがわかったため、より優れた汎用ソリューションの開発に着手しました。
最近公開されたNatureの論文の中心的なアイデアは、「Fictitious self-play」の概念をエージェントのグループ、つまりリーグにまで広げています。通常、セルフプレイでは、すべてのエージェントが相手に対して勝つ可能性を最大化します。ただし、これは解決法の一部にすぎませんでした。
現実の世界では、「StarCraft」で上達しようとしているプレーヤーは、特定の戦略を訓練できるように友人と協力することができます。彼らの訓練パートナーは、対戦相手に勝つためだけでなく、上達しようとしているプレイヤーの練習のため、弱点となる状況を再現させます。つまり、勝つためにプレイすることだけでは不十分であるということです。かわりに、勝つことを目標とする「mainエージェント」と、弱点を再現することによって主要エージェントの成長を助ける「exploiterエージェント」の両方が必要になります。
この訓練方法を使用して、「StarCraft II」の戦略をすべてエンドツーエンドで完全に自動化された方法で学習します。
5. 探索と模倣学習
「探索」は、「StarCraft」などの複雑な環境におけるもう1つの重要な課題です。各タイムステップでエージェントの1人が使用できる行動は最大1026個あり、エージェントはゲームに勝ったか負けたかを知る前に何千もの行動を実行する必要があります。このような大規模な行動空間では、勝利戦略を見つけることは困難です。
強力なセルフプレイシステムと「mainエージェント」と「exploiterエージェント」の多様なリーグがあったとしても、このような複雑な環境で成功戦略を見つけることは不可能です。人間の戦略を学習し、エージェントがセルフプレイを通してそれらの戦略を探求し続けることを保証することが、「AlphaStar」のパフォーマンスを引き出す鍵となりました。
これを行うために、「模倣学習」を使用し、高度なニューラルネットワークアーキテクチャと言語モデリングに使用する手法を組み合わせて、アクティブプレイヤーの84%を上回るゲームをプレイする初期ポリシーを作成しました。
また、ポリシーを調整し、人間のゲームからのオープニングムーブの分布をエンコードする潜在変数を使用しました。これは、高レベルの戦略を維持するのに役立ちました。
「AlphaStar」はその後、セルフプレイ全体を通じてある種の蒸留を使用して、人間の戦略に向けて探索を偏らせました。このアプローチにより、「AlphaStar」は単一のニューラルネットワーク(各種族に1つ)内で多くの戦略を表現することができました。評価中、ニューラルネットワークは特定の開始動作に条件付けられませんでした。
6. おわりに
さらに、強化学習への以前のアプローチの多くは、その巨大な行動空間のために、「StarCraft」では効果がないことがわかりました。特に、「AlphaStar」はオフポリシーの強化学習に新しいアルゴリズムを使用しているため、古い方策でプレイされた経験か方策を効率的に更新できます。
「学習ベースのエージェント」と「セルフプレイ」を利用するオープンエンドな学習システムは、ますます困難な領域で印象的な結果を達成しています。
「模倣学習」「強化学習」「リーグの進歩」のおかげで、上記のビデオに示すように、「StarCraft II」のフルゲームでグランドマスターレベルに到達したエージェントである「AlphaStar Final」を訓練することができました。
このエージェントは、ゲームプラットフォームBattle.netを使用して匿名でオンラインでプレイし、3つすべての「StarCraft II」の種族でグランドマスターレベルを達成しました。
「AlphaStar」は、カメラインターフェースを使用してプレイしました。
人間のプレーヤーが持っている情報と同様の情報を使用し、アクションレートを制限して人間のプレーヤーと比較できるようにしました。インターフェイスと制限は、プロのプレーヤーによって承認されました。
最終的に、これらの結果は、汎用学習技術が複数のアクターが関与する複雑で動的な環境で動作するようにAIシステムを拡張できるという強力な証拠を提供します。
「AlphaStar」の開発に使用した手法は、AIシステム全般の安全性と堅牢性をさらに高めるのに役立ちます。現実世界の領域での研究の促進にも役立つことを願っています。
7. 参照
・Natureでこの作品の詳細を読む
・一般公開されている論文
・Battle.netゲームのすべてのリプレイを見る
この記事が気に入ったらサポートをしてみませんか?