RLlib:スケーラブルな強化学習ライブラリ

1. RLlibの概要
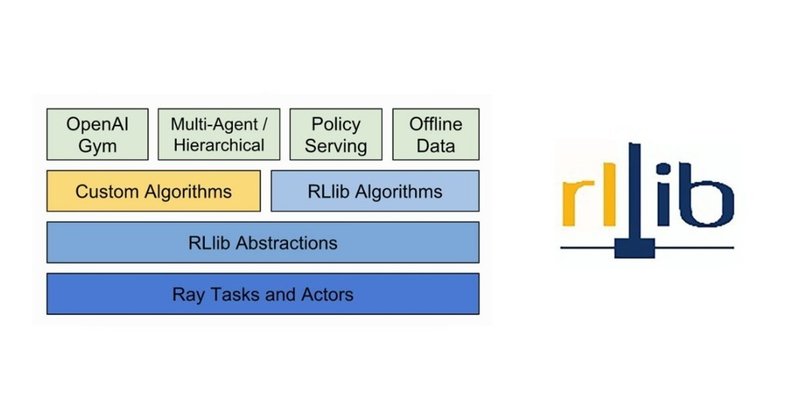
「RLlib」は、「パフォーマンス」と「コンポーザビリティ」の両方を提供することを目的とした「強化学習ライブラリ」です。Pythonの分散実行ライブラリ「Ray」のサブパッケージの1つになります。
・RLlib: Scalable Reinforcement Learning
◎パフォーマンス
・高性能アルゴリズムの実装
・プラグ可能な分散RL実行戦略
◎コンポーザビリティ
・Ray Tuneハイパーパラメーター調整ツールとの統合
・複数のフレームワークのサポート(TensorFlow、PyTorch)
・新しいアルゴリズムを開発するためのスケーラブルなプリミティブ
・アルゴリズム間の共有モデル
2. 学習アルゴリズム
「RLlib」は現在、次の学習アルゴリズムを提供しています。
・Ape-X
・IMPALA
・APPO
・A2C / A3C
・DDPG / TD3
・DQN / Rainbow / Parametric DQN
・Policy Gradients
・PPO
・SAC
これらのアルゴリズムは、「OpenAI Gym」で実行できます。
3. インストール
「RLLib」は、MacOSとLinuxをサポートしています。インストールするには、Anacondaなどの仮想環境で以下のコマンドを入力してください。Rayリポジトリのクローンも行っています。
$ pip install -U ray
$ pip install -U 'ray[rllib]'
$ git clone https://github.com/ray-project/ray自分の環境で試したところ、以下のパッケージも必要になりインストールしました。
$ pip install psutil
$ pip install tensorflow4. 訓練
「RLlib」は、エージェントと環境の相互作用の「方策」を保持するクラスを提供します。エージェントのインターフェイスを介して、「方策」を訓練、保存、復元、および行動の取得ができます。
CartPole環境でDQNエージェントを訓練するコマンドは次の通りです。「--run」でアルゴリズム、「--env」で環境ID、「--checkpoint-freq」でチェックポイントの保存を指定しています。
$ python ray/python/ray/rllib/train.py --run DQN --env CartPole-v0 --checkpoint-freq 100オプションは次の通りです。
-h, --help
ヘルプの表示。
--run RUN
訓練するアルゴリズムまたはモデル。
--stop STOP
停止基準をJSONで指定。
【例】{"time_total_s": 600, "training_iteration": 100000}
--config CONFIG
アルゴリズムの環境IDやハイパーパラメータをJSONで指定。
--resources-per-trial RESOURCES_PER_TRIAL
マシンリソースをJSONで指定。
【例】{"cpu": 64, "gpu": 8}
--num-samples NUM_SAMPLES
試行を繰り返す回数。
--checkpoint-freq CHECKPOINT_FREQ
チェックポイントの保存間隔となる訓練の反復回数。
値0(デフォルト)は、チェックポイント無効。
--checkpoint-at-end
実験の最後にチェックポイントを設定するかどうか。
デフォルトはFalse。
--keep-checkpoints-num KEEP_CHECKPOINTS_NUM
保持する最後のチェックポイントの数。
その他は削除される。
デフォルト(なし)は、すべてのチェックポイントを保持。
--checkpoint-score-attr CHECKPOINT_SCORE_ATTR
最適なチェックポイントをランク付けする属性を指定。
デフォルトは昇順。
【例】min-validation_loss
--export-formats EXPORT_FORMATS
実験の最後にエクスポートされた形式のリスト。
デフォルトはなし。
--max-failures MAX_FAILURES
少なくともこれだけの回数、最後のチェックポイントからトライアルを回復。
チェックポイントが有効な場合にのみ適用される。
--scheduler SCHEDULER
FIFO(デフォルト)、MedianStopping、AsyncHyperBand、HyperBand、またはHyperOpt。
--scheduler-config SCHEDULER_CONFIG
スケジューラーに渡す構成オプション。
--restore RESTORE
指定されている場合、このチェックポイントから復元。
--ray-address RAY_ADDRESS
新しいアドレスを開始する代わりに、このアドレスで既存のRayクラスターに接続。
--ray-num-cpus RAY_NUM_CPUS
--num-cpusは、新しいクラスターを開始する場合に使用。
--ray-num-gpus RAY_NUM_GPUS
--num-gpusは、新しいクラスターを開始する場合に使用。
--ray-num-nodes RAY_NUM_NODES
デバッグ用に複数のクラスターノードをエミュレート。
--ray-redis-max-memory RAY_REDIS_MAX_MEMORY
--redis-max-memoryは、新しいクラスターを開始する場合に使用。
--ray-memory RAY_MEMORY
--memory 新しいクラスターを開始する場合に使用。
--ray-object-store-memory RAY_OBJECT_STORE_MEMORY
--object-store-memory 新規に開始する場合に使用。
--experiment-name EXPERIMENT_NAME
結果を格納する `local_dir`の下のフォルダ名。
--local-dir LOCAL_DIR
訓練結果を保存するローカルディレクトリ。
デフォルトは'/Users/furukawahidekazu/ray_results'
--upload-dir UPLOAD_DIR
訓練結果を同期するオプションのURI
【例】s3://bucket
--resume
以前のTune実験の再開を試みるかどうか。
--eager
TFのeager executionを有効にしようとするかどうか。
--env ENV
使用するGym環境。
--queue-trials
クラスターに現在試行を起動するのに十分なリソースがない場合に、試行をキューに入れるかどうか。
自動スケールアップを有効にするには、これを自動スケーリングクラスターで実行するときにTrueに設定する必要がある。
-f CONFIG_FILE, --config-file CONFIG_FILE
指定されている場合、このファイルの設定オプションを使用。
これは、上記のフラグを介して設定されたトライアル固有のオプションをオーバーライドすることに注意。デフォルトでは、「ray_resultsフォルダ」にログが出力されます。
・params.json : ハイパーパラメータ
・result.json : 各エピソードの訓練サマリー
・tensorboard log : TensorBoardのログファイル
・checkpoint : チェックポイント
以下のコマンドでTensorBoardを表示できます。
$ tensorboard --logdir=~/ray_results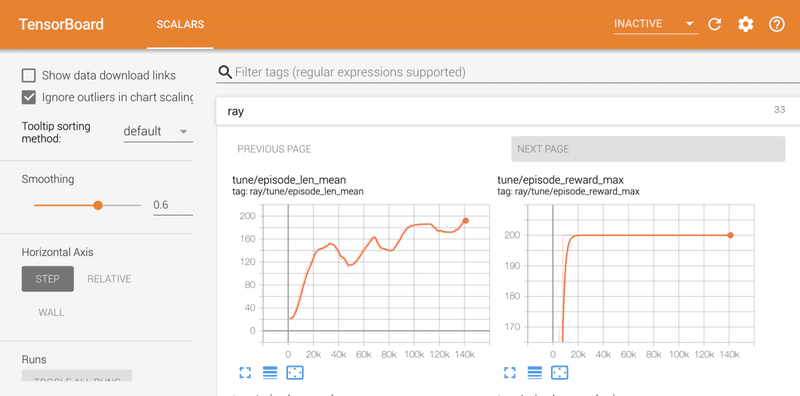
5. 評価
訓練したDQNエージェントを評価するコマンドは、次の通りです。さきほど訓練で生成したチェックポイントと、「--run」でアルゴリズム、「--env」で環境IDを指定します。
$ python ray/python/ray/rllib/rollout.py \
~/ray_results/default/DQN_CartPole-v0_0_2019-09-15_21-52-16igswpgn6/checkpoint_100/checkpoint-100 \
--run DQN --env CartPole-v0

オプションは次の通りです。
--run RUN
訓練するアルゴリズムまたはモデル。
--env ENV
使用するGym環境。
-h, --help
ヘルプの表示。
--no-render
環境のレンダリングを抑制。
--steps STEPS
ロールアウトするステップの数。
--out OUT
出力ファイル名。
--config CONFIG
アルゴリズムのハイパーパラメータをJSONで指定。
この記事が気に入ったらサポートをしてみませんか?