
ソフトウェア間での機能単位の実装コピーは簡単じゃない

「当社の旗艦プロダクトに搭載されている○○機能を、我々のプロダクトにも追加したい。簡単だろう?既にある実装をコピーして持ってくるだけなんだから」
ソフトウェアプロダクトの開発チームに対し、顧客やプロダクトオーナー、その他のステークホルダーが、このように話す場面に何度か遭遇したことがあります。それを聞いたソフトウェアエンジニアたちは、苦笑いしていたり、「またか」とうんざりしたため息を付いていたり。いずれにしても一様に、良い反応を返しません。
それは、異なるソフトウェア間での機能の複製(コピー)が、実際には簡単ではないからです。
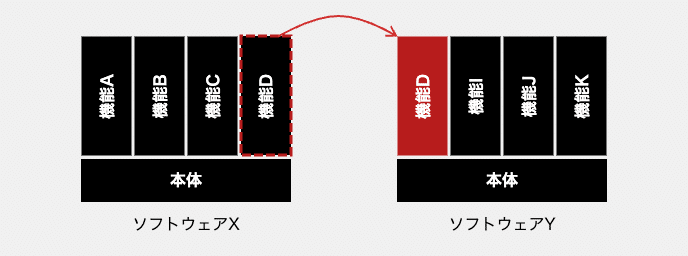
一般的に想像されるイメージ
様々な機能がどのようにしてソフトウェアに実装され、存在しているか。多くの人にとって、それは、ブラックボックスです。それでも頭の中には、自分なりの概念がぼんやりとモデル化・イメージ化されるものです。そして、ソフトウェア機能に対する一般的なイメージは、ブロックのようなものじゃないかと思っています。

機能Aのかたまり、機能Bのかたまり、機能Cのかたまり、といった具合に、それぞれの機能に必要な実装がまとまってパッケージングされ、ソフトウェア本体に整然と配置されていると言えば良いでしょうか。これは、ごく自然な思考に基づくイメージだと思います。まったくの見当外れでもありません。
ソフトウェアがこのイメージ通りであるなら、機能を別のソフトウェアに複製することは簡単です。下図のように、ソフトウェアXの機能Dが欲しいのであれば、その実装を複製してソフトウェアYに配置すれば終わりです。
が、このイメージは単純化され過ぎています。実際に複製するためのコストを知る上で考慮すべきポイントが、いくつも漏れてしまっているのです。
ポイント1. インタフェース
まず、ソフトウェアX向けに設計された機能Dの接続面(インタフェース)が、ソフトウェアYと上手く噛み合いません。
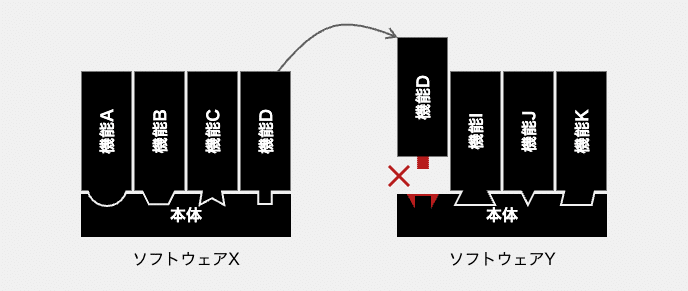
それぞれの機能は、搭載されるソフトウェア専用に設計されています。機能DもソフトウェアXのために作られました。そのため、機能Dの仕様がソフトウェアYと合わないのです。
このようなギャップを解決するために、機能Dの接続面をソフトウェアYの接続面に変換する「アダプタ」を作ることになります。複製先となるソフトウェアYの仕様に合わせ、機能Dの仕様を変換する中間層を新たに設計し、実装するということです。
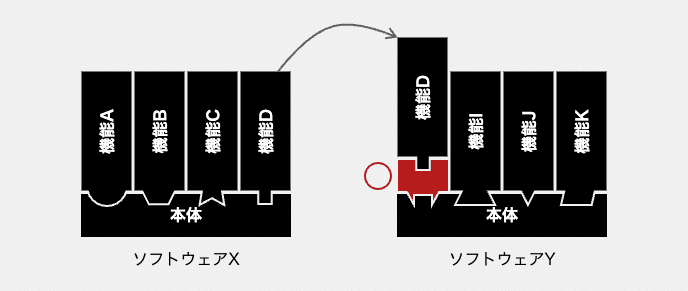
下図のように、アダプタを作らず、複製された機能D自体をソフトウェアYに合わせて改造することもあります。こちらの方が、複製方針としてはシンプルで、かつ柔軟性があります。
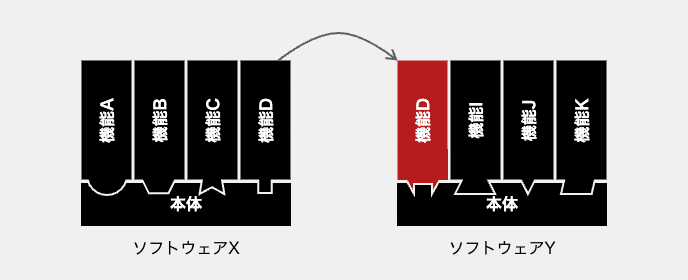
どちらの方針であっても、ここで支払うことになるコストの大きさは、ギャップの大きさ次第です。機能DとソフトウェアYの仕様ギャップが大きければ大きいほど、その解消に時間と労力をかけることになります。
ポイント2. プログラミング言語
1つの実行単位となるソフトウェアは、1つのプログラミング言語で実装されます。数多くの例外もあるのですが、これはソフトウェアを作る上での制約だと思って良いでしょう。例えばJavaとPythonが混在する単一のソフトウェアは、基本的に書けません。
下の図にあるように、互いに異なるプログラミング言語で書かれたソフトウェアXからソフトウェアYへの機能の複製はできないということです。
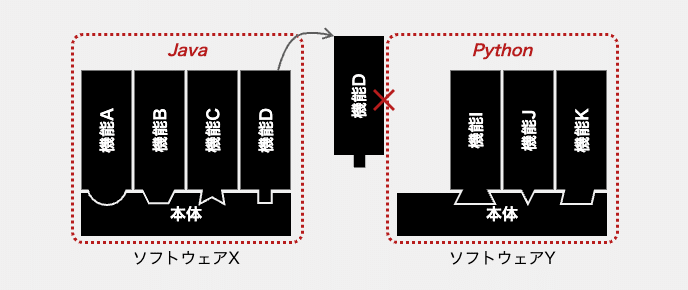
さすがにこれは、ソフトウェアプロダクト開発に関わる人であれば、誰でも理解していることだと思います。
ここで案外見落とされがちなのは、たとえプログラミング言語が同じであっても、プログラミング言語のバージョンが異なっているのであれば、バージョンを一致させる手間が発生するという点です。複製先のソフトウェアの実装に使われているバージョンに合わせ、複製するコードを修正することになるのです。プログラミング言語の一部、または多くの仕様が、バージョン間で非互換であることが原因です。
本節冒頭で「1つの実行単位となるソフトウェアは」と言いましたが、これが2つの実行単位となるソフトウェアであれば、プログラミング言語やバージョンの違いは関係なくなります。例えば、ネットワークを介したAPIの呼び出しであれば、2つのソフトウェアシステムの連携が可能となります。
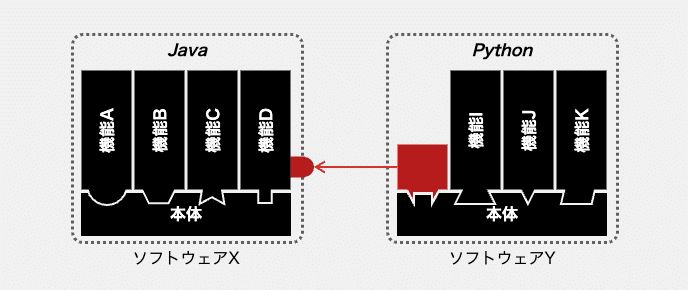
上図は、ソフトウェアXの機能DにWeb APIを追加したイメージです。ソフトウェアYにも、そのAPIを利用するコードが新たに追加されています。このように、APIを新たに実装するコストと、そのAPIを利用するためのコードを追加するコストが発生します。
この方式は、常に選択可能なわけではありません。基本的にこれは、機能を提供する側のソフトウェア(図中のソフトウェアX)が、バックエンドシステムである場合に採用しやすい方式です。機能を提供する側がユーザーインタフェースを含むフロントエンドのソフトウェアシステムであれば、選択肢とならないことも多いでしょう。選択できたとしても、機能を利用する側のソフトウェア(図中のソフトウェアY)が求める仕様に対し、実現できることが制限されることもあり得ます。
この方式は「複製」と言うより、後の節で取り上げる「共有」のいち形態です。このような共有では問題が生じる場合、次の図のように、大掛かりな改修によって複製を作ることになります。
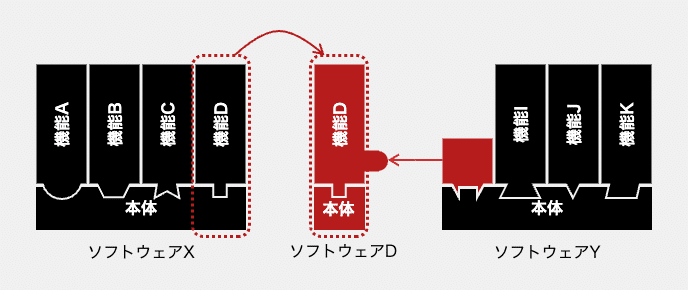
図では、ソフトウェアXを複製したソフトウェアDを置き、不要な機能を削除した上で、機能DにWeb APIを追加しています。
ポイント3. OSS
OSS(オープンソースソフトウェア)は、この20年ほどで大きく広がりました。今や、OSSとして提供されるライブラリやフレームワークなしにソフトウェアプロダクトを作り上げることは考えられません。2023年版の『オープンソース・セキュリティ&リスク分析レポート』によれば、調査した1703のソフトウェア(コードベース)のうち、96%にOSSが含まれており、1つのソフトウェアに含まれるOSSの数は平均で595という結果でした。OSS自体も、また別のOSSを利用していることが多いため、このような数字になるのでしょう。
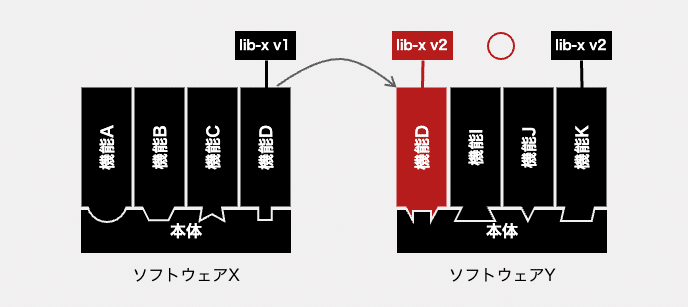
OSSの利用がこれだけ多いと、複製しようとする機能が利用しているいくつものOSSの中の一部が、複製先となるソフトウェア内でも利用されている可能性は高くなります。それ自体は問題ありませんが、同じOSSの異なるバージョンを利用していると、問題になることもあります。プログラミング言語によっては、同一ライブラリの異なるバージョンを1つのソフトウェア内で共存させられないからです。
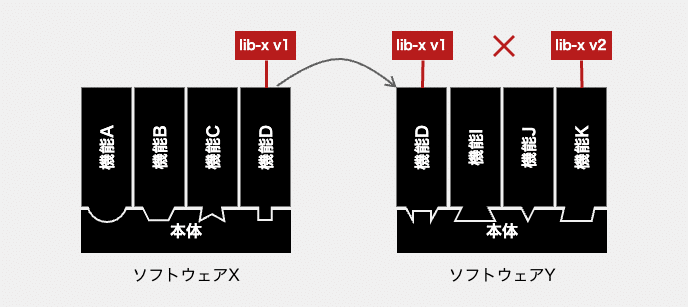
このようなバージョン衝突が発生した場合、バージョンを合わせるコストが発生します。複製対象となる機能に手を加えるか、複製先となるソフトウェアに手を加えるか。いずれにしても、バージョンの衝突を起こすOSSが1つだけとは限らないため、その対応はそれなりのコストを払うことになります。
ポイント4. データベース
データベースと接続されたソフトウェアなどめずらしくもありません。これも複製コストを大きく引き上げる要因となり得ます。
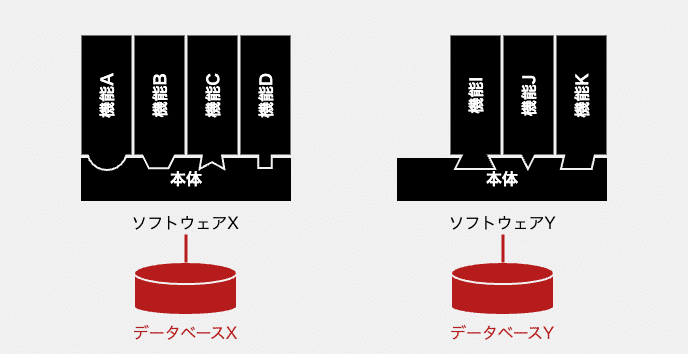
複製元となるソフトウェアXはデータベースXに接続されており、そこで動作してる機能DもデータベースXを利用しています。一方で、ソフトウェアYも、専用のデータベースYに接続されています。
ソフトウェアXとソフトウェアYは、それぞれ独立した異なるプロダクトなので、ソフトウェアYに複製する機能Dは、データベースXから切り離さなければなりません。次の図は、複製された機能Dに専用のデータベースDを新しく用意したイメージです。
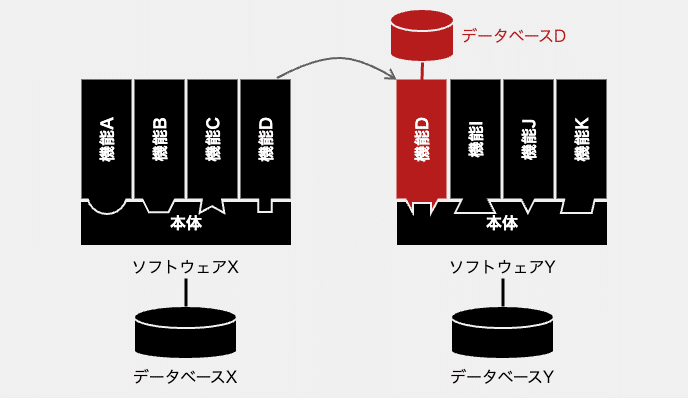
もちろん、データベースDを新たに用意せず、データベースYにデータを持たせることもできます。
いずれにしても、複製された機能Dがデータを操作するためのコードや、実際のデータ構造を改修することになり、これがなかなかの手間となります。
ポイント5. 内部構造と内部品質
ここまでの図では、機能をひとかたまりのブロック(コンポーネント)として描いてきましたが、ある機能を動作させるために必要なコードが、ソフトウェアを構成するソースコードの中で一箇所にまとまって存在するとは限りません。
ソフトウェアの内部構造が下図のような場合、機能Dの実装を取り出すためには、関係のないコードを引き剥がすなどの手間が必要となります。
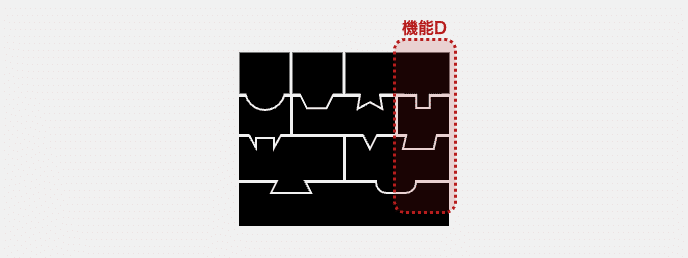
しかしこれはまだ、支払うコストとしてはマシな方です。機能Dという単位でコードはまとめられていませんが、整理された構造を持っています。これならば、必要なコードを抽出することは可能です。
すべてのソフトウェアの内部が、意図して設計された構造を持つわけではありません。むしろ、機能に必要なコードがあらゆるところに散らばって、他のさまざまな機能のためのコードと絡み合っているケースの方が多いでしょう。いわゆる「スパゲッティコード」や「大きな泥だんご」と言うやつです。
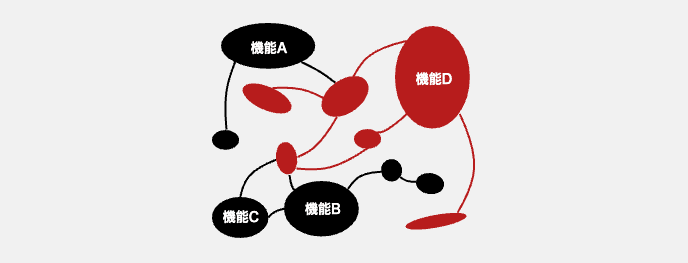
その上、複製元となるソフトウェアXの開発を担当するエンジニアでも、機能Dに関係するコードがどこに存在するのか、すべてを把握できているわけでもありません。複雑すぎるのです。
このような絡まったコードの中から、複製対象となる機能に関係するコードを抜け漏れなくすべて抽出することなど至難の業です。それだけに、多くのコストをかけることになります。おそらく、エンジニアがもっとも嫌う類の仕事でしょう。
また、図にもあるように、それぞれのコードの断片は、他の機能とも結びついていることも多いのです。このために、機能Dを複製したいだけなのに、関係のない機能Aや機能Bなどのコードまで複製に含めることになってしまいます。そうやって本質的には関係のないコードを複製してしまうと、複製先となるソフトウェアYのコードは肥大化し、今後の保守コストをより多く支払うことにもなります。
実際に私が見た酷いケースでは、複製先のソフトウェアのコードの中に、複製元のソフトウェアのコードが丸ごとすべて含められているといったものもありました。一部の機能を複製するためだけに、です。
ここで支払うことになるコストは、ソフトウェアの内部品質の悪さが主な原因です。内部品質の善し悪しが、ソフトウェア開発のパフォーマンスを左右するということが、こういったことからもよく分かります。
共有もまた簡単じゃない
複製された機能は、複製元の機能とは独自の進化の道を歩むことになります。ここまでの例で言えば、ソフトウェアYの機能Dは複製されたものであり、もはやソフトウェアXの機能Dとは異なる存在です。ソースコードも別々に管理され、それぞれに異なる変更が加えられていくことになります。時間が経つにつれ、その差は徐々に広がっていくでしょう。
しかし、そのような差を好まず、むしろ共通化したいという要求もあり得ます。複製というアプローチでそれを実現するには、複製されたすべての機能に対して、常に同じ変更を加えなければなりません。そのコストは、複製数が1なら2倍、複製数が2なら3倍となってしまいます。
そこで、複製ではなく、機能を単一のコンポーネントとして共有する方式が採られることもあります。共有であれば、ソースコードは1か所で管理され、そこに変更を加えれば、そのコンポーネントを利用する全てのソフトウェアに同じ変更が反映されることになります。これなら2重コスト、3重コストを避けられそうです。
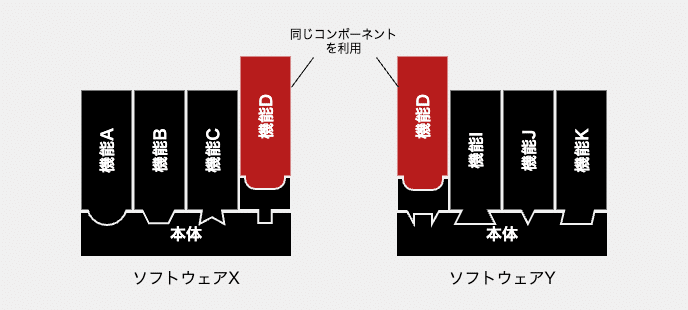
共有方式も、基本的には複製方式と同様の複雑さを抱えていますが、また別の問題にも苦しむことになります。それは、調整コストです。
機能Dを共有するソフトウェアXとソフトウェアYは、それぞれ異なるプロダクトであるため、機能Dに求められる仕様がまったく同じであるとは限りません。ソフトウェアXに必要な追加仕様が、ソフトウェアYには不要かもしれません。そういった仕様の調整を、ソフトウェアXのプロダクトチームと、ソフトウェアYのプロダクトチームの間で頻繁に話し合わなければならなくなります。
また、共有する機能Dに対する追加開発や改善の優先順位を決めるのも一苦労です。ソフトウェアXのプロダクトチームから要望された変更と、ソフトウェアYのプロダクトチームから要望された変更のどちらを先に進めれば良いのか。ここでも調整コストが必要になります。
調整コストは、共有先となるプロダクトが増えるほど、指数関数的に大きくなります。共有化は、こうして遅々として開発が進まないがんじがらめのプロジェクトになってしまうおそれがあることを認識しておかなければなりません。
設計とアーキテクチャはエンジニアに任せる
以上のことから、機能の複製が簡単であるかのように扱われることに対し、ソフトウェアエンジニアが不満そうにする理由がよくわかります。そもそも不可能である場合もあれば、多大な労力と時間をかけて対応しなければ実現できないからです。
この認識のギャップが埋まらなければ、複製に関してエンジニアが作成した見積りや計画を巡って、関係者間で衝突が生じます。そしてここでも、エンジニアは時間をかけて、自分たちが作成した見積りや計画の妥当性を説明するコストを支払うことになります。むしろ、この「説明するコスト」を嫌う傾向の方が強いのかもしれません。それは、説明すること自体を面倒がっているというより、いくら説明しても結局は理解を得られないことも多いと、経験を通して学習しているからです。そうして不幸なケースでは、実現不可能な計画を強いられ、約束された炎上プロジェクトに突入していくことになります。
ソフトウェア上の機能をどのように実現するかは、ソフトウェア設計やアーキテクチャの問題です。そして設計もアーキテクティングも、ソフトウェアエンジニアが有するスキルの中で、最も高いレベルに位置する能力や経験を要する活動です。複製が良いのか、いちから実装する方法が良いのか、あるいは……。どんな選択肢があって何が最適であるかは、アーキテクトやエンジニアに任せるべきでしょう。その上で、関係者で集まって、開発期間や費用面などの変数をもとに、いくつかある選択肢の中から手段を選ぶというアプローチが合理的です。
もし、実装を複製して再利用できなくても、複製元となったソフトウェアの仕様や設計をナレッジとして引き継ぐだけでも大きなメリットがあります。対象となった機能は、複製元のソフトウェア上で何人ものユーザーに使われ、繰り返し改善を続ける中で、時間をかけて洗練され磨き上げられていったものです。そこで費やされた時間をショートカットできるというだけでも十分に価値があるのではないでしょうか。
この記事が気に入ったらサポートをしてみませんか?