
S-RL Toolbox入門

1. S-RL Toolbox
「S-RL Toolbox」は、ロボット用の強化学習(RL)および状態表現学習(SRL)ツールボックスです。「強化学習」を使用して「状態表現学習」の評価を行います。
ロボット工学で強化学習を行う際、低次元な状態(ロボットとターゲットの位置など)の方が学習効率が良いです。しかし、通常は生のセンサーデータ(ロボットカメラからの画像など)しか利用できないことが多いです。そこで、強化学習の方策の学習とは別に、生の観測データからの低次元な状態表現の抽出を学習する「状態表現学習」(SRL)を行います。
強化学習アルゴリズム(PPO、A2C、ARS、ACKTR、DDPG、DQN、ACER、CMA-ES、SAC、TRPO)と状態表現学習(SRL Repo参照)を効率的な方法(8コアCPUと1 Titan X GPUで1時間で100万ステップ)で統合しています。
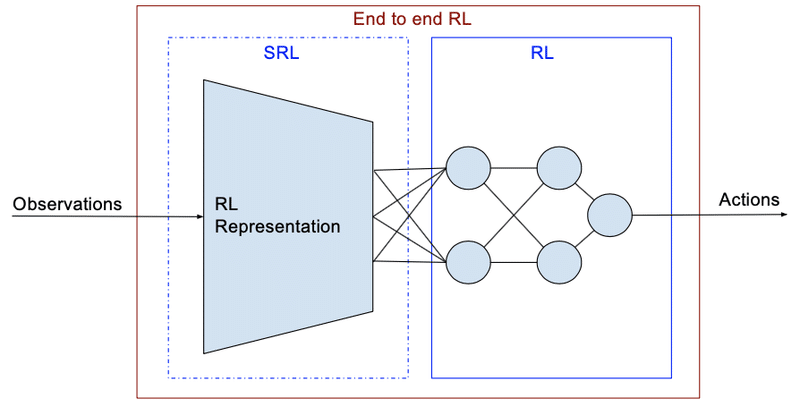
また、シミュレーション環境(Kukaアーム、PyBulletのMobileRobot、8コアマシンで250 FPSで実行)および実際のロボット(Baxter Robot、Robobo with ROS)を操作するためのカスタマイズ可能なGym環境も提供しています。
◎関連論文
・"Decoupling feature extraction from policy learning: assessing benefits of state representation learning in goal based robotics" (Raffin et al. 2018)
・"S-RL Toolbox: Environments, Datasets and Evaluation Metrics for State Representation Learning" (Raffin et al., 2018)
2. 主な特徴
「S-RL Toolbox」の主な特徴は次のとおりです。
・10個のRLアルゴリズム(Stable Baselinesを含む)
・ロギング/プロット/視覚統合/訓練されたエージェントの再生
・ハイパーパラメーター検索(hyperband、hyperopt)
・状態表現学習(SRL)メソッドとの統合(特徴抽出用)
・可視化ツール(潜在空間の探索、action probaの表示、状態空間のライブプロット等)
・SRLメソッドを比較するロボット環境
・AnacondaまたはDockerイメージ(CPU / GPU)を使用した簡単なインストール
3. 強化学習
「S-RL Toolbox」には、「Stable Baselines」の強化学習アルゴリズムが、「進化戦略」や「SAC」とともに統合されています。
・A2C : A3C(Asynchronous Advantage Actor Critic)の同期的で決定的なバリアント。
・ACER : Experience Replayを利用したActor-Criticの効果的なサンプル
・ACKTR : Actor Critic using Kronecker-Factored Trust Region
・ARS : 拡張ランダムサーチ (https://arxiv.org/abs/1803.07055)
・CMA-ES : Covariance Matrix Adaptation Evolution Strategy
・DDPG : Deep Deterministic Policy Gradients
・DeepQ : DQNおよびバリアント (Double, Dueling, prioritized experience replay)
・PPO1 : Proximal Policy Optimization (MPI実装)
・PPO2 : Proximal Policy Optimization (GPU実装)
・SAC : Soft Actor Critic
・TRPO : Trust Region Policy Optimization (MPI実装)
4. 状態表現学習
「S-RL Toolbox」で利用可能な状態表現学習は、次のとおりです。
・ground_truth : 手動で設計された特徴
(例:ロボット位置+移動ロボットenvの目標位置)
・raw_pixels : ピクセルから行動まで直接エンドツーエンドでポリシーを学習。
・autoencoder : 生のピクセルからの自動エンコーダ
・inverse : 逆動力学モデル
・forward : 順動力学モデル
・vae : 生のピクセルからの変分オートエンコーダ
・random : ランダムな特徴
・srl_combination : SRLの複数の損失(vae + forward + inverseなど)を組み合わせたモデル
・supervised : Ground Truthでトレーニングされたモデルは、監視ありの設定でターゲットとして指定します。
・robotic_priors : ロボット事前確率モデル
・pca : 生ピクセルに適用されるpca
・multi_view_srl : 複数のカメラからのビューを入力として使用し、上記の損失(トリプレットなど)を使用したSRLモデル
・joints : 腕の関節角度(Kuka環境のみ)
・joints_position : 腕のx、y、z位置と関節角度(Kuka環境のみ)
状態表現学習については、SRL Repoを参照してください。
config/srl_models.yamlを編集し、学習した状態の表現を使用する正しいパスを設定する必要があります。
5. 環境
「S-RL Toolbox」で提供する環境は、OpenAI Gymインターフェースに準拠しています。このインターフェイスを拡張して(メソッドを追加して)SRLメソッドを操作します。
利用可能な環境は、次のとおりです。
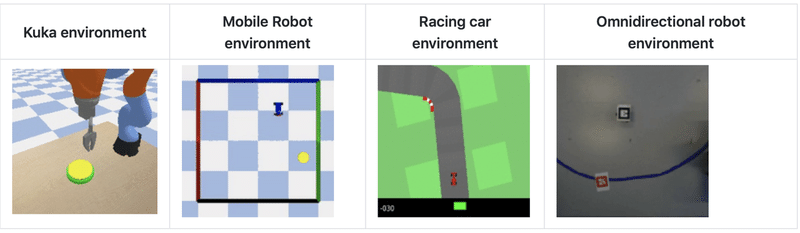
◎ Kukaアーム : ターゲットに到達することが目標
KukaButtonGymEnv-v0 : 前にボタンが1つある。
KukaRandButtonGymEnv-v0 : 前にボタンが1つある。オブジェクトがランダムに配置。
Kuka2ButtonGymEnv-v0 : 隣り合う2つのボタンがある。正しい順序で押す必要がある(明るいボタン→暗いボタン)。
KukaMovingButtonGymEnv-v0 : 前面にボタンが1つある。ゆっくりと左から右に移動。
◎ Mobile robot : 目標位置に到達することが目標
・MobileRobotGymEnv-v0 : 2次元地形上の移動ロボット。
・MobileRobot2TargetGymEnv-v0 : 2次元地形上の移動ロボット。2つの目標位置に正しい順序で到達する必要がある(明るい目標→暗い目標)。
・MobileRobot1DGymEnv-v0 : 1dスライダー上の移動ロボット。
・MobileRobotLineTargetGymEnv-v0 : 2次元地形上の移動ロボット。地形を横断する色付きのバンドに到達する必要がある。
◎ Racing car : 最短時間でゴールすることが目標
・CarRacingGymEnv-v0 : GymのRacingCar環境用のインターフェース。
◎ Baxter : アームでターゲットに到達することが目標
・Baxter-v0 : ROSでバクスターロボットを使用するためのブリッジ(シミュレーションではGazeboを使用)
◎ Robobo : 目標位置に到達することが目標
・RoboboGymEnv-v0 : ROSでRoboboを使用するためのブリッジ。
◎ OmniRobot : 目標位置に到達することが目標
・OmnirobotEnv-v0 : シミュレータだけでなく、ROSでOmniRobotを使用するためのブリッジ。
6. インストール
「S-RL Toolbox」をインストールするには、Ubuntuが必要です。
インストール手順は次のとおりです。
(1)Anacondaのインストール
・Anaconda | The World's Most Popular Data Science Platform
(2) レポジトリのダウンロード
gitサブモジュールを使用しているため、--recursive引数を使っている点に注意してください。
$ git clone git@github.com:araffin/robotics-rl-srl.git --recursive(3) Swigライブラリのインストール。
$ sudo apt-get install swig(4)environment.ymlファイルで依存関係をインストール後、仮想環境py35を有効化。
$ cd robotics-rl-srl
$ conda env create --file environment.yml
$ source activate py357. サンプルの実行
4つの並列プロセスを使用して、10000ステップの「MobileRobotGymEnv-v0」環境でPPO2エージェントを訓練するコマンドは次のとおりです。
$ python -m rl_baselines.train --algo ppo2 --no-vis --num-cpu 4 --num-timesteps 10000 --env MobileRobotGymEnv-v0状態表現学習も含めたコマンドの書式は次の通りです。
$ python -m rl_baselines.train --algo <強化学習アルゴリズム> --env <環境> --log-dir <ログの出力先> --srl-model raw_pixels --num-timesteps <ステップ数> --no-visピクセルを入力として利用するには「--srl-model raw_pixels」、ロボットの位置を入力として利用するには「--srl-model ground_truth」を指定します。
この記事が気に入ったらサポートをしてみませんか?