強化学習の価値の学習

以下の記事が面白かったので、ざっくり訳してみました。
・The Paths Perspective on Value Learning
1. はじめに
ここ数年間で、「強化学習」(RL)は、囲碁の世界チャンピオンを倒したり、ロボットハンドを制御したり、絵を描いたり、目覚ましい進歩を遂げました。
RLの主要なサブ問題の1つに、『状態の価値の推定』があります。「将来の収益」は一般的にノイズが多いため、注意が必要です。現在の状態以外の多くの影響を受けます。困難なことではありますが、RLの多くのアプローチには「価値の推定」は必要不可欠な要素になります。
2. モンテカルロ
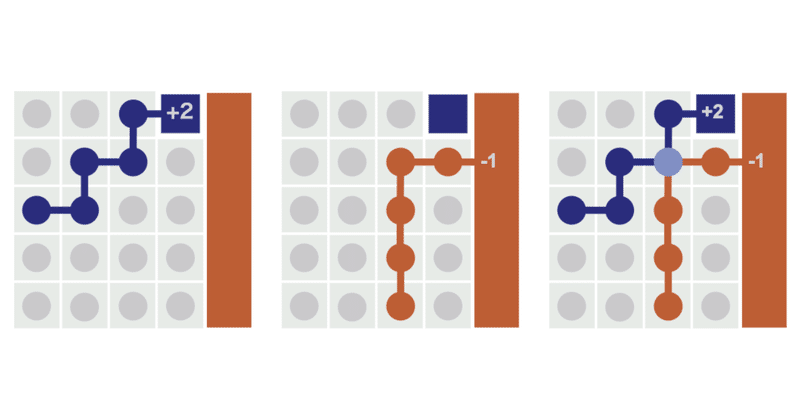
状態の価値を推定する一般的な方法は、その状態から観察する「平均収益」を計算する方法です。これを「モンテカルロ」と呼びます。
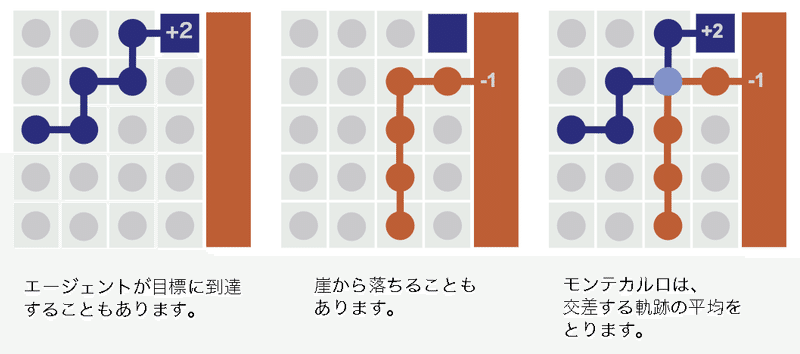
「モンテカルロ」では、ある状態が1つのエピソードのみで訪問された場合、そのエピソードの収益が状態の価値になります。複数のエピソードから訪問された場合、エピソードの収益の平均が状態の価値になります。
「モンテカルロ」の式をみてみましょう。RLでは多くの場合、「更新ルール」を使用してアルゴリズムを記述します。これにより、1つ以上のエピソードで価値の推定がどのように変化するかがわかります。更新演算子(↩)を使用して、方程式をシンプルに表現します。

「R」は収益で、将来にわたってエージェントが獲得する報酬和になります。

「γ」は割引率で、短期報酬が長期報酬に比べてどれだけ価値があるかを示します。収益を更新することによって、価値を推定することは理にかなっています。
結局のところ、価値とは『収益の期待値』になります。
3. TD学習
これ以上良い方法はないと思われる「モンテカルロ」ですが、これより良い方法があります。それが「TD学習」です。
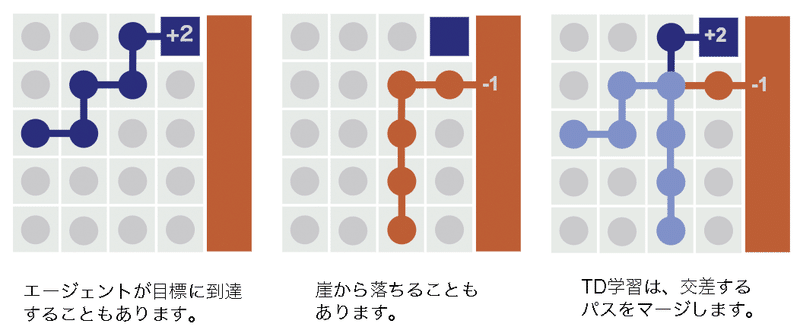
「TD学習」では、近くの状態からブートストラップして価値を更新します。

「モンテカルロ」と「TD学習」は、2つの軌跡間の交点の処理が異なります。「TD学習」では軌跡の交点がマージされるため、収益はそれ以前のすべての状態に逆流します。
「軌跡のマージ」とはどういう意味で、なぜそれが良いアイデアなのでしょうか。V(s_{t + 1})は、すべてのTD学習の更新に対する期待値として記述できます。
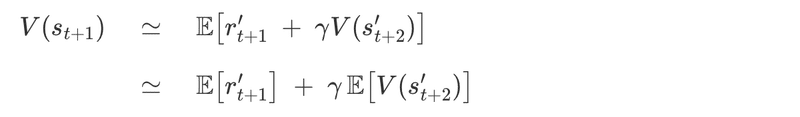
この方程式を使用して、TD学習の更新を再帰的に展開できます。
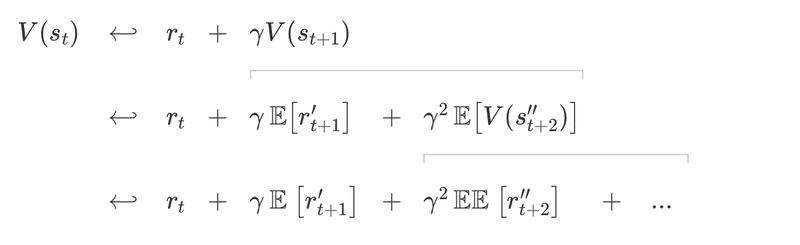
これにより、入れ子になった期待値の合計が得られます。「モンテカルロ」の更新を報酬の観点から書き直し、「TD学習」の更新の横に配置しましょう。

これで比較しやすくなりました。
「モンテカルロ」と「TD学習」の違いは、入れ子になった「期待演算子」にあります。これらが何をしているのかについて、見た目の良い解釈があることがわかりました。私たちはそれを『価値学習のパス』と呼んでいます。
4. 軌跡とパス
「エージェントの経験」は「一連の軌跡」として考えることがよくあります。グループ化は論理的で視覚化が容易になります。
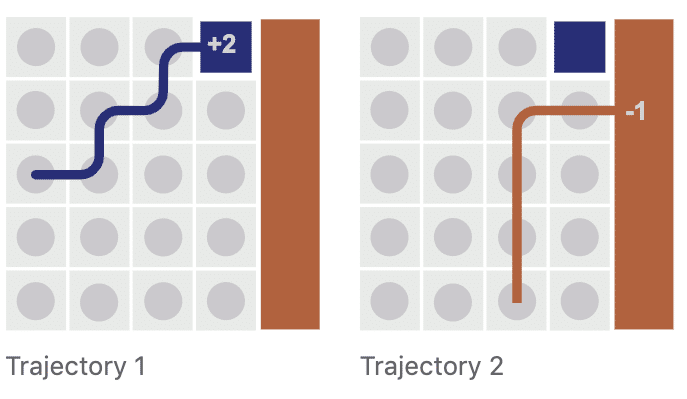
エージェントが「軌道1」をたどって交点に到達した場合でも、理論的にはその交点から「軌道2」をたどることができます。このようなシミュレートされた軌跡によって、経験を劇的に増やすことができます。このシミュレートされた軌跡のことを「パス」と呼びます。
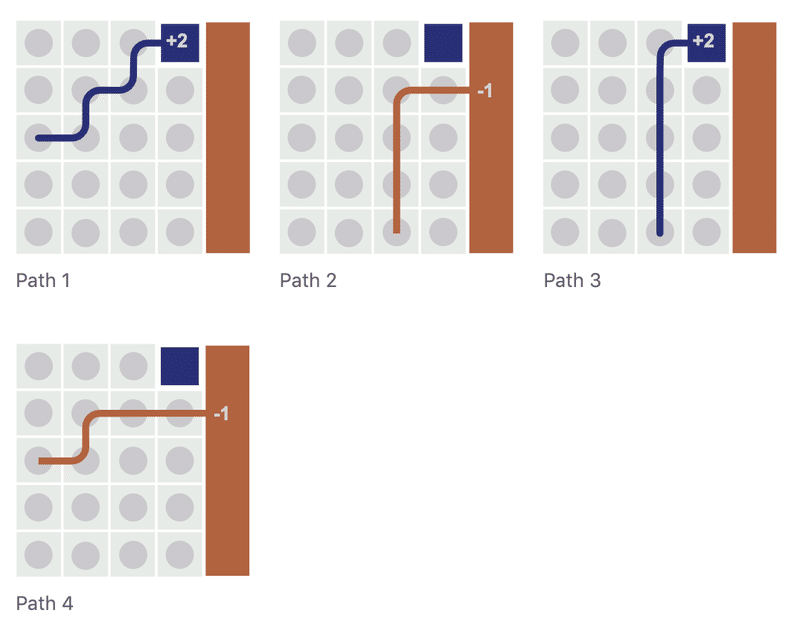
推定価値は、「モンテカルロ」では実際の「軌跡」で平均化されているのに対し、「TD学習」は可能なすべての「パス」で平均化されています。
以前に見た入れ子の期待値は、可能なすべての「パス」の平均化に対応します。
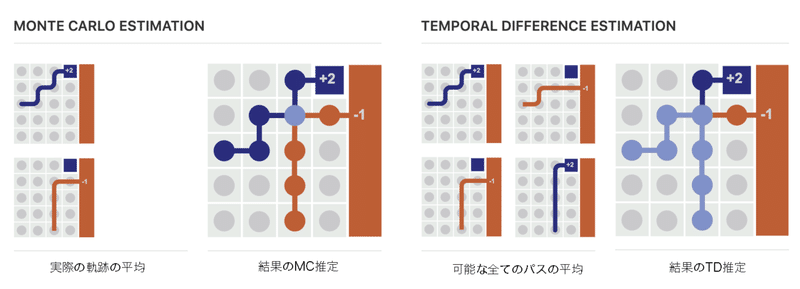
一般的に、最良値の推定価値は、分散が最小のものです。表形式の「TD学習」と「モンテカルロ」は経験的平均であるため、より良い推定価値を与える方法は、より多くの経験で平均することになります。軌跡を利用する「モンテカルロ」より、パスを利用する「TD学習」の方が経験が多くなります。
この一連の推論は、「TD学習」がより良い推定平均であることを示唆し、「TD学習」が表環境で「モンテカルロ」を上回る傾向がある理由を説明するのに役立ちます。
5. Q関数
「価値関数」の代わりになるものとして、「Q関数」があります。「任意の状態の価値」を推定する代わりに、「任意の状態の任意の行動の価値」を推定します。「Q関数」を使用する最も大きな理由は、「行動を比較できること」になります。

「Q関数」には他にも便利な機能がいくつかあります。Q学習による「モンテカルロ」と「TD学習」の更新ルールを見てみましょう。
「モンテカルロ」の更新ルールは、V(s)とほぼ同じに見えます。収益で更新します。ただし、任意の状態の価値を更新する代わりに、任意の状態の任意の行動の価値を更新します。

「TD学習」の更新ルールは次のようになります。
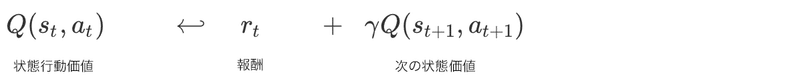
このTD学習の更新ルールには、(s_t, a_t, r_t, s_{t+1}, a_{t+1})が必要になるため、「Sarsa」と呼びます。「Sarsa」はこの「TD学習」の更新ルールを記述する最も簡単な方法かもしれませんが、最も効率が悪い方法です。「Sarsa」の問題は、次の状態価値のために、V(s_{t+1})を使うべき時に、Q(s_{t+1}, a_{t+1})を使用することです。推論に必要なのはV(s_t+1)です。

Q関数をV(s_{t+1})にする方法はたくさんあります。次のセクションでは、そのうちの4つを詳しく見ていきます。
6. 重み付けしたパスを利用したQ関数
◎Expected Sarsa
次の状態の値を推定するより良い方法は、「Q関数」の重みの合計を使用することですこのアプローチを「Expected Sarsa」と呼びます。

「Expected Sarsa」で求める推定価値は、経験から直接計算されたものよりもしばしば良いです。これは、期待値が経験のポリシー分布ではなく、真のポリシー分布によってQ値を重み付けするためです。これを行う際に、「Expected Sarsa」は、経験的なポリシー配布と真のポリシー配布の違いを修正します。
このアイデアをさらに推し進めることができます。真のポリシー分布でQ値を重み付けする代わりに、任意のポリシーπ^{off}で重み付けすることができます。
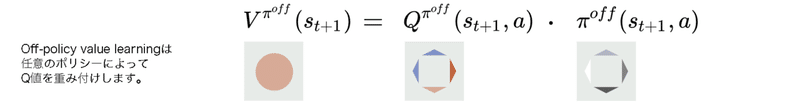
このわずかな変更により、好きなポリシー下で価値を見積もることができます。「Expected Sarsa」を、オンポリシー推定のために使用されるオフポリシー学習の特別なケースとして考えるのは興味深いことです。
次に、複数の経験のパスが交差する状態を考えてみましょう。
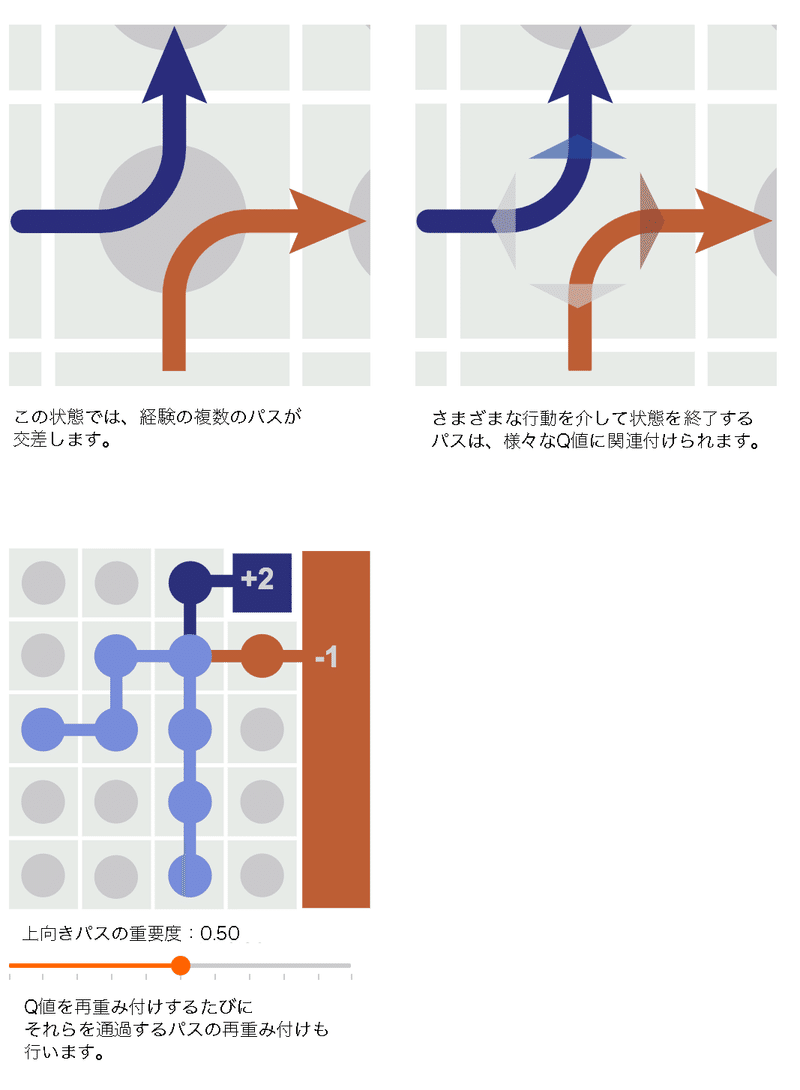
交差するパスが再重み付けされる場合は常に、オフポリシーの分布の最も代表するパスが、推定価値により大きく貢献します。一方、確率が低いパスの寄与は小さくなります。
◎Q-learning
エージェントは、最適なポリシー下で価値を推定しながら、準最適なポリシー下で経験を収集する必要がある場合があります。これらの場合、「Q-learning」と呼ばれるオフポリシー学習を使用します。
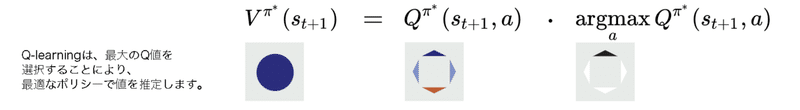
「Q-learning」は、最も価値の高いパスを除くすべてを除去します。残っているパスは、テスト時にエージェントがたどるパスです。それらは注意を払う必要がある唯一のものになります。この種の価値学習は、多くの場合、ポリシーに基づく方法よりも高速な収束につながります。
◎Double Q-Learning
「Q-learning」の問題は、バイアス値の推定価値を提供することです。より具体的には、ノイズの多い報酬が存在する場合、楽観的になります。「Q-learning」が失敗する例を次に示します。
あなたはカジノに行き、100台のスロットマシンをプレイします。それはあなたの幸運な日です。マシン43で大当たりします。
今度は、「Q-Learning」を使用してカジノにいる価値を推定する場合、スロットマシンをプレイする行動よりも最良の結果を選択します。あなたは、カジノの価値は大当たりの価値であると考えてしまいます。
そしてカジノは素晴らしい場所であると決めます。
状態の最大Q値が偶然大きい場合もあります。他のものよりもそれを選択すると、推定価値に偏りが生じます。この偏りを減らす方法の1つは、友人にカジノを訪問して、同じスロットマシンのセットをプレイさせることです。次に、マシン43での賞金が何であったかを彼らに尋ね、その応答をあなたの価値の見積もりとして使用します。両方が同じマシンでジャックポットを獲得した可能性は低いため、今回は過度に楽観的な見積もりになりません。このアプローチを「Double Q-learning」と呼びます。
◎学習アルゴリズムの比較
「Sarsa」「Expected Sarsa」「Q-learning」「Double Q-learning」を異なるアルゴリズムと考えるのは簡単です。しかしこれまで見たように、それらはTD更新によってV(s_{t+1})を推定する方法です。

これらすべてのアプローチの背後にある直観は、パスの交差点を再重み付けすることです。
◎モンテカルロを使用したパスの再重み付け
「モンテカルロ」で同じ再重み付け効果を達成することはできます。しかし、それは面倒であり、エージェントのすべての経験を再重み付けする必要があります。交点で作業することにより、「TD学習」はエピソード全体ではなく個々のトランジションの重みを再設定します。これにより、「オフポリシー学習」にとって「TD学習」がはるかに便利になります。
6. 関数近似によるパスのマージ
これまで、すべての状態またはすべての状態と行動のペアに対して1つのパラメータ(推定価値)を学習しました。「Cliff World」の例では、状態の数が少ないため、これはうまく機能します。しかし、最も興味深いRL問題には、多数または無限の状態があります。これにより、各状態の推定価値を保存することが難しくなります。
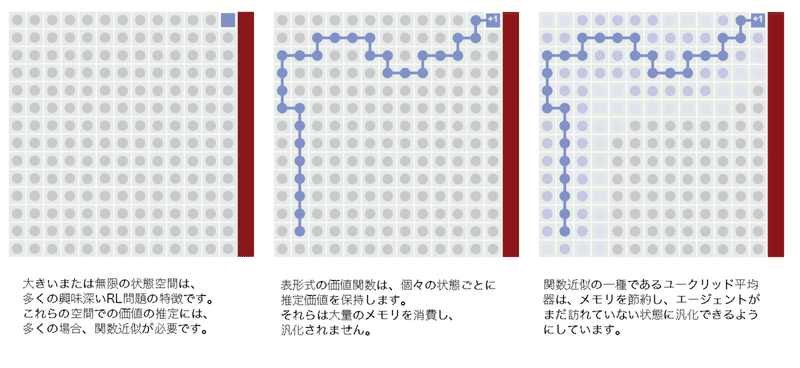
代わりに、価値推定器に状態よりも少ないパラメータを強制する必要があります。これには、「線形回帰」「決定木」「ニューラルネットワーク」などの機械学習法を使用できます。これらの方法はすべて、関数近似の傘下にあります。
◎近くのパスのマージ
関数近似を近くのパスをマージする方法として解釈できます。しかし、「近く」とはどういう意味でしょうか。図では、ユークリッド距離で「近傍」を測定する暗黙の決定をしました。これは、2つの状態間のユークリッド距離が、エージェントが状態間を遷移する確率と高い相関があるため、良いアイデアでした。
ただし、この暗黙の仮定が破綻するケースは容易に想像できます。単一の長いバリアを追加することにより、ユークリッド距離メトリックが一般化につながるケースを構築できます。問題は、間違ったパスをマージしたことです。
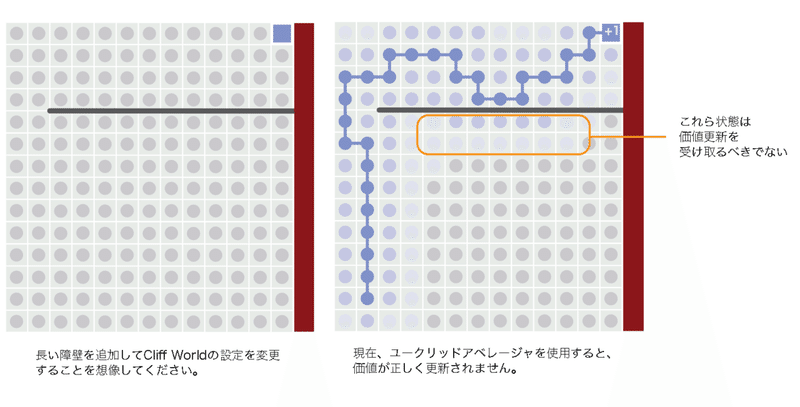
◎間違ったパスのマージ
図は、間違ったパスをもう少し明示的にマージした結果を示しています。ユークリッドアベレージャは一般化の悪さのせいなので、「モンテカルロ」と「TD学習」の両方が悪い値の更新を行います。ただし、「TD学習」はこれらのエラーを劇的に増幅しますが、「モンテカルロ」は増幅しません。
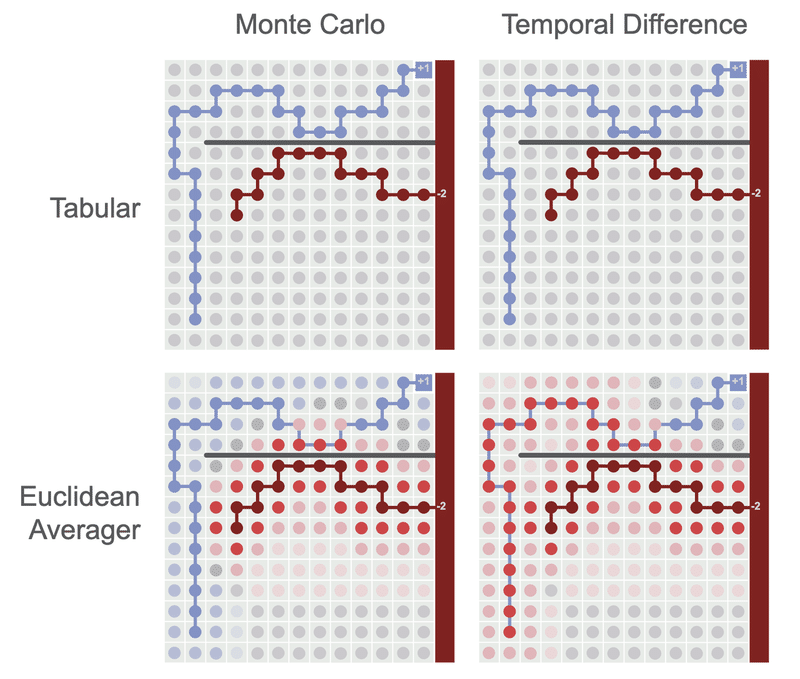
「TD学習」は、より効率的な値の更新を行うことがわかりました。私たちが支払う代価は、これらの更新が悪い一般化に敏感になることです。
7. 深層強化学習
◎ニューラルネットワーク
ディープニューラルネットワークは、おそらく強化学習の最も一般的な関数近似器です。これらのモデルは多くの理由で刺激的ですが、特に素晴らしい特性の1つは、どの状態が「近く」にあるかについて暗黙の仮定を立てないことです。
訓練の初期段階では、平均化者のようなニューラルネットワークは、誤った経験の経路をマージする傾向があります。「Cliff Walking」の例では、訓練されていないニューラルネットワークはユークリッドアベレージャーと同じ悪い価値の更新を行う可能性があります。
しかし、訓練が進むにつれて、ニューラルネットワークは実際にこれらのエラーを克服することを学ぶことができます。どの状態が「近く」にあるかを経験から学びます。「Cliff World」の例では、完全に訓練されたニューラルネットワークが、バリアを超える状態の価値の更新がバリアを下回る状態の価値に決して影響を与えないことを学習することを期待できます。これは、他のほとんどの関数近似ができることではありません。ディープRLが非常に興味深い理由の1つです。

◎TDまたはTD以外
これまで、「TD学習」が交差する場所で経験のパスをマージすることにより、どのように「TD学習」が「モンテカルロ」よりも優れているかを見てきました。また、パスのマージは両刃の剣であることがわかりました。関数近似により悪い価値が更新されると、「TD学習」のパフォーマンスが悪化する可能性があります。
過去数十年にわたって、RLのほとんどの研究は、「モンテカルロ」よりも「TD学習」を優先してきました。実際、RLへの多くのアプローチはTDスタイルの値の更新を使用します。そうは言っても、「モンテカルロ」を強化学習に使用する方法は他にもたくさんあります。この記事では、価値推定のための「モンテカルロ」を中心に議論していますが、Silver et al.のようにポリシー選択にも使用できます。
「モンテカルロ」と「TD学習」はどちらも望ましい特性を持っているので、この2つを合わせて価値推定するというアプローチもあります。それが「TD(λ)学習」です。これは単純に「モンテカルロ」と「TD更新」の間を補間する手法で、多くの場合、「TD(λ)学習」は「モンテカルロ」「TD学習」よりも優れた動作をします。
8. 結論
この記事では、「TD学習」について考える新しい方法を紹介しました。「TD学習」が有益である理由、オフポリシー学習に効果的である理由、TD学習を関数近似器と組み合わせることに課題がある理由を理解するのに役立ちます。
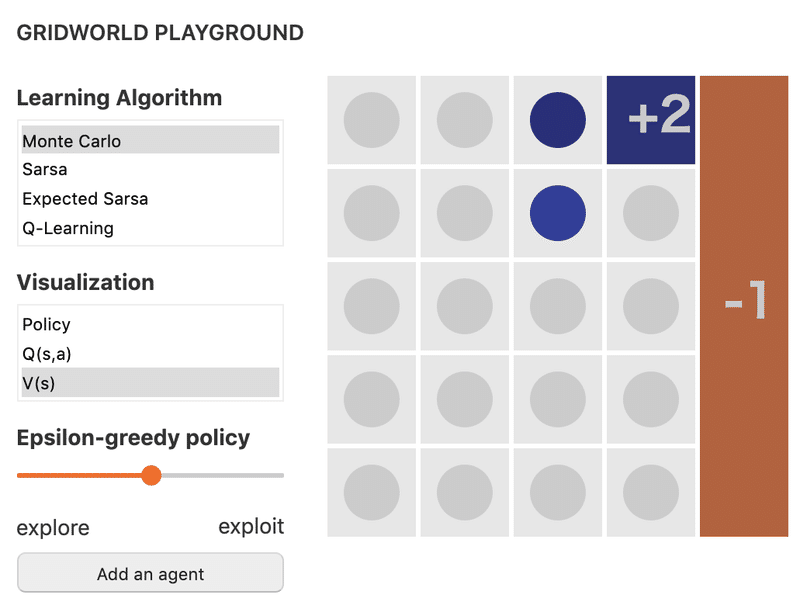
以下のプレイグラウンドを使用して、これらの直感に基づいて構築するか、独自の実験を試みることをお勧めします。
以下はスクリーンショットです。本家のサイトで試してください。
この記事が気に入ったらサポートをしてみませんか?