
Splunkを用いたデータサイエンス

SplunkはDWHでもあり、ETL機能もあるが、サーチエンジンです。
ビッグデータとかAIに対して懐疑的であったり、腰が重かったり
なかなかデータサイエンスが文化やナレッジとして広まらないのが日本の現状なのかなと思っています。
もちろんデータ活用を仕組み化できている会社もあるので、今後も差は広がっていくんじゃないかと予想しています。
自分もデータエエンジニアリングを仕事の中でかじった程度ですが、
Splunkを3年間くらい触ってできるようになった知識をシェアしていければと考えています。
(最新のドキュメントはSplunkdocsで確認するほうが安心です)
対象
・Splunkに興味があってこれから勉強したい人
・データサイエンスのツールをいろいろ見たい人
Splunkってなに?という方に
まず、Splunkが何かを説明しておきます。
Splunkはビッグデータの分析に適したソフトウェアで、様々なデータの連携が可能なことと機械学習のモジュールが用意されていたり、データ統合と分析のプラットフォームです。
セキュリティマネジメントや運用監視のツールとして高いシェアと評価を得ています。
ソフトウェアはFreeライセンスでも使用可能✨
無料でも一日あたり500MBのデータインデックスが可能です。
BigQueryみたいにクエリで処理するデータ量に対して従量課金などはないので、
ボーンっと大量なデータを入れない限りは全然使用できます。
では、早速使ってみましょう。
https://www.splunk.com/ja_jp/download/splunk-enterprise.html
ユーザー登録が必要ですが、インストールするだけですのでやり方はまとめたサイトとか見ればわかると思います。
データの追加
サンプルデータとシナリオはこれを使います。
『python実践データ分析100本ノック』
サンプルデータ
http://www3.shuwasystem.co.jp/support/7980html/5875.html
今年のはじめにpythonでも覚えようかなと本を買いましたが、
いざ開いてみると全然モチベーションがわかないんですよね。
第1章
<ノック1>データを読み込んでみよう
<ノック2>データを結合(ユニオン)してみよう
<ノック3>データを結合(ジョイン)してみよう
<ノック4>マスターデータを結合(ジョイン)してみよう
<ノック5>必要なデータ列を作ろう
<ノック6>データを検算しよう
<ノック7>各種統計量を把握しよう
<ノック8>月別でデータを集計してみよう
<ノック9>月別、商品別でデータを集計してみよう
<ノック10>商品別の売上推移を可視化してみよう
縦方向(同じスキーマ)の結合をユニオン
横方向(違うスキーマ)の結合はジョインらしいです。
この章でSplunk側でやったことは、
①Appとインデックスの作成
②データのインデックス
③ルックアップファイル(マスターデータ)の追加
所要時間:20分
最終的には商品別と月別で売上と売上個数を出すだけなので、シンプルです。
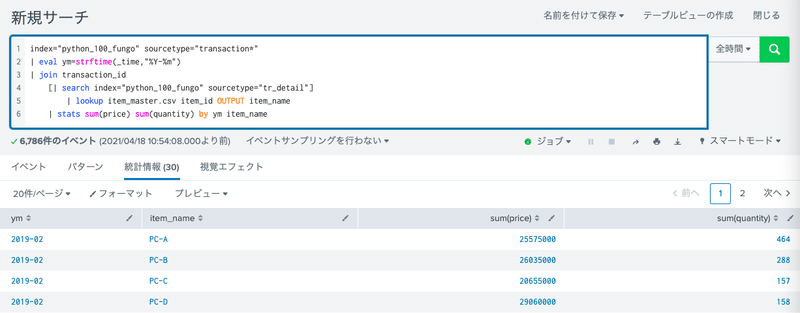
SplunkはSQLではなく、SPLという言語を覚える必要があります。
私はSQLを知らずにSPLを学んだのですが、
SPLのほうが見やすいし、細かいことを気にしないで書いてもエラーなく結果が返ってきます。(今はSQLもそれなりに書けます。)
index="python_100_fungo" sourcetype="transaction*"
| eval ym=strftime(_time,"%Y-%m")
| join transaction_id
[| search index="python_100_fungo" sourcetype="tr_detail"]
| lookup item_master.csv item_id OUTPUT item_name
| stats sum(price) sum(quantity) by ym item_nameindexはデータテーブル
sourcetypeはスキーマ定義 みたいにイメージしてください。
①Appとインデックスの作成
データの格納先のインデックスはプロジェクトごとに分けて管理することをおすすめします。
Splunkの設定ファイルはAppのディレクトリ配下に置かれています。
$SPLUNK_HOME/etc/system/local $SPLUNK_HOME/etc/apps/$app_name/local
AppというのはSplunk上で動くアドオン機能を管理する箱なのですが、
もちろんAppとインデクスはデフォルトのものでも問題なくサーチはできます。
②データのインデックス
今回は手元にCSVファイルがありますので、
UI上でデータのアップロードしております。
(アップロードと書いていますが、実際にデータが格納されるのもSplunkをインストールしているフォルダ配下になります)
アップロードしたデータはSPLでサーチをすることで、
ローデータ(タイムスタンプとイベント)で表示、
表形式や様々なグラフにビジュアライゼーション、可視化することができます。
今後シナリオに応じてどういったSPLを組めばいいかを書いていきます。
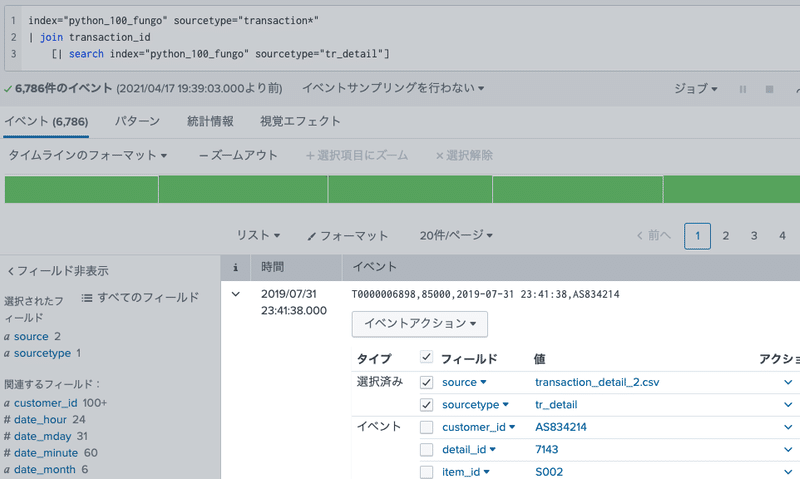
③ルックアップファイル(マスターデータ)の追加
トランザクションデータとマスターデータを管理するにあたって、洗え替え(Replace)するデータはルックアップファイルとして登録することをおすすめします。
ただルックアップファイルを参照するデータ量には上限があるので、先のインデックス同様にタイムスタンプを取り込み時間にして古いデータから消していくような運用もありだと思います。
小技を紹介
書いたクエリのインデントを揃えるショートカット
・Windows
Ctrl + ¥
・macOS
Command + \ or
Command + Shift + F
まとめると、Splunkを使うことで、
様々なデータを統合して管理が可能するDWHの機能と
SPLという言語を使うことでLookerやTableauでやってるような高度な分析が可能です。
また今回あまり深くは触れておりませんが、
Appの中には
データベースとの接続設定をするためのもの
Slackなど外部のデータを取得するAPIを設定が可能なもの
いろいろありますし、私が使っていた数年の間でもかなり進化していました。
ビジネスでの利用の場合は、ユースケースに応じて環境構築やなにをSplunkでやりたいのかをコンサルティングしてくれたり、運用保守をしてくれる日本法人の会社もあります。
今日は以上です。
この記事が気に入ったらサポートをしてみませんか?