
TensorFlow Liteのパフォーマンスのベストプラクティス

モバイルの計算リソースは限られているため、アプリケーションのリソースを効率的に保つことが重要になります。「TensorFlow Lite」でモデルとアプリケーションを最適化する際の、ベストプラクティスをまとめています。
(情報源)
1. タスクに最適なモデルの選択
タスクに応じて、モデルの「複雑さ」(精度)と「サイズ」(速度)をトレードオフする必要があります。
タスクに高い精度が必要な場合、大きく複雑なモデルが必要になる場合があります。タスクに精度をあまり必要としない場合、ディスクスペースとメモリが少ないだけでなく、一般に高速でエネルギー効率が高いため、より小さなモデルを使用した方が良いです。
以下のグラフは、一般的な画像分類モデルの精度と速度のトレードオフを示しています。
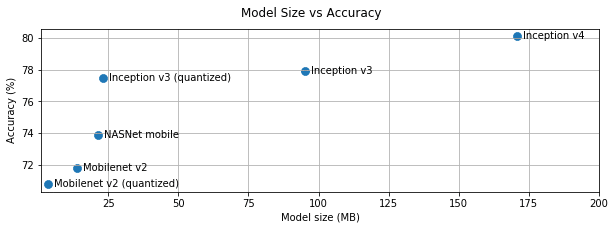
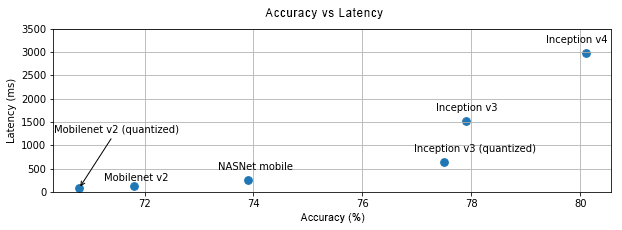
モバイル向けに最適化されたモデルの1つに「MobileNet」があります。ホストモデルには、モバイルに最適化された他のモデルがいくつかリストされています。
2. モデルのプロファイルとベンチマーク
タスクに適した候補モデルを選択したら、モデルの「プロファイル」と「ベンチマーク」を行うことをお勧めします。
「TensorFlow Lite」のベンチマークツールには、オペレータごとのプロファイリング統計を表示するプロファイラが組み込まれています。これは、計算時間がかかるオペレータを見つけるのに役立ちます。
3. グラフ内のオペレータの最適化
特定のオペレータがモデルに頻繁に出現する場合、時間を多く消費していることがわかった時、そのオペレータの最適化を検討できます。
「TensorFlow Lite」には、ほとんどのオペレータ向けに最適化されたバージョンが用意されてるため、このシナリオはまれです。ただし、オペレータが実行される制約がわかっている場合は、より高速なカスタムオペレータを作成できる場合があります。詳しくは、カスタムオペレータのドキュメントを参照してください。
4. モデルの最適化
モデル圧縮の目的は、一般に高速でエネルギー効率の高い、より小さなモデルを作成して、モバイルに展開できるようにすることです。
モデルが「浮動小数点」の重みまたは活性化関数を使用している場合、「量子化」を使用してモデルのサイズを最大で4倍に減らすことができます。これにより、floatの重みが事実上8ビットになります。「量子化」には、「訓練後の量子化」と「訓練中の量子化」の2があります。
前者はモデルの再訓練を必要としませんが、まれに精度が低下する場合があります。精度の低下が許容可能な範囲を超えている場合は、代わりに「訓練中の量子化」を使用する必要があります。
モデルの圧縮中に精度が影響を受けていないことを確認するため、ベンチマークを実行することを強くお勧めします。詳細については、 モデル最適化のドキュメントを参照してください。
5. スレッド数の調整
「TensorFlow Lite」は、多くのオペレータのマルチスレッドカーネルをサポートしています。スレッドの数を増やし、オペレータの実行を高速化できます。ただし、スレッド数を増やすと、モデルがより多くのリソースとパワーを使用するようになります。
一部のアプリケーションでは、待ち時間がエネルギー効率よりも重要になる場合があります。インタプリタスレッド数を設定することにより、スレッド数を増やすことができます。
ただし、マルチスレッド実行では、他に何が同時に実行されるかによってパフォーマンスの変動が大きくなるという犠牲が伴います。これは特にモバイルアプリの場合です。
たとえば、分離テストでは、シングルスレッドと比較して2倍の高速化が示される場合がありますが、別のアプリが同時に実行されている場合、シングルスレッドよりもパフォーマンスが低下する可能性があります。
6. 不必要なコピーの排除
アプリケーションが慎重に設計されていない場合、モデルに入力を供給し、モデルから出力を読み取る時に、「不必要なコピー」が存在する場合があります。不必要なコピーを排除するようにしてください。
Javaなどの高レベルのAPIを使用している場合は、パフォーマンスに関する注意事項についてドキュメントを注意深く確認してください。たとえば、ByteBuffersが入力として使用した場合、Java APIははるかに高速です 。
7. プラットフォーム固有のツールによるアプリケーションのプロファイル
「Androidプロファイラ」や「Instruments」などのプラットフォーム固有のツールは、アプリのデバッグに使用できる豊富なプロファイリング情報を提供します。パフォーマンスのバグは、モデルではなく、モデルと対話するアプリケーションコードの一部にある場合があります。
プラットフォーム固有のプロファイリングツールとプラットフォームのベストプラクティスに精通してください。
8. ハードウェアアクセラレータがモデルにメリットがあるかどうかを評価
「TensorFlow Lite」は、「GPU」「DSP」「ニューラルアクセラレータ」などの高速ハードウェアでモデルを高速化する新しい方法を追加しました。通常、これらのアクセラレータは、インタープリタの実行の一部を引き継ぐデリゲートサブモジュールを通じて公開されます。
「TensorFlow Lite」は次の方法でデリゲートを使用できます。
(1)AndroidのNeural Networks API
これらのハードウェアアクセラレータを利用して、モデルの速度と効率を改善できます。Neural Networks APIを有効にするには 、インタープリターインスタンスで「UseNNAPI」を呼び出します。
(2)OpenGL/Metalを利用したAndroid/iOSのGPUデリゲート
これらを試すには、GPUデリゲートのチュートリアルとドキュメントを参照してください。
(3)非標準のハードウェアにアクセスできる場合は、独自のデリゲートを作成できます。詳細についてはTensorFlow Liteのデリゲートを参照してください。
一部のアクセラレータは、さまざまなタイプのモデルに適しています。各デリゲートをベンチマークして、アプリケーションに適しているかどうかを確認することが重要です。たとえば、モデルが非常に小さい場合は、モデルをNN APIまたはGPUに委任する価値がない場合があります。逆に、演算強度が高い大規模モデルにはアクセラレータが最適です。
この記事が気に入ったらサポートをしてみませんか?