
ソニックへの世界モデルの適用

以下の記事が面白かったので、簡単にまとめました。
1. 要約
「OpenAI」は、2018年4月5日に「Retro Contest」と呼ばれる強化学習コンテストを開催しました。目標は、メガドライブのアクションゲーム「ソニック・ザ・ヘッジホッグ」をプレイする最高のエージェントを作ることでした。問題の理解は簡単ですが、解決は非常に困難です。エージェントの評価は、エージェントが見たことのないレベル(面)で行われるため、「メタ強化学習」の問題になります。
この記事では、同様の問題を解決するために使用されている最近公開された技術を適用することにより、この問題にどのように取り組んだかを紹介します。実装を参照するため、機械学習とPythonの知識が必要です。
2. はじめに
約3〜4週間前(5月10日)に「Retro Contest」を開始しました。ソフトウェア開発の自習者および学生としての機械学習とディープラーニングに関する一般的な知識があります。大規模な強化学習の問題に関する唯一の他の経験は、PyTorchを使用して「AlphaGo Zero」をゼロから実装したことです。
「Retro Contest」のガイドラインに従って開始し、ランダムポリシーを使用して最初のエージェントを送信しました。問題に対する適切な答えを定式化する手法について考えはじめた時、「PPO」「DQN」「TRPO」など、いくつかのアイデアが思い浮かびました。しかし、これらのアルゴリズムは既にその価値が証明されていました。成功を得られないとしても、別の手法を試してみたいと考えました。
コンテストをはじめる数週間前に、「世界モデル」に関する論文を読みました。論文を読む前に同様のアプローチを考えていましたが、実際に自分で実験したことはありませんでした。そのため、この興味深いアプローチを具体的な問題に適用するのに、最適なタイミングだと考えました。
3. 世界モデル
「世界モデル」のアルゴリズムは、「Visual」「Memory」「Control」の3つの主要コンポーネントに分かれています。基本的な考え方は非常にエレガントです。
人間として、時間であろうと、空間であろうと、住んでいる世界の「抽象表現」を学びます。概念について考えるときに、概念を大まかに視覚化することができます。あなたに、ソニックのレベル(面)がどのように見えるかを視覚化するように頼むとしましょう。ソニックを知ってるなら、おそらくレベルの全てのピクセルを思い描くのではなく、レベルの大まかなスケッチを考えているでしょう。知らない人は、以下のゲーム画面を見てください。

今思い浮かべたレベルでソニックがどのように行動するか想像してみてください。おそらく、ソニックがレベルを攻略する様子を見ることができるでしょう。
この論文の目的は、この美しいアーキテクチャを再現することでした。「CarRacing-v0」と「Doom」の2つの環境で成功しました。目標は、このアーキテクチャを「ソニック」に適用しようとすることでした。
4. Visual Model
◎ コンセプト
空間の「抽象表現」を作成する「Visual Model」は、「オートエンコーダ」と呼ばれます。「オートエンコーダ」は、「エンコーダ」と「デコーダ」の2つのコンポーネントで構成されています。
「エンコーダ」の仕事は、観察(ソニックの場合は画面イメージ)を、はるかに小さい次元に圧縮することです。通常は環境の複雑度に応じて10〜300次元、論文の「Doom」では64次元に圧縮します。
「デコーダ」の仕事は、圧縮されたベクトルから元の画面イメージを再作成することです。
この論文で使用されている「オートエンコーダ」のバリアントは「Variation Autoencoder」(VAE)と呼ばれます。以下は、このテーマに関する優れたリソースです。
・Tutorial - What is a variational autoencoder? – Jaan Altosaar
画面イメージを潜在変数 z に直接エンコードする代わりに、エンコーダは画面イメージを平均μと標準偏差σの正規確率分布に圧縮しようとします。また、モデルの入力は画像であるため、ピクセル値を直接利用する代わりに、畳み込みを使用することが論理的に思われました。ソニックのレベルのより堅牢な表現を得るために、「β-VAE」のバリアントを実装することにしました。
◎ コード
コードを見てみましょう。
ゲームから取得した画面イメージが「64x64x3」ではなく「128x128x3」なため、レイヤーが1つ増えていますが、アーキテクチャは論文で提案されたものに従います。
class ConvVAE(nn.Module):
def __init__(self, input_shape, z_dim):
super(ConvVAE, self).__init__()
## エンコーダ
self.conv1 = nn.Conv2d(3, 32, 4, stride=2)
self.conv2 = nn.Conv2d(32, 64, 4, stride=2)
self.conv3 = nn.Conv2d(64, 128, 4, stride=2)
self.conv4 = nn.Conv2d(128, 256, 4, stride=2)
## 平均と標準偏差の潜在変数
self.fc1 = nn.Linear(256 * 6 * 6, z_dim)
self.fc2 = nn.Linear(256 * 6 * 6, z_dim)
self.fc3 = nn.Linear(z_dim, 256 * 6 * 6)
## デコーダ
self.deconv1 = nn.ConvTranspose2d(256 * 6 *6, 128, 5, stride=2)
self.deconv2 = nn.ConvTranspose2d(128, 64, 5, stride=2)
self.deconv3 = nn.ConvTranspose2d(64, 32, 5, stride=2)
self.deconv4 = nn.ConvTranspose2d(32, 16, 6, stride=2)
self.deconv5 = nn.ConvTranspose2d(16, 3, 6, stride=2)はじめに、「レイヤー」を定義します。まず、「VAE」の平均と標準偏差を表す2つの線形ベクトルにマッピングされる4つの畳み込みを定義します。次に、出力(平均、標準偏差)を取得し、「デコーダ」の入力となるベクトルにマップする別の線形レイヤーを追加します。「デコーダ」は、損失関数を計算するために、入力画像のサイズに合わせて画像を再構築します。
次に、「フォワードパス」を定義します。
def encode(self, x):
h = F.relu(self.conv1(x))
h = F.relu(self.conv2(h))
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = h.view(-1, 256 * 6 * 6)
return self.fc1(h), self.fc2(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return eps * std + mu
def decode(self, z):
h = self.fc3(z).view(-1, 256 * 6 * 6, 1, 1)
h = F.relu(self.deconv1(h))
h = F.relu(self.deconv2(h))
h = F.relu(self.deconv3(h))
h = F.relu(self.deconv4(h))
h = F.sigmoid(self.deconv5(h))
return h
def forward(self, x, encode=False, mean=True):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
if encode:
if mean:
return mu
return z
return self.decode(z), mu, logvaencode()とdecode()は、その名前が示すとおりです。reparameterize()は、訓練中に平均と標準偏差からサンプリングするために使用されます。推論する時は平均を使用することをお勧めします。ただし、空間の時間依存性をモデル化する方法を学習する際に、「Memory Model」が特定の潜在変数 z に過剰適合しないように、推論中でもサンプリングを使用します。
最後は「損失関数」を定義します。
def loss_fn(recon_x, x, mu, logvar):
batch_size = x.size(0)
loss = F.binary_cross_entropy(recon_x, x, size_average=False)
kld = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
loss /= batch_size
kld /= batch_size
return loss + BETA * kld.sum()「β-VAE」の損失関数は次のように定義します。
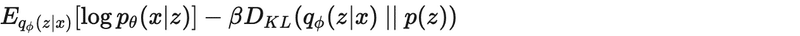
左の項は、予測された画面イメージが元の画面イメージからどれだけ近いかを測定する限界尤度、右の項は、予測された画面イメージが元の画面イメージからどのように発散するかの尺度であるカルバック・ライブラー発散(または相対エントロピー)です。p(z)およびq_φ(z|x)という仮定の下で、確率分布と見なされます。また、損失の各成分をバッチ内の例の数で正規化して、より代表的な値を取得しています。
5. Memory Model
◎ コンセプト
「Memory Model」は、行動によって引き起こされる時間経過に伴う「空間変化の表現」を担当します。時系列の一般的なモデルは、「Recurrent Nural Network」(RNN)と呼ばれます。時間を表現するために、自身の予測結果を入力ソースとして使用するため「Recurrent」と呼ばれます。
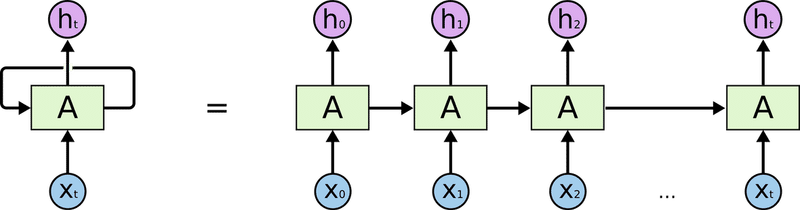
ただし、「Vanilla RNN」(改良なしのRNN)にはいくつかの欠点があります。1つ目は、コンテキストがシーケンスのかなり後ろに戻ることがあるため、長期的な依存関係をモデル化するのが苦手であることです。2つ目は、勾配消失問題です。これは、RNNに適用される逆伝播アルゴリズム(BPTT)によって引き起こされます。「ReLU」「GRU」などのいくつかの手法がこれらの問題に対処できます。
「世界モデル」の論文では、「Long Short Term Memory」(LSTM)で対処しています。この件に関して非常によく書かれた記事を以下に示します。
「LSTM」を使用するだけでなく、「Mixed Density Network」(MDN)によって、単一の入力に対して複数の出力を行います。現在のエンコードされたフレーム(エンコーダの出力)とエージェントが実行している行動になります。ネットワークが特定の数の正規確率分布のパラメータと、予測された各ガウスが潜在変数 z_{t+1} の最終予測にどれだけ貢献するかを表す確率ベクトルを出力するため、「Mixed Density」と呼ばれます。以下は、この件に関して非常によく書かれた別の記事です。
◎ コード
今回は、「Doom」実験に512の隠れ層と5つの混合ガウス分布を使用したことを除いて、アーキテクチャの完全な説明を提案しませんでした。のちに、訓練中にかなり長いシーケンス長(1000)を使用していることがわかりました。
class LSTM(nn.Module):
def __init__(self, sequence_len, hidden_units, z_dim, num_layers, n_gaussians, hidden_dim):
super(LSTM, self).__init__()
self.n_gaussians = n_gaussians
self.num_layers = num_layers
self.z_dim = z_dim
self.hidden_dim = hidden_dim
self.hidden_units = hidden_units
self.sequence_len = sequence_len
self.hidden = self.init_hidden(self.sequence_len)
## エンコーディング
self.fc1 = nn.Linear(self.z_dim + 1, self.hidden_dim)
self.lstm = nn.LSTM(self.hidden_dim, hidden_units, num_layers)
## 出力
self.z_pi = nn.Linear(hidden_units, n_gaussians * self.z_dim)
self.z_sigma = nn.Linear(hidden_units, n_gaussians * self.z_dim)
self.z_mu = nn.Linear(hidden_units, n_gaussians * self.z_dim)
def init_hidden(self, sequence):
hidden = torch.zeros(self.num_layers, sequence, self.hidden_units, device=DEVICE)
cell = torch.zeros(self.num_layers, sequence, self.hidden_units, device=DEVICE)
return hidden, cell繰り返しますが、レイヤーの定義が最初になります。LSTMレイヤーを通過する前に、潜在変数 z_t が線形レイヤーを通過して、モデルが潜在変数の上に独自の非線形表現を作成できるようにします。その後、LSTMレイヤーにマップされ、時間エンコードされたベクトルが出力されます。このベクトル自体は、各混合の各値の確率、平均μ、分散σであるMDNの3つのコンポーネントにマッピングされます。
「フォワードパス」は比較的単純です。
def forward(self, x):
self.lstm.flatten_parameters()
x = F.relu(self.fc1(x))
z, self.hidden = self.lstm(x, self.hidden)
sequence = x.size()[1]
pi = self.z_pi(z).view(-1, sequence, self.n_gaussians, self.z_dim)
pi = F.softmax(pi, dim=2)
sigma = torch.exp(self.z_sigma(z)).view(-1, sequence, self.n_gaussians, self.z_dim)
mu = self.z_mu(z).view(-1, sequence, self.n_gaussians, self.z_dim)
return pi, sigma, mu隠れ層が更新され、確率がsoftmaxで計算され、分散σが累乗されます。これら3つのベクトルはすべて、(batch_size、sequence_length、n_gaussians、latent_dimension)に対応するように整形されます。
次に、「損失関数」を定義します。
def mdn_loss_function(out_pi, out_sigma, out_mu, y):
y = y.view(-1, SEQUENCE, 1, LATENT_VEC)
result = Normal(loc=out_mu, scale=out_sigma)
result = torch.exp(result.log_prob(y))
result = torch.sum(result * out_pi, dim=2)
result = -torch.log(EPSILON + result)
return torch.mean(result)予測ベクトルは、多変量ガウス分布に変換されます。ターゲット(これは次フレームの潜在変数 z_ {t + 1})の真の潜在変数について評価され、各混合の確率ベクトルが適用されます。最後に、混合物が合計され、対数(-∞を避けるために小さな定数を使用)が適用され、この値がbatch_sizeによって正規化されて最終的な損失値が得られます。ただし、これは数値的に安定していません(softmaxの対数)。しかし、論文では相関パラメータρはモデル化されていないため、数値的に安定したバージョンを実装することが可能です。
6. Controller Model
◎ コンセプト
「Controller Model」は、環境内で行動を実行します。
この論文では、フレームの現在の潜在変数 z_t と「LSTM」の隠れ状態とセルの連結を行動にマッピングする単一の線形層を持つ単純なニューラルネットワークです。環境によっては、出力の形状が少し異なる場合があります。
最後にsoftmax操作で離散値を使用するなど、モデルの出力をソニック環境に適合させるためのさまざまなアプローチを試しましたが、うまく機能しないようでした。また、双曲線正接値 (-1, 1) を出力して、行動を表す同等の可能性のあるセグメントに分割しましたが、どちらも機能しませんでした。最善の方法は、ゲームに影響を与えるSEGAコントローラーの独立したボタンごとにシグモイド値を予測することでした。このwikiに示されているように、UPボタンはまったく使用しません。Bと同じ行動を実行するAボタンとCボタンについても同様です。特定のしきい値(0.5)よりも大きな値を持つすべてのボタンを押すことで、行動を実行しました。
環境でエージェントを訓練するためにこの論文で使用された方法は、「Covariance Matrix Adaptation Evolution Strategy 」(CMA-ES)と呼ばれる進化的アルゴリズムです。 以下に、hardmaruによって書かれた本当に素晴らしいガイドがあります。
このアルゴリズムには、状況に応じて検索空間を適応的に増減できる動的標準偏差があるという特殊性があります。彼らは、この進化的手法を使用して、エージェントが環境で最高のパフォーマンスを発揮するパラメーターのセットを見つけました。
フィットネス関数(エピソード中のエージェントのパフォーマンスの計算を行う関数)は、OpenAIによって定義されています。「水平オフセット」(レベルのx座標)と「完了ボーナス」で計算します。
◎ コード
「Controller Model」は、8896の重みパラメータ(200次元の潜在変数、非表示状態に1024 * 2、行動空間にLSTM * 4のセル)を持つ単一の線形レイヤーで構成されています。 pycmaのもう1つは、検索空間が10000個のパラメータを超えないようにする必要があります。
class Controller(nn.Module):
def __init__(self, hidden_dim, action_space):
super(Controller, self).__init__()
self.fc1 = nn.Linear(hidden_dim, action_space)
def forward(self, x):
x = F.sigmoid(self.fc1(x))
return x「pycma」というパッケージを使用し、「es.py」という「hardmaru」の小さなラッパーを少し変更しました。アルゴリズムは、populationサイズ(各タイムステップで生成されるパラメーターセットの数)と初期標準偏差を使用して、次のようにインスタンス化されます。
solver = CMAES(PARAMS_CONTROLLER, ## パラメータ数
sigma_init=SIGMA_INIT,
popsize=POPULATION)フィットネスシェーピング関数は、フィットネススコアを [1, len(x)] にランク付けし、サンプル数で正規化し、最終的に [-0.5, 0.5] の範囲にスケーリングします。これにより、アルゴリズムは、本当に高いスコアを達成し、したがって検索空間の最適化フェーズで勾配計算を支配する外れ値を回避できます。
def compute_ranks(x):
"""
[0, len(x))のランクを返す
注:これは、scipy.stats.rankdataとは異なる
ranks in [1, len(x)].
"""
assert x.ndim == 1
ranks = np.empty(len(x), dtype=int)
ranks[x.argsort()] = np.arange(len(x))
return ranks
def rankmin(x):
y = compute_ranks(x.ravel()).reshape(x.shape).astype(np.float32)
y /= (x.size - 1)
y -= .5
return y7. 訓練と実行
モデルの「コンセプト」と「コード」を定義できたので、実際の訓練に移ります。
◎ データの生成
論文では、ランダムポリシーを使用して、後で「V」および「M」を訓練するために必要なペア(フレーム、行動)を生成することを推奨しています。
最初に「JERK」(Just Enough Retained Knowledge:Baselinesリポジトリから取得。主に右にジャンプし、時々左に少し逆戻りしながらジャンプ)を実行して、このアプローチを試しました。
ただし、エージェントは比較的速くスタックするため、特定のフレームが他のフレームよりも頻繁に表示されるため、フレームの分布はエージェントがスタックする場所に偏ります。この問題を克服するために、「JERK」の代わりに人間の記録を使用してデータを生成し(Discordのunixpickleで推奨)、フレームのより良い分布を取得します。また、「JERK」では他の方法では探索できなかったレベルの一部を見ることができます。主に使いやすさ(MongoDBを使用するPythonの数行のみ)のために、データベースに2500タプル(フレーム、行動、報酬)の単位でデータを保存することを選択しました。
◎ 訓練の手順
訓練の手順には、いくつか方法かあります。各モデルを個別に訓練することにしました。「VAE」と「LSTM」の両方で、学習率10^{-3}のオプティマイザ「Adam」を使用しました。
より良い潜在変数 z を強制するために、200次元の潜在変数、300フレームのbatch_size(128 x 128 x 3)、β値4を使用して「VAE」の訓練を開始しました。訓練は約2日間続き、400kのバッチ反復を行いました。
一方、LSTMの訓練も始めました。モデルのハイパーパラメータを調整しようとしましたが、最後のバージョンでは、最初の線形レイヤーで1つのLSTMレイヤー、8つのガウス分布、1024の隠れ層、1024ユニットを使用しています。また、500次元の潜在変数 z のシーケンスを使用して、より多くの時間依存性をキャプチャできるようにしました。500次元の潜在変数の40kシーケンスをおよそ表す14時間〜(提出期限)の間、それを訓練することができました。
ターゲットベクトルを作成できるように、ターゲットを1フレーム左にシフトし、最後のフレームを複製しました。重複することなく、より大きなシフトを使用しようとしましたが、結果はそれほど良くありませんでした。また、生のフレームをGPUメモリにロードする代わりに、各フレームのμおよびσが保存され、訓練バッチの構築中に新しい潜在変数がサンプリングされました。
「オンライン」の訓練を行っていないため、数エポックごとに更新されてデータセットのごく一部(最大5〜10%)を置き換える「rotating buffer」も用意しました。詳細については、このコードを確認してください。
最後のコンポーネントである「Controller」は、経験上最も訓練が難しいコンポーネントです。最初にしたことは、計算を高速化するために、特定のパラメータセットを評価するためのマルチプロセッシングを実装することでした。また、特定のタイムステップ(300〜600ステップ、15フレーム/秒のゲームで20〜40秒に相当)を使用して報酬の移動平均を計算するなど、計算を節約するための「early stopping」も追加しました。平均報酬が特定のしきい値(ほとんどの実験で10)を超えない場合、エージェントが停止します。特定のスコアが達成されるまで、最初のレベル(GreenHillZone Act 1および2)のみを反復する、「カリキュラム学習」のアプローチを使用してみました。これらのレベルでは、報酬はより早く取得する傾向があり、エージェントはソニックの最も基本的な概念を習得できるので、障害物をうまく飛び越えてジャンプするのが一般的です。数回の試行の後、エージェントがゲームのより良い、より堅牢なビジョンを徐々に構築するように、ランダムなアプローチに切り替えることにしました。しかし、執筆時点では、一方が他方より優れているかどうかを評価できるほど十分な訓練時間がありませんでした。
「CMA-ES」モデルと「Controller」モデルのハイパーパラメータについては、80のpopulationを使用し、5つのロールアウトの平均累積報酬を時間または報酬不足のいずれかの完了まで取得することにより、20候補の解決方法を並行して評価しました。「世界モデル」の論文では、CarRace環境でスコアを達成するまでに、1000世代(サイズ64の母集団と16のロールアウトの平均)かかりました。できる世代の最大数は、提出期限までに約80でした。
◎ エージェントのロールアウト
エージェントは、以下で説明するロジックを使用して環境で再生します。Python擬似コードで記述しています。完全なロジックについてはこちらを参照してください。
def rollout(env, vae, lstm, controller):
done = False
obs = env.reset()
mov_avg_reward = []
total_reward = 0
total_steps = 0
while not done and total_steps < MAX_STEPS:
if total_steps % SEQUENCE == 0:
lstm.hidden = lstm.init_hidden(1)
z = vae(obs)
action = controller([z, lstm.hidden])
obs, reward, done = env.step(action)
_ = lstm([z, action]) ## Hidden state updated in forward pass
if len(mov_avg_reward) == REWARD_BUFFER:
if np.mean(mov_avg_reward) <= REWARD_THRESHOLD:
break
mov_avg_reward.insert(0, reward)
mov_avg_reward.pop()
else:
mov_avg_reward.append(reward)
total_steps += 1
total_reward += reward「LSTM」の非表示状態は、特定のフレーム数(訓練中に使用した量と同じ)の後にのみ再初期化されます。また、フォワードパス中に更新されるため、LSTM予測の戻り値が使用されません。
8. 結果
全てのパズルのピースが配置されました。コンポーネントを個別に見て、モデルが達成した最終結果を見てみましょう。
◎ VAE
「VAE」は、ソニックがすべてのフレームで再発するキャラクターであるという事を理解しているようです。また、観察からフレームをうまく再構成する方法を学びました。再構成された4つのフレームのサンプルを次に示します。

「VAE」には潜在空間があるため、次のようにレベル間で線形補間を行うことができます。
◎ MDN-RNN
「LSTM」はいくつかの基本的な動きを理解しているようです。そのため、ソニックが倒れそうになると、キャラクターがゆっくりと下降します。再構築された画像は、時間が経つにつれてぼやける傾向があります。これは、モデルが「長期」の将来について不確実であることを示す良い兆候です。ただし、主に提出期限が原因で、ネットワークの訓練が十分に行われていないと思います。イメージを作成するために、左上のフレームを取得し、それを潜在空間にエンコードし、右へ移動するための個別の行動を連結しました。例は次のとおりです。最初の4つの画像は真の画像で、次の4つの画像は再構成です。「LSTM」の予測は、最初の再構成フレームを入力として2行目から始まります。

◎ Controller
「Controller」の結果はまあまあで、訓練の少なさを考えると、有望と考えています。エージェントの結果のばらつきは依然として非常に高くなっています。しかし、観察したことから、最高のエージェントは平均スコアがそれほど増加しない間、時間の経過とともに改善し続けました。ただし、時間の経過とともに比較するために訓練スクリプトにレベルごとの平均スコアを記録させませんでした。
生成された映像の分析から、「Controller」は立ち往生しているときに障害物を正しく飛び越えてジャンプすることは一般に良いアイデアであると理解しており、あるレベルでは敵ユニットが何であるか、その他いくつかの詳細を理解しているようです。レベルがそれほど複雑でない場合、全体的なゲームプレイは有望に見えます。また、この動作が「early stopping」の影響を強く受けているのは注目に値します。これは、ソニックが実際に左に出て探索することを許可しないためです。報酬が低いため、「CMA-ES」はこの動作を推奨しません(計算を節約するため)。
この時点で最高のエージェントは、150世代で約4500スコアを獲得しました。全てのレベルの平均で2000のスコアを達成しました。動画用にこれらのレベルで特別に再訓練せずにこのエージェントを使用した映像を次に示します。最初の動画では、ソニックがレベル(約9000以上のスコア)をクリアし、2番目の動画では4500前後になります。
9. 提出結果
コンテスト終了のほんの数時間前に提出プロセスをはじめました。また、「Controller」はまだ進化を続けており、最終的な提出を行った時点で80世代程度でした。最高のエージェントも送信しませんでした。最新の「CMA-ES」の保存された状態のみを使用し、保存されたパラメータからその場で新しい「Controller」を生成しました。結果は100万ステップにわたるエージェントの平均スコアに基づいているため、「CMA-ES」によって生成されたエージェントのスコアが2000を超える場合、同じエージェントで最後まで再生されることを確認しました。これにより、約1800のスコアが達成され、レベルの1つは8100〜スコアで完了しています。評価レベルでの最高スコアの平均は2500〜4000になります。評価レベルでまったく訓練を行わずに、生成された最適なエージェント全体を送信する時間はありませんでしたが、かなり良い平均スコアと行動でした。
10. ディスカッション
エージェントのパフォーマンスを改善できるポイントがいくつかあります。はじめに「VAE」です。「Generative Adversarial Networks」(GAN)やそのバリアントなど、潜在空間にエンコードする場合により良い結果を示したモデルがあります。また、実装では、いくつかのハイパーパラメータを選択しましたが、これらは確かに最適ではありません。より多くの時間が、より鋭い結果を得て、より良い実装選択をするのを確実に助けるでしょう。「early stopping」を使用したため、ソニックは独自の動作ではなく強制的な動作を学習し、異なる結果につながりました。また、フィットネスシェーピング関数が、何らかの面で悪い行動を助長すると疑っています。これをさらに調査する必要があります。人間の制約を受けずに自然環境を利用したいと思っていました。
この記事を書いている間、60FPSの人間のレコードを使用し、その上でLSTMを訓練したという実装エラーを認識しました。評価レベルは15FPSで実行されます。それがそれほど大きな違いを生むとは思いませんでしたが、同じエージェントによる全レベルの平均スコアは、15FPSが「2004」、60FPSが「1830」となり、15FPSの方が少し大きいという結果になりました。最後に、リーダーボードのレベルを評価として使用する時間があると思っていたため、訓練中に何も保存しませんでした。これは、特にOpenAIがテストレベルをリリースしない場合は、間違いであることがわかりました。
コンテストのリーダーボードに悪い結果が示されているにもかかわらず、このような観察を利用しない方法は、強化学習と機械学習の将来にとって本当に有望であると信じています。
この記事が気に入ったらサポートをしてみませんか?