
Stable BaselinesでHERを使う

1. HER(Hndsight Experience Replay)
強化学習アルゴリズム「HER」については、以下を参照。
2. 環境
今回は、環境として「highway-env」の「parking-v0」を使います。
・GitHub - eleurent/highway-env: An environment for autonomous driving decision-making
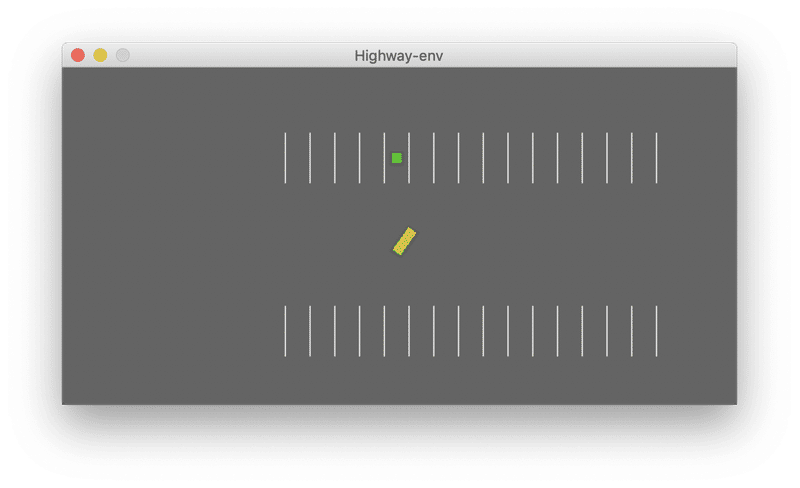
ego-vehicleが適切な方向で所定のスペースに駐車しなければならない、目標条件付き連続制御タスクになります。
3. Stable BaselinesでHERを使う
Stable BaselinesでHERを使うコードは、次のとおり。
import gym
import highway_env
import numpy as np
from stable_baselines import HER, SAC
from stable_baselines.ddpg import NormalActionNoise
# 環境の生成
env = gym.make("parking-v0")
# HER+SACモデルの生成
model = HER('MlpPolicy', env, SAC,
n_sampled_goal=4,
goal_selection_strategy='future',
verbose=1,
buffer_size=int(1e6),
learning_rate=1e-3,
gamma=0.95,
batch_size=256,
policy_kwargs=dict(layers=[256, 256, 256]))
# モデルの学習
model.learn(int(2e5))
# モデルの保存
model.save('her_sac_highway')
# モデルの読み込み
model = HER.load('her_sac_highway', env=env)
# モデルの評価
episode_reward = 0
obs = env.reset()
for _ in range(100):
# 行動の取得
action, _ = model.predict(obs)
# 1ステップの実行
obs, reward, done, info = env.step(action)
# 環境の描画
env.render()
# 報酬の計算
episode_reward += reward
# エピソード完了
if done or info.get('is_success', False):
print('Reward:', episode_reward, 'Success?', info.get('is_success', False))
episode_reward = 0.0
obs = env.reset()◎HER+SACモデルの生成
「HER」は、オフポリシーメソッド(DQN、SAC、TD3、DDPG)で機能するメソッドラッパーです。ハイパーパラメータは、次のとおりです。
HER(policy, env, model_class, n_sampled_goal=4, goal_selection_strategy='future', *args, **kwargs)
【説明】HERモデルの生成
【引数】policy : BasePolicy or str 方策
env : Gym Env or str 環境
model_class : OffPolicyRLModel Hindsight Experience Replayを適用するオフポリシーRLモデル
n_sampled_goal : int 実際の遷移ごとに何個の人工遷移を作成するか
goal_selection_strategy : GoalSelectionStrategyまたはstr 人口遷移の作成時に新しい目標を選択するための戦略
・future : 同じエピソードで、現在のステップの後に達成された目標を選択
・final : エピソードの最後に達成された目標を選択
・episode : エピソードで達成された目標を選択
・random : ある時点で達成された(およびリプレイバッファーに存在する)目標を選択この記事が気に入ったらサポートをしてみませんか?