
Googleで画像検索したファイルを保存~Python+Seleniumでブラウザ操作も自動化(Webスクレイピング)~

久しぶりにPython・Webスクレイピングの記事を。
Webサイトの中にはJavaScript等により、動的に表示が内容が変わるものがあります。
例えば、Googleで画像検索をすると、以下のように画像が表示されます。

右横のスクロールバーを下げていくと、また新たに画像が表示されます。
このように動的にサイトのHTML情報が更新される場合、BeautifulSoupだけでスクレイピングはできません。そんな時に使えるのが、今回紹介するSeleniumです。
1.Seleniumとは
簡単に言うと、Webブラウザを制御するためのツールです。
Seleniumの機能を用いることで、Webブラウザのフォーム画面に値を渡して、ログインボタンを押下することも可能です。
また、今回のようにスクロールバーを操作することもできます。そうすることで、Webサイト側のJavaScriptが起動し、非表示となっていた箇所を表示させることもできます。
つまり、ログインを前提としているサイトも自動処理可能となります。
個人的には、単純なWebスクレイピングよりも、より業務効率化等に使えるという印象です。
※Seleniumをもっと詳しく知りたい方はこちら
2.Seleniumの使い方➀(インストール)
まずはインストールです。Pythonの場合は、例によってpip installでOKです。
pip install selenium以上で、インストール完了です。
3.Seleniumの使い方➁(Webドライバーのインストール)
SeleniumはWebドライバーを使って、各ブラウザを制御します。
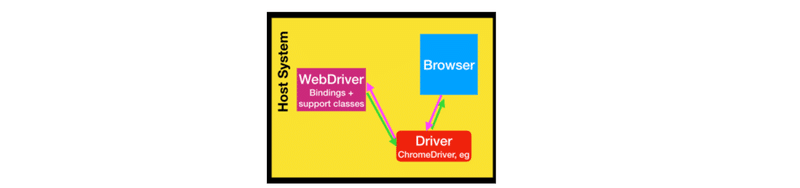
※前述のSelenium説明サイトより
ChromeやSafari、FirefoxなどのWebブラウザには、それぞれ特定のWebドライバーがあります。
ChromeのWebドライバー(Chrome Driver)をダウンロードしてみましょう。
ChromeのバージョンとChrome Driverのバージョンは同期をとる必要があるため、まずはお使いのChromeのバージョンを確認します。
Chromeの画面の右上からメニューを開き、ヘルプ>Chromeについて
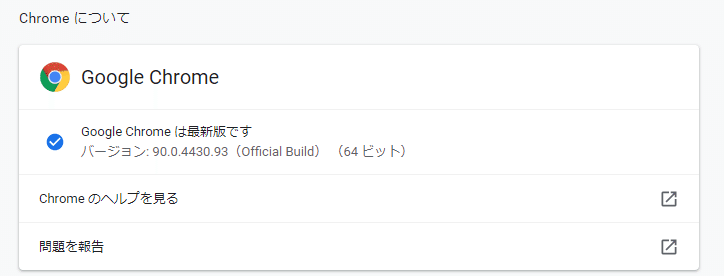
ここでバージョンが確認できます。
お次は、以下のサイトよりChromeDriverをダウンロードします。
ここで、以下案内のとおり自分のバージョンに合致するものを選びます。
私の場合は、90.0.4430.24ですね。
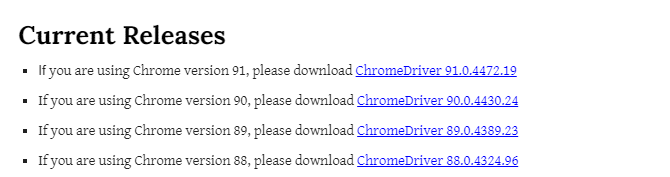
開いたら、これまた案内のとおりですが、linux、mac、windowsでそれぞれ自分の端末に合うものを選びます。
ダウンロードしたら、インストールを実施します。(僕はWindowsですが、Cドライブの直下においています。)

なお、使用する時にこのファイルパスを記載する必要があるので、どこに置いたかを把握しておいてください。
以上で準備は完了です。
4.プログラム記載にあたってのポイント2点
Googleで画像検索して画像保存する時のポイントは、以下2点です。
➊ 画像は非表示のものあり、スクロールされると追加で表示される。
➋ 画像ページのsrc属性データは画像に直接アクセス不可。
一度クリックすると、本来のsrc属性が表示される。
1点目は、冒頭でも記載した部分なので、スクロールバーを操作して画像をすべて表示させる必要があります。
2点目は、一旦画像をクリックして、右側に表示される詳細ページ側から、画像のソース情報を取得する必要があります。
■ 画像のsrc属性(詳細)
Step1
画像検索して、画像を右クリックして検証ボタンを押下してみてください。imgタグのsrc属性はdata:からはじまる部分です。かなり冗長なテキスト情報で、これ単体では画像データにアクセスできません。
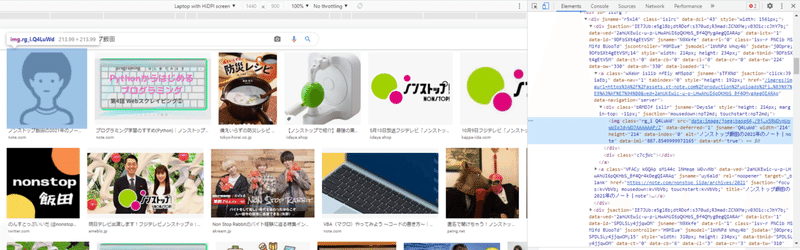
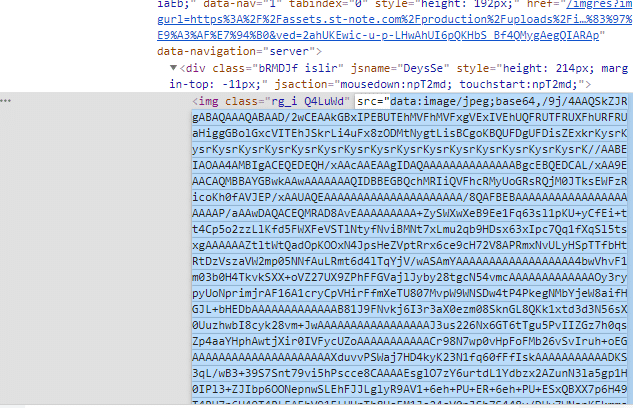
オ、オオウ・・・
Step2
画像を一旦クリックすると、右側に別途表示がされます。
ここの画像のsrc属性だと、画像データにアクセスが可能です。
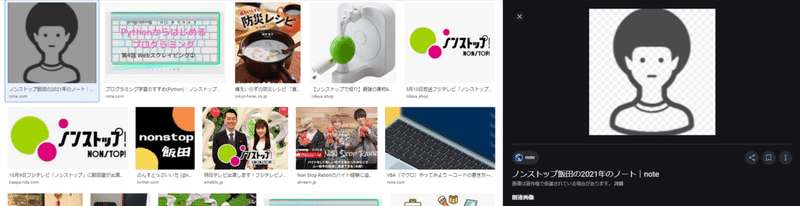
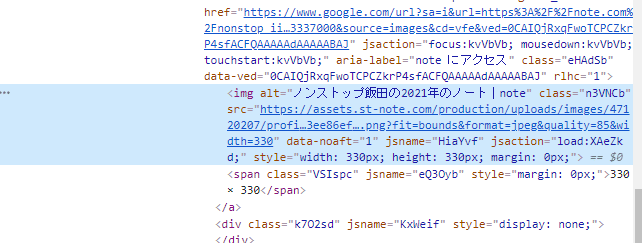
これならいける。
5. コード全文(Google Chromeで画像検索して画像データ保存)
上記ポイントを踏まえて記載すると、以下のようになります。
【2021.10.2 追記】
サイトのHTMLコードが変更されたことにより、コードを修正してます。
ご留意ください!!(hide-focus-ringでなく、hbtb-mitemでクラス名を検索する必要あり。
【2021.10.3 追記】
さらに、クリック後のimgタグのsrc属性取得ですが、Sva75cというidで取得ができないようなので、こちらも取得方法を変えました(クラス名:n3VNCb)で取得。
【2021.10.28 追記】
10.3に追記した方法だと、画像urlが上手く取得出来ないケースがあるようです。(クラスネームが複数あり、サムネイル側のものを引っ張ってしまう)
以下だと成功率がグッとあがります。
url = driver.find_element_by_xpath("/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img").get_attribute('src')
それでも取得出来ないものを除外するため、url変数に格納された文字列の頭4文字がdataの場合は、img_sorceリストにデータを追加しないようにしてます。
※sugiさん、質問ありがとうございます!
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import requests
from time import sleep
import os
#ヘッドレスモードで動かす場合のオプション設定
options = Options()
options.add_argument("--headless")
#)の位置を変えて、optionsを適用すると非表示のまま処理される
driver = webdriver.Chrome("C:\chromedriver_win32\chromedriver.exe")#,options=options)
driver.set_window_size(1500,1500)
#Google HPにアクセスする
driver.get("https://www.google.com")
#検索バーのエレメント情報を取得し、inputで入力させた値を検索バーに渡し検索を実行
search_bar = driver.find_element_by_name("q")
search_bar.send_keys(input("何の画像を検索しますか?:"))
search_bar.submit()
#保存する際のフォルダ名を入力させる
folder_name = input("フォルダ名を入れてください:")+"_image"
#使用する変数の初期設定
check = 0
num = 0
count_num = 1
print('画像検索ページを確認中...')
#画像のsrc属性を格納する空のリストを作成
img_sorce = []
#画像検索に行きつくまで、変数numに1足しながら、更新ループ処理。
#画像検索に行きついたら、クリックしてcheck変数を1に更新(ループ処理を抜ける)
while check != 1:
sleep(1)
#【注意】10/2 コード修正・・・クラス名が変わっているので修正2行下が正です
#img_search = driver.find_elements_by_class_name("hide-focus-ring") #←これだとエラーになります
img_search = driver.find_elements_by_class_name("hdtb-mitem") #こちらが正です!
if img_search[num].text == "画像":
check = 1
img_search[num].click()
sleep(2)
else:
print(img_search[num].text)
num += 1
#画面の最下部に行きつくか、10回まで画面スクロールを行う
while count_num < 11:
print("{}回目のスクロールです".format(count_num))
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
sleep(3)
count_num += 1
#画像部分のエレメントをリスト形式で取得する
source_elems = driver.find_elements_by_xpath("//img[@class='rg_i Q4LuWd']")
#ループ処理で、画像データをクリックし右側の画像表示からsrc属性情報を取得
#img_sorceリストにデータを追加していく
#データが取得できない場合は、スキップ(continue)する
for elem in source_elems:
try:
elem.click()
sleep(5)
#2021/10/3追記 以下だと抽出できないため修正
#url = driver.find_element_by_xpath("//*[@id='Sva75c']/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div/div[2]/a/img").get_attribute('src')
#↓修正後のコード
#url = driver.find_element_by_class_name("n3VNCb").get_attribute('src')
#さらに修正後のコード
url = driver.find_element_by_xpath("/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img").get_attribute('src')
if url[0:3] == 'data':
img_sorce.append(url)
else:
pass
except Exception as e:
continue
#ヘッダー情報を定義する
HTTP_HEADERS = {'User-Agent':'自分の端末情報'}
#保存するフォルダが未作成の場合、新規作成する
os.makedirs(folder_name, exist_ok = True)
print(len(img_sorce))
#保存処理を開始する
print('画像取得・保存を開始します')
number = 1
#img_sorceリストに対するループ処理を実施
#src属性として、https:/からはじまる情報であれば、画像番号(number変数)をファイル名とし、拡張子pngで保存
for url in img_sorce:
if url[0:7] == 'https:/':
r = requests.get(url, headers=HTTP_HEADERS)
path = folder_name + '/' + str(number) +'.png'
with open(path,'wb') as f:
f.write(r.content)
print('{}枚 取得・保存完了'.format(number))
number += 1
else:
continue6. ポイントとなるコードの解説
■まずは、必要なモジュールのインポートです。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import requests
from time import sleep
import osSeleniumは上2行です。
1行目でseleniumから、webdriverをインポート。
2行目は、Chromeのオプションで、ヘッドレスモードを使用するためにインポートしてます。(詳細は後述)
3行目は、最後に画像のsrc属性にリクエスト送信を行うためにインポート。
4行目はWebサイト側に負荷をかけないのと、Webページの操作を行った際、画面表示が追い付かないとエラーになるため、それを待つ意味でもtimeモジュールを利用します。
5行目のosは画像データを保存するフォルダの存在有無チェック、フォルダ作成のためにインポートしてます。
■次に、chromeドライバーを利用してGoogleサイトにアクセスするまでの部分です。
#ヘッドレスモードで動かす場合のオプション設定
options = Options()
options.add_argument("--headless")
#)の位置を変えて、optionsを適用すると非表示のまま処理される
driver = webdriver.Chrome("C:\chromedriver_win32\chromedriver.exe")#,options=options)
driver.set_window_size(1500,1500)
#Google HPにアクセスする
driver.get("https://www.google.com")ヘッドレスモードを利用しない場合、プログラムを動かすと分かりますが、Chromeブラウザを実際に起動して、操作が行われます。
これを非表示のまま処理をするのが、ヘッドレスモードです。(処理が速くなります)
driver = webdriver.Chrome("C:\chromedriver_win32\chromedriver.exe")#,options=options)の部分を少し修正して、、、
driver = webdriver.Chrome("C:\chromedriver_win32\chromedriver.exe",options=options)とすると、ヘッドレスモードとなるので、試してみてください。
いずれ解説するかもしれませんが、importしたOptionsクラスのインスタンスを、変数optionsに格納。.add.argument()でヘッドレスオプションを追加しています。
driver変数に、webdriver.Chrome("あなたのChromeDriverのファイルパス")を格納。この時、第2引数に先ほどのoptionsを渡すと、ヘッドレスモードになります。(ヘッドレスモード不要の場合は、ChromeDriverのファイルパスのみでOK)
■検索欄に、検索したいワードを入力し検索をかける
#検索バーのエレメント情報を取得し、inputで入力させた値を検索バーに渡し検索を実行(解説➊)
search_bar = driver.find_element_by_name("q")
search_bar.send_keys(input("何の画像を検索しますか?:"))
search_bar.submit()Seleniumでは、様々な方法で操作したいパーツを特定することができます。例えば、今回記載しているようにname属性で特定する場合、上記のように記載することでsearch_bar変数に検索欄を格納しています。
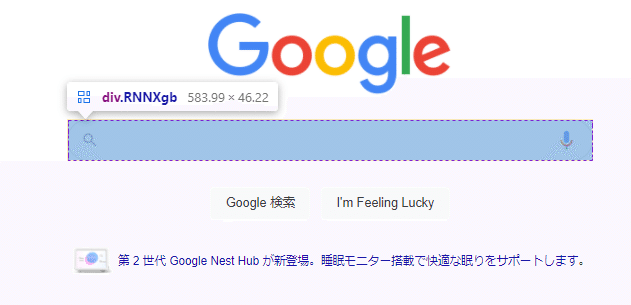

検索欄のHTML情報は上記の通りです。この中に「name="q"」という記載があるのが分かりますでしょうか。
このname属性で、element情報(パーツ)を取得しています。
そして、send.keys関数で任意の値を検索欄に渡しています。
input関数で、ユーザーに入力させるように今回は書いていますが、以下のように文字列として値を渡すことももちろん可能です。
search_bar.send_keys("ノンストップ飯田"))そして、最後にsubmit関数でボタン押下操作をさせています。
■画像検索をさせる
検索をかけた直後の状態は以下です。画像検索にはなっていません。
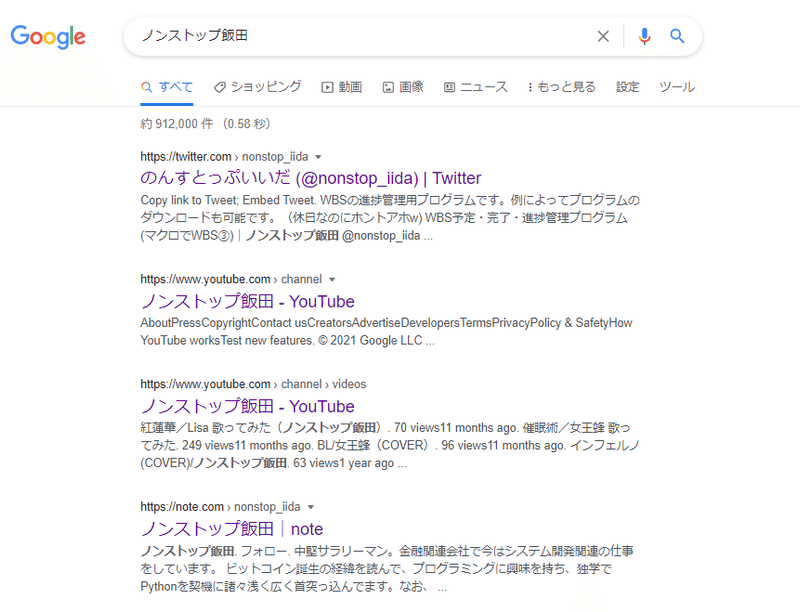
これを画像検索にさせるために、またパーツを特定し操作をさせる必要があります。そこで、選択欄を検証で確認してみると・・・

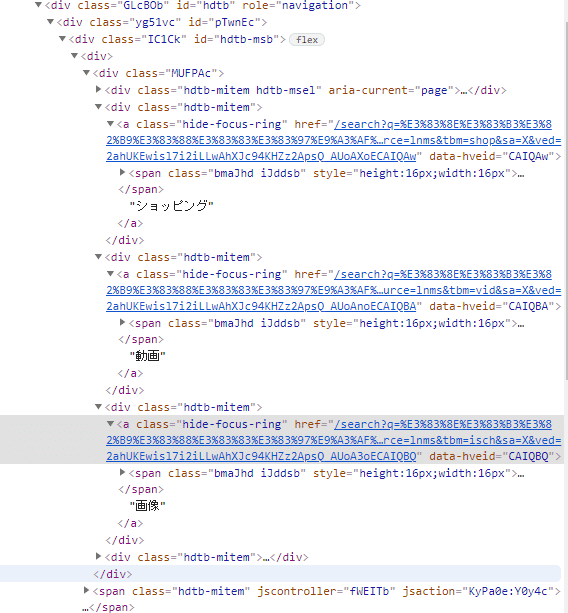
こんな感じになっています。aタグのclass属性がhide-focus-ringのものたちをたどっていけば良さそうねと分かります。
【2021.10.2 追記】
サイトのHTMLコードが変わりhide-focus-ringでなくなったため、コードの修正を行いました!(以下参照)
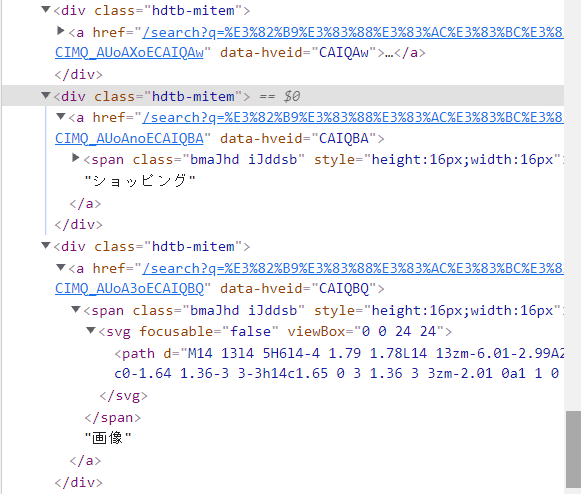
やり方は人それぞれですが、、、
#画像検索に行きつくまで、変数numに1足しながら、更新ループ処理。(解説➋)
#画像検索に行きついたら、クリックしてcheck変数を1に更新(ループ処理を抜ける)
while check != 1:
sleep(1)
img_search = driver.find_elements_by_class_name("hide-focus-ring")
if img_search[num].text == "画像":
check = 1
img_search[num].click()
sleep(2)
else:
print(img_search[num].text)
num += 1こんなやり方で、hide-focus-ringというclass属性をもつパーツを複数特定してリスト(img_search)に格納。
リストのインデックスを1ずつ増やしながら、画像にあたるまでループ処理を行ってます。画像にあたったら、該当パーツをclick関数で押下させます。
良く考えたら、普通にリストに対するループ処理で良かった気がします(笑)
なお、.textとつけると、該当パーツのテキスト情報が取得できます。
■画面を下までスクロールさせて、画像を全部表示させる
次に以下の処理で、画面を複数回スクロールさせ、全ての画像を表示させます。(今回は10回を限度でスクロール)
#画面の最下部に行きつくか、10回まで画面スクロールを行う(解説➌)
while count_num < 11:
print("{}回目のスクロールです".format(count_num))
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
sleep(3)
count_num += 1スクロール処理は以下の記載部分です。
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')window.scrollToの引数内にはそれぞれ、動かしたいx軸の座標と、y軸の座標を指定します。
x座標は0、つまり水平方向には動かしません。
y座標にあるdocument.body.scrollHeightという記載は、「画面の高さ分」という意味で、画面一個分スクロールさせてねという意味です。
スクロールさせて、sleep(3)で3秒あけてから、またスクロールというのを繰り返します。
「結果をもっと表示」というボタンが出てきたら、最下部です。もちろん、このボタンを押して、さらにスクロールさせることも可能です。
■画像パーツを特定し、リストに格納
#画像部分のエレメントをリスト形式で取得する
source_elems = driver.find_elements_by_xpath("//img[@class='rg_i Q4LuWd']")
#ループ処理で、画像データをクリックし右側の画像表示からsrc属性情報を取得(解説➍)
#img_sorceリストにデータを追加していく
#データが取得できない場合は、スキップ(continue)する
for elem in source_elems:
try:
elem.click()
sleep(5)
#url = driver.find_element_by_xpath("//*[@id='Sva75c']/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div/div[2]/a/img").get_attribute('src')
url = driver.find_element_by_class_name("n3VNCb").get_attribute('src')
img_sorce.append(url)
except Exception as e:
continue次に、画像部分のパーツをリスト形式で取得します。

rg_i Q4LuWdというclass属性を持つimgタグがターゲットです。
今度はxpath※でパーツを特定しにいきます。
※xpath…HTMLの階層情報をもとに、抽出したいタグやHTMLエレメントを特定する方法
driver.find_element_by_xpath("//img[@class='rg_i Q4LuWd']")と記載することで、複数の条件に該当するパーツをリスト形式で取得できます。
取得したリストに対し、ループ処理でまずは要素をクリック(elem.click())し、右側に表示させる画像のパーツ.get_attribute('src')でsrc属性を取得。
バンバン、用意していたimg_sorceリストに放り込んでいきます。
一応クリックしてから、sleep(5)で5秒かえて右側の画像パーツから取得するよう記載してますが、何らかの理由で上手く取得できない場合は、continueでスキップさせています。(try、exceptで例外処理を定義)
■ヘッダー情報を定義、画像データを取得し保存する
#ヘッダー情報を定義する
HTTP_HEADERS = {'User-Agent':'自分の端末情報'}
#保存するフォルダが未作成の場合、新規作成する
os.makedirs(folder_name, exist_ok = True)
#保存処理を開始する
print('画像取得・保存を開始します')
number = 1
#img_sorceリストに対するループ処理を実施(解説➎)
#src属性として、https:/からはじまる情報であれば、画像番号(number変数)をファイル名とし、拡張子pngで保存
for url in img_sorce:
if url[0:7] == 'https:/':
r = requests.get(url, headers=HTTP_HEADERS)
path = folder_name + '/' + str(number) +'.png'
with open(path,'wb') as f:
f.write(r.content)
print('{}枚 取得・保存完了'.format(number))
number += 1
else:
continueなぜ、ヘッダー情報の定義をしてrequestの際に渡す必要があるかというと、サイトによっては非ブラウザからのアクセスを拒否しているためです。
ヘッダー情報を渡さない場合、403エラーとなります。
詳細は以下のページを参照ください。
自分の端末情報ってどう調べたらいいの?って方、以下サイトで簡単に調べられます。
osモジュールのmakedir関数に、引数としてフォルダ名と、exist_okプロパティ(Trueなので、存在してもOK)を私、フォルダ作成をしています。
そして、img_sorceリストからループ処理で、urlを取り出し、requests関数(引数にheader情報を渡す)で、レスポンスを取得。content情報をファイル名に拡張子png(jpg等でもOK)をつけ、ファイルパスを指定して保存しています。
くれぐれも、Webサイト側に負荷をかけないこと、取得した画像は著作権を考慮する等留意したうえでお楽しみください。
この記事が気に入ったらサポートをしてみませんか?