
パラメータノイズによる探索の向上

以下の記事が面白かったので、ざっくり訳しました。
・Better Exploration with Parameter Noise
1. パラメータノイズによる探索の向上
強化学習アルゴリズムのパラメータに適応ノイズを追加することで、パフォーマンスが頻繁に向上することがわかりました。この探索方法は実装が簡単で、パフォーマンスが低下することがほとんどないため、試してみる価値があります。
2. 行動空間ノイズとパラメータノイズ

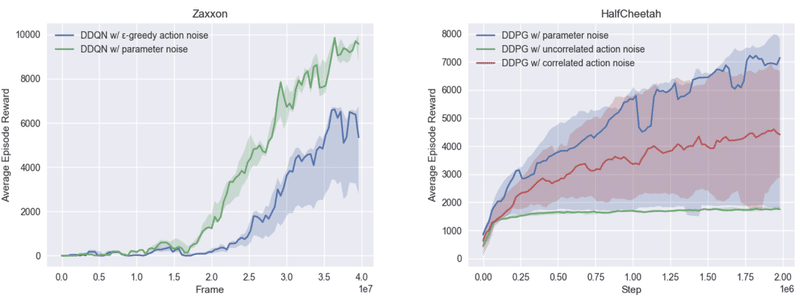
「パラメータノイズ」は、アルゴリズムがタスクを攻略するために利用可能な行動範囲をより効率的に探索するのに役立ちます。「パラメータノイズ」のない訓練では、非効率的な行動が頻発しますが、「パラメータノイズ」のある訓練では、効率的な行動を見せることがよくあります。「パラメータノイズ」により、エージェントのタスクを他のアプローチよりもはるかに迅速に学習することができます。「HalfCheetah」を「パラメータノイズ」ありで訓練させると、スコアは約3,000達成しますが、従来の「行動空間ノイズ」で訓練させるとスコアは約1,500しか達成しません。
「パラメータノイズ」は、「行動空間」ではなく「ニューラルネットワークのパラメータ」に適応ノイズを追加します。従来の強化学習は、「行動空間ノイズ」を使用して、エージェントが瞬間的に実行する可能性のある行動に関連付けられた「尤度」を変更します。「パラメータノイズ」は、エージェントのパラメータにランダム性を直接注入し、エージェントが現在検出していることに常に依存するように、それが行う行動種別を変更します。
この手法は、「進化戦略」(方策のパラメータを操作するが、環境を調査する際に方策が実行する行動に影響を与えない)とTRPO、DQNおよびDDPG(方策のパラメータには触れないが、方策の行動空間にノイズを追加する)のような「深層強化学習」の中間になります。
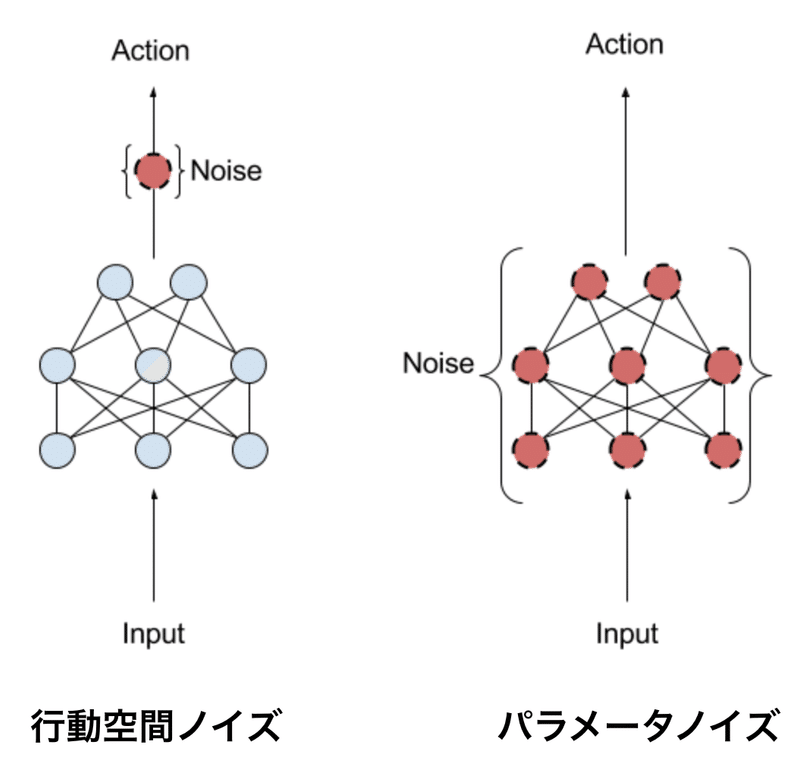
「パラメータノイズ」は、アルゴリズムが環境をより効果的に探索するのに役立ち、より高いスコアとよりエレガントな動作につながります。これは、「パラメータノイズ」を追加すると、エージェントの探索がさまざまなタイムステップで一貫し、「行動空間ノイズ」を追加すると、エージェントのパラメータに固有の何かと相関しない予測不能な探索につながるためだと考えられます。
人々は以前、方策の勾配に「パラメータノイズ」を適用しようとしました。この手法は、ディープニューラルネットワークに基づいた方策で機能し、オンポリシーアルゴリズムとオフポリシーアルゴリズムの両方に適用できることを示しました。
3. パラメータノイズの3つの問題
この調査を実施する際、3つの問題に遭遇しました。
(1) ネットワークの異なる層は、摂動に対して異なる感度を持つ。
(2) 方策の重みの感度は、訓練の進行中に時間とともに変化する可能性があり、方策が実行する行動を予測することが困難になる。
(3) 訓練中に「パラメータノイズ」が方策にどのように影響するかを直感的に理解するのは難しいため、適切なスケールのノイズを選択することは困難。
私たちはレイヤーの正規化を使用して最初の問題を処理します。これにより、摂動したレイヤーの出力(次のレイヤーへの入力)が同様の分布内にあることが保証されます。
パラメータ空間摂動のサイズを調整する適応スキームを導入することにより、2番目と3番目の問題に取り組みます。この調整は、行動空間に対する摂動の影響と、行動空間のノイズレベルが定義済みのターゲットよりも大きいか小さいかを測定することで機能します。このトリックにより、ノイズスケールを選択する問題を行動空間にプッシュすることができます。行動空間は、パラメータ空間よりも解釈しやすいものです。
4. Baselinesとベンチマーク
「DQN」「Double DQN」「Dueling DQN」「Dueling Double DQN」「DDPG」に、この手法を組み込んだ「Baselines」もリリースしました。「Atari環境」のサブセットで「パラメータノイズ」を追加した場合と追加しない場合のDDQNのパフォーマンス、および「MuJoCo環境」でのDDPGの3つのバリアントのベンチマークを含めました。
5. 開発
この研究を初めて行ったとき、DQNのQ関数に適用した摂動が極端な場合があり、アルゴリズムが同じ行動を繰り返すことがあることがわかりました。これに対処するため、DDPGのように方策を明示的に表す別のヘッドを追加しました(通常のDQNでは、方策はQ関数によって暗黙的にのみ表されます)。ただし、このリリースのコードを準備するときに、「パラメーターノイズ」を使用せずに実験を実行しました。これは、実装がはるかに簡単でありながら、個別のポリシーヘッドを備えたバージョンと同等に機能することがわかりました。さらなる実験により、ノイズの再スケーリング方法を変更したため、初期の実験以来アルゴリズムが改善された可能性があるため、個別のポリシーヘッドは実際に不要であることが確認されました。これにより、アルゴリズムを訓練するためのよりシンプルで実装しやすく、コストを抑えながら、非常に類似した結果を達成できました。
6. おわりに
AIアルゴリズムは、特に強化学習において、静かに微妙に失敗する可能性があり、それが失敗を回避するための問題解決につながる可能性があることを覚えておくことが重要です。
この記事が気に入ったらサポートをしてみませんか?