
Agent57 - 全57本のAtariゲームで人間に勝利したAIエージェント

以下の記事を参考に書いてます。
・DeepMind’s Agent57 beats humans at 57 classic Atari games
1. はじめに
「DeepMind」は今週発表した論文の中で、「ALE」(Arcade Learning Environment)に含まれる57本のAtariゲームすべてで人間を上回る性能を発揮した初めてのシステム「Agent57」を発表しました。
この主張が正しいと仮定すると、「Agent57」は以前にリリースされたものよりも優れたAI意思決定モデルの基礎を築くことができます。これは、職場の自動化を通じて生産性を向上させたいと考えている企業に恩恵をもたらす可能性があります。
『Agent57を使用することで、Atari57のすべてのタスクで人間を超えるパフォーマンスを実現し、より汎化性能の高いエージェントの構築に成功しました』
『Agent57は、計算量の増加に応じてスケーリングできました。訓練が長いほど、スコアが高くなります。』
と研究の共著者は述べています。
2. ALE(Arcade Learning Environment)
「ALE」は、様々な「Atariゲーム」を使うことで、エージェントの汎化性能を評価するプラットフォームとして提案されました。
なぜ「Atariゲーム」なのか?
主な理由は、(1) 汎化を主張するのに十分多様であり、(2) 実際に直面する可能性のある問題を代表するのに十分に興味深いものであり、(3) 独立した当事者によって作成されたため、実験者のバイアスがありません。
エージェントは、ゲームの固有情報を使用せずに、最小限の前提で、できるだけ多くのゲームでうまく機能することが期待されます。
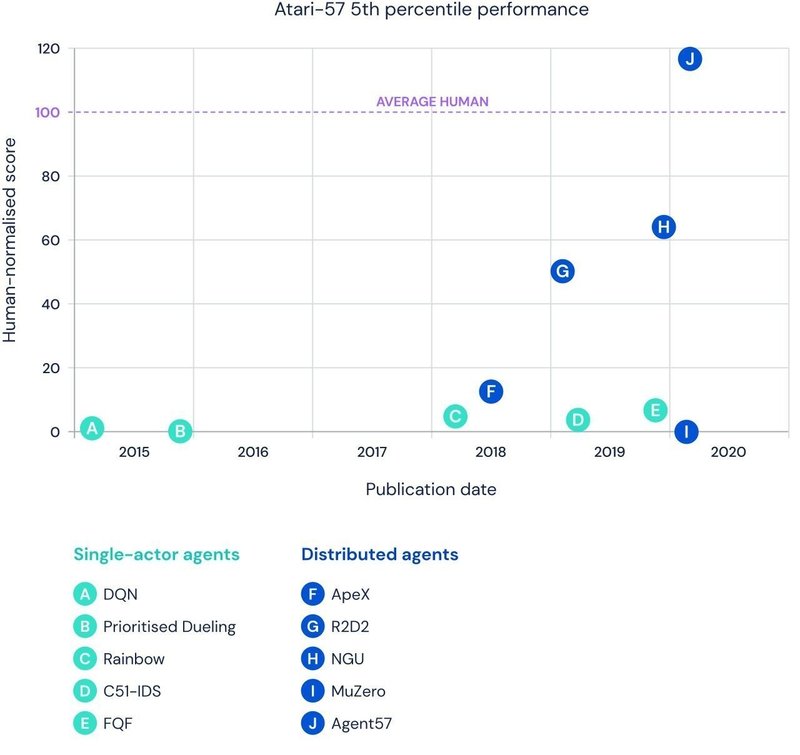
「DeepMind」の「Deep Q-Networks」は、多くの「Atariゲーム」で人間レベルの性能を実現する最初のアルゴリズムでした。その後、「OpenAI」と「DeepMind」は、「Pong」と「Enduro」で超人的なパフォーマンスを示しました。「Uber」のモデルは「Montezuma’s Revenge」のすべてのステージをクリアすることを学びました。そして、「DeepMind」の「MuZero」は、51のゲームで人間を上回る性能を実現しました。しかしこれまで、ALEの57本のゲームすべてで人間を上回るスコアを達成できるアルゴリズムは1つもありませんでした。
3. 強化学習の課題
「DeepMind」の「Agent57」は最先端のパフォーマンスを実現するために、多くのコンピュータ上での同時実行と強化学習を活用しています。強化学習はビデオゲームドメインで大きな可能性を示しています。「OpenAI」の「OpenAI Five」と「DeepMind」の「AlphaStar」は、公開サーバーで「Dota 2」プレーヤーの99.4%と「StarCraft 2」プレーヤーの99.8%をそれぞれ倒しました。しかし、これは決して完璧ではないと、研究者は指摘します。
長期的な信用の割り当ての問題、つまり、その後のポジティブな(またはネガティブな)結果に対して最も信用に値する決定を決める問題があります。これは報酬が遅れている場合や、長い連続行動に信用を割り当てる必要がある場合に、特に難しくなります。
最初のポジティブな報酬が見られるまでには、ゲーム内で何百回もの行動が必要になるかもしれません。エージェントはランダムなデータからパターンを探して動けなくなったり、新しい情報を学んだ時に以前に学んだ情報を突然忘れてしまうこともあります。
これは、新規性に敏感な内部報酬で報酬シグナルを増強します。長期的な新規性の報酬は、訓練中に多くのエピソードにまたがって多くの状態を訪問することを促します。短期的な新規性の報酬は、ゲームの1エピソード内のような短いスパンで多くの状態を訪問することを促します。「NGU」は、エピソード記憶を使って、探索と活用のためのポリシーを学習し、活用の下で最高のスコアを得ることを最終目標とします。
「NGU」の欠点の1つは、学習進捗への貢献度に関係なく、それぞれのポリシーに従った同じ量の経験値を収集することですが、DeepMindの実装では、エージェントの生涯にわたって探索戦略を適応させています。これにより、学習している特定のゲームに特化することができます。
4. Agent57
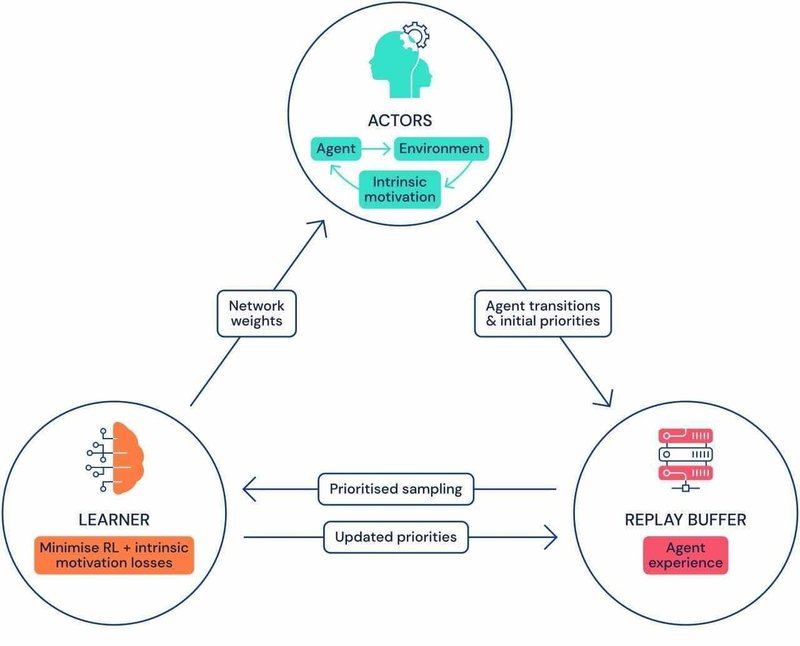
「Agent57」は、「Learner」がサンプリングできる集中型リポジトリ「Replay Buffer」に多くの「Actor」をフィードさせることでデータを収集するように設計されています。「Replay Buffer」には、定期的にプルーニングされる遷移のシーケンスが含まれています。これらの遷移は、ゲーム環境の独立した優先度の高いコピーと相互作用する「Actor」プロセスから発生します。
「DeepMind」は、2つの異なるAIモデルを使用して各状態行動値を概算しました。これは、エージェントが特定のポリシーを使用して状態で特定の行動を実行することがどの程度優れているかを示し、Agent 57のエージェントが対応する報酬で関連するスケールと分散に適応できるようにします。また、訓練時と評価時の両方で使用するポリシーを適応的に選択できる、各アクターで独立して実行される「メタコントローラ」も組み込んでいます。
研究者が説明するように、「メタコントローラ」は2つの利点をもたらします。訓練中に優先順位を付けるポリシーを選択することにより、「Agent57」はネットワークの容量をより多く割り当てて、現在のタスクに最も関連するポリシーの状態行動価値関数をより適切に表すことができます。さらに、評価時に使用する家族内で最適なポリシーを選択する自然な方法を提供します。
5. 実験
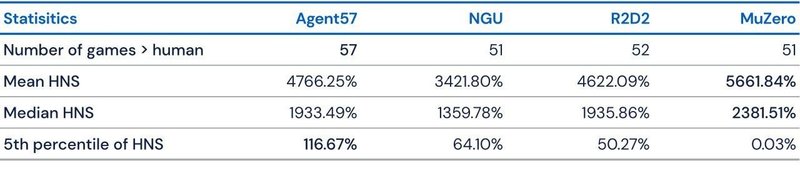
「DeepMind」は、「Agent57」を評価するために、「MuZero」「R2D2」「NGU」と比較しました。「MuZero」が57ゲーム全体で最高平均(5661.84)と中央値(2381.51)のスコアを達成した一方で、「Venture」のようなゲームで破滅的に失敗し、ランダムなポリシーと同等のスコアが報告されています。実際、「Agent57」は、「R2D2」(96.93)と「MuZero」(89.92)の両方に対して上限のある平均パフォーマンス(100)を示し、51ゲームで50億フレームを超え、「Skiing」で780億フレームを超えました。
研究者たちは次に、「メタコントローラ」を使用する効果を分析しました。それ自体では、「Solaris」や「Skiing」などの長期的な信用割り当てゲームでさえ、「R2D2」に比べてパフォーマンスが20%近く向上し、エージェントが学習に必要なフィードバックを得るために長期間にわたって情報を収集しなければならなかったと、彼らは言います。
『Agent57は、ベンチマークセットの最も難しいゲームだけでなく、最も簡単なゲームでも、ついに人間レベル以上のパフォーマンスを獲得しました』
と共著者はブログの投稿で書いています。
『これは、データの効率性だけでなく、汎化なパフォーマンスの観点からも、Atariの研究の終わりを意味するものではありません。使用する主な改善点は、Agent57が探索、計画、およびクレジットの割り当てに使用する表現の強化かもしれません。 』
この記事が気に入ったらサポートをしてみませんか?