
Unity ML-Agents Release 19 のチュートリアル

「Unity ML-Agents Release 19」で、強化学習の学習環境を作成する手順をまとめました。
・Unity ML-Agents Release 19
・Unity 2020.3以降
・Python 3.6.1以降
前回
1. 学習環境の概要
ボール(RollerAgent)が立方体(Target)に向かって転がるように訓練する学習環境になります。

今回の学習環境の要素は次のとおりです。
・観察
・Vector Observation (サイズ6)
0 : TargetのX座標
1 : TargetのZ座標
2 : RollerAgentのX座標
3 : RollerAgentのZ座標
4 : RollerAgentのX速度
5 : RollerAgentのZ速度
・行動
・Continuous (サイズ2)
0 : RollerAgentのX軸方向に加える力
1 : RollerAgentのZ軸方向に加える力
・報酬 +エピソード完了:
・RollerAgentがTargetに到着 : 報酬「1.0」+エピソード完了
・RollerAgentが落下 : エピソード完了
2. Unity側の準備
Unity側の準備の手順は、次のとおりです。
(1) 以下のサイトから「Unity Hub」をダウンロードしてインストールし、「Unity Hub」で「Unity 2020.3」以降をインストール。
(2) 以下のサイトの「Release 19」の「Souce Code(zip)」から、zipファイルをダウンロードして解凍。
「ml-agents-release_19」というフォルダができます。
フォルダ構成は、次のとおりです。
・com.unity.ml-agents : Unity ML-AgentsのUnityパッケージ
・ml-agents : Unity ML-AgentsのPythonパッケージ
・ml-agents-envs : Unity-Python間インタフェースのPythonパッケージ
・config : 学習設定ファイル
3. Python側の準備
Unity側の準備の手順は、次のとおりです。
(1) Pythonの仮想環境を準備。
「Python 3.6以降」をインストールします。
(2) Pythonの仮想環境で、「ml-agents-release_19」フォルダに移動し、以下のコマンドを実行。
Windowsでは、PyTorchのインストールコマンドも必要になります。
・Windows
$ pip install torch~=1.7.1 -f https://download.pytorch.org/whl/torch_stable.html
$ pip install -e ./ml-agents-envs
$ pip install -e ./ml-agents・macOS
$ pip install -e ./ml-agents-envs
$ pip install -e ./ml-agents4. Unity ML-Agentsのプロジェクトの作成
「Unity ML-Agents」のプロジェクトの作成手順は、次のとおりです。
(1) Unityを起動し、Unityのプロジェクトを「3D」で新規作成。
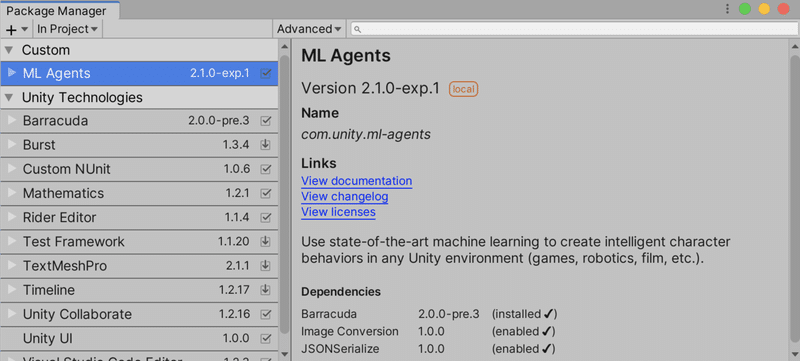
(2) メニュー「Window → Package Manager」を開き、「+ → Add package from disk」を選択し、「ml-agents-release_19/com.unity.ml-agents/package.json」を選択。
5. 学習環境の作成
◎ カメラの位置と向きの調整
(1) Hierarchyウィンドウで「Main Camera」を選択。
(2) Inspectorウィンドウで以下を設定。
Position = (0, 4, -10)
Rotation = (20, 0, 0)
Scale = (1, 1, 1)◎ マテリアルの作成
(1) Projectウィンドウで「Create → Material」で「Material」を作成し、名前に「Gray」を指定。
(2) 「Gray」を選択し、Inspectorウィンドウの「Main Maps → Albedo」(テクスチャ色)で灰色(168,168,168)を指定。
(3) 同様に茶色(212,154,33)のマテリアル「Brown」と、青色(0,35,255)のマテリアル「Blue」を作成。
◎ Floorの追加
(1) Hierarchyウィンドウの「Create → 3D Object → Plane」で「Plane」を追加し、名前に「Floor」を指定。
(2) 「Floor」を選択し、Inspectorウィンドウで以下を設定。
Position = (0, 0, 0)
Rotation = (0, 0, 0)
Scale = (1, 1, 1)(3) 「Floor」の「Mesh Renderer」の「Materials → Element 0」に灰色のマテリアル「Gray」を指定。
◎ Targetの追加
(1) Hierarchyウィンドウの「Create → 3D Object → Cube」で「Cube」を追加し、名前に「Target」を指定。
(2) 「Target」を選択し、Inspectorウィンドウで以下を設定。
Position = (3, 0.5, 3)
Rotation = (0, 0, 0)
Scale = (1, 1, 1)(3) 「Target」の「Mesh Renderer」の「Materials → Element 0」に茶色のマテリアル「Brown」を指定。
◎ RollerAgentの追加
(1) Hierarchyウィンドウの「Create → 3D Object → Sphere」で「Sphere」を追加し、名前に「RollerAgent」を指定。
(2) 「RollerAgent」を選択し、Inspectorウィンドウで以下を設定。
Position = (0, 0.5, 0)
Rotation = (0, 0, 0)
Scale = (1, 1, 1)(3) 「Mesh Renderer」の「Materials → Element 0」に青のマテリアル「Blue」を指定。
(4) 「Add Component」で「Rigidbody」を追加。
6. Unity ML-Agentsのコンポーネントの追加
学習環境に「観察」「行動」「報酬」を設定するため、「ML-Agentsのコンポーネント」を追加します。
・Behaviour Parameters
・ Agentクラスを継承したスクリプト
・Decision Requester
7. Behavior Parametersの追加
「観察」や「行動」のデータ型を指定するコンポーネントです。
(1) 「RollerAgent」に「Add Component」で「Behavior Parameters」を追加。
(2) 「RollerAgent」を選択し、Inspectorウィンドウで以下を設定。
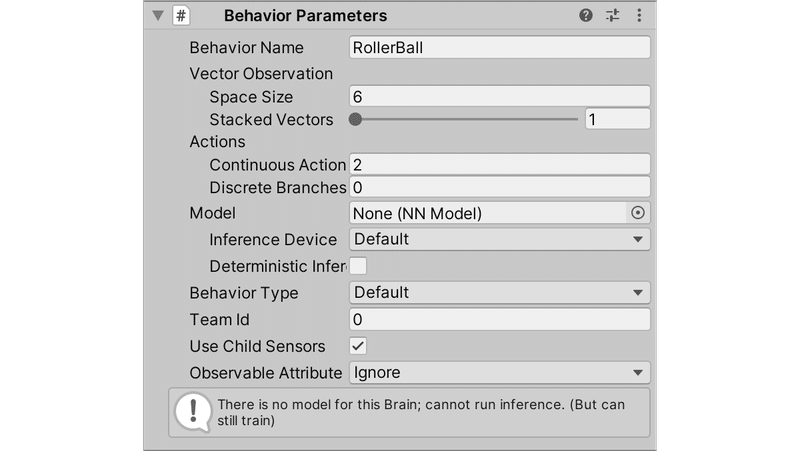
Behavior Name = RollerBall
Vector Observation → Space Size = 6
Vector Observation → Stacked Vectors = 1
Actions → Continuous Actions = 2
Actions → Discrete Branches = 08. Agentクラスを継承したスクリプトの追加
「人工知能への観察の提供」「人工知能が決定した行動の実行」「行動結果に応じた報酬」を指定するスクリプトです。
(1) コンポーネント「RollerAgent」を選択して、「Add Component」で新規スクリプト「RollerAgent」を追加。
・RollerAgent.cs
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Policies;
// RollerAgent
public class RollerAgent : Agent
{
public Transform target; // TargetのTransform
Rigidbody rBody; // RollerAgentのRigidBody
// 初期化時に呼ばれる
public override void Initialize()
{
// RollerAgentのRigidBodyの参照の取得
this.rBody = GetComponent<Rigidbody>();
}
// エピソード開始時に呼ばれる
public override void OnEpisodeBegin()
{
// RollerAgentが床から落下している時
if (this.transform.localPosition.y < 0)
{
// RollerAgentの位置と速度をリセット
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.localPosition = new Vector3(0.0f, 0.5f, 0.0f);
}
// Targetの位置のリセット
target.localPosition = new Vector3(
Random.value*8-4, 0.5f, Random.value*8-4);
}
// 状態取得時に呼ばれる
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(target.localPosition.x); //TargetのX座標
sensor.AddObservation(target.localPosition.z); //TargetのZ座標
sensor.AddObservation(this.transform.localPosition.x); //RollerAgentのX座標
sensor.AddObservation(this.transform.localPosition.z); //RollerAgentのZ座標
sensor.AddObservation(rBody.velocity.x); // RollerAgentのX速度
sensor.AddObservation(rBody.velocity.z); // RollerAgentのZ速度
}
// 行動実行時に呼ばれる
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// RollerAgentに力を加える
Vector3 controlSignal = Vector3.zero;
controlSignal.x = actionBuffers.ContinuousActions[0];
controlSignal.z = actionBuffers.ContinuousActions[1];
rBody.AddForce(controlSignal * 10);
// RollerAgentがTargetの位置にたどりついた時
float distanceToTarget = Vector3.Distance(
this.transform.localPosition, target.localPosition);
if (distanceToTarget < 1.42f)
{
AddReward(1.0f);
EndEpisode();
}
// RollerAgentが床から落下した時
if (this.transform.localPosition.y < 0)
{
EndEpisode();
}
}
// ヒューリスティックモードの行動決定時に呼ばれる
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}
}Agentクラスのオーバーライドメソッドは、次のとおりです。
・Initialize() : インスタンス生成時の初期化。
・OnEpisodeBegin() : エピソード開始時の初期化。
・CollectObservations(VectorSensor sensor) : 人工知能への状態の提供。
・OnActionReceived(ActionBuffers actionBuffers) : 人工知能が決定した行動を受け取り実行し、行動結果に応じて報酬を提供。
・Heuristic(in ActionBuffers actionsOut) : 人間による行動の決定。
(2) Hierarchyウィンドウで「RollerAgent」を選択し、Inspectorウィンドウで以下を設定。
Targetには、HierarchyウィンドウのTargetを「RollerAgent」のTargetにドラッグ&ドロップします。

Max Step = 1000
Target = Target9. Decision Requesterの追加
何フレーム毎に行動を決定(変更)するかを指定するコンポーネントです。
(1) 「RollerAgent」に「Add Component」で「Decision Requester」を追加。
(2) 「RollerAgent」を選択し、Inspectorウィンドウで以下を設定。

Decision Period = 1010. 学習環境の動作確認
UnityエディタのPlayボタンで実行すると、学習前に学習環境の動作確認ができます。方向キーでボールを動かし、立方体に衝突すると立方体が移動し、ボールが落下すると床の上に戻ります。

「Unity ML-Agents」には、「学習モード」「推論モード」「ヒューリスティックモード」の3つの実行モードがあります。「Behavior Parameters」の「Behavior Type」で設定します。
・Default : 学習用Pythonスクリプトが実行中の時は「学習モード」、
それ以外でModelが設定済みの時は「推論モード」、
それ以外は「ヒューリスティックモード」
・Heuristic Only : 常に「ヒューリスティックモード」
・Inference Only : 常に「推論モード」
11. Pythonスクリプトによる学習
Pythonスクリプトによる学習を行い、「推論モデル」を生成します。
(1) 「ml-agents-release_19/config」に「RollerBall.yaml」を作成し、以下のように編集し、文字コード「UTF-8」で保存。
学習時に必要なハイパーパラメータを設定します。Windowsでは、YAMLに日本語コメントが含まれていると読み込みに失敗するので、日本語コメントは削除してください。
・RollerBall.yaml
behaviors:
RollerBall:
# トレーナー種別
trainer_type: ppo
# 基本設定
max_steps: 500000
time_horizon: 1000
summary_freq: 1000
keep_checkpoints: 5
# 学習アルゴリズムの設定
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
# ニューラルネットワークの設定
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
# 報酬の設定
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0各パラメータについては、以下を参照。
「Release 18」用ですが基本的に同じです。
(2) Pythonの仮想環境で、ml-agentsフォルダに移動し、以下のコマンドを実行。
「--run-id」は学習IDで学習結果の出力先フォルダ名にもなります。学習毎に変更してください。
$ mlagents-learn ./config/RollerBall.yaml --run-id=RollerBall-ppo-1mlagents-learnの引数については、以下を参照。
「Release 18」用ですが基本的に同じです。
(3) Unity EditorのPlayボタンを押して学習開始。
20,000ステップほどで学習できます。
Step: 1000. Time Elapsed: 14.209 s. Mean Reward: 0.306. Std of Reward: 0.461. Training.
Step: 2000. Time Elapsed: 21.333 s. Mean Reward: 0.246. Std of Reward: 0.431. Training.
Step: 3000. Time Elapsed: 29.174 s. Mean Reward: 0.430. Std of Reward: 0.495. Training.
:
Step: 18000. Time Elapsed: 155.577 s. Mean Reward: 0.969. Std of Reward: 0.174. Training.
Step: 19000. Time Elapsed: 164.250 s. Mean Reward: 0.966. Std of Reward: 0.180. Training.
Step: 20000. Time Elapsed: 172.451 s. Mean Reward: 0.974. Std of Reward: 0.159. Training.(4) Ctrl-Cで学習完了すると、「results/RollerBall-ppo-1/RollerBall.onnx」に推論モデルが生成されています。
12. TensorBaord
以下のコマンド実行後、「http://localhost:6006/」をブラウザで開くことで、学習状況をグラフで確認できます。
$ tensorboard --logdir=results
次回
この記事が気に入ったらサポートをしてみませんか?