数理最適化とは②

前回に引き続き、機械学習との違いについて調べてみました。
自分なりにすっきりしたのでまとめます。
違い1:モデルの作り方
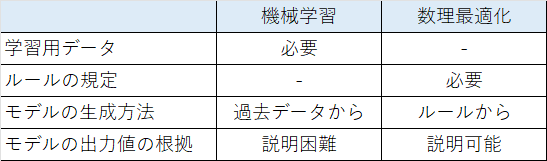
・機械学習:ラベル付けされたデータを使って学習し、モデルを作成
・数理最適化:ルールからモデルを作成
機械学習は、過去のデータを使って学んだ結果から予測するものです。
そのため、モデルを作るためには、過去データが必要です。
数理最適化はルールが決まっていればモデルを作ることができるため、過去データは必要ありません。
下記ページでは「最適化といえば”目的関数”と”制約”が揃っており、この2つだけで説明がつくものを指します」と記されています。
目的関数と制約がルールにあたります。
機械学習では、ルールを数式で規定することは求められません。
数理最適化ではルールを数式で規定することでモデルを作ることができます。
「モデルの作り方」という違いの中には
・データの有無
・ルールの規定
・モデルの生成方法
などいくつかの違いが含まれています。
違い2:モデルの出力値の根拠
・機械学習:ブラックボックス
・数理最適化:ホワイトボックス
機械学習は過去のデータから学習したパラメータを使った予測です。
そのため、そのパラメータがどのようなものか、何を根拠にそうなっているのかを人間が説明することは難しいです。
しかし、数理最適化はルールを元に結論を出しているため、下した判断の根拠を説明することができます。
なぜそのような結論に至ったのか、ということを人は把握したくなります。
その結論によって自分たちの行動を決めるためです。
そのため、機械学習でも根拠を示すことのできるAIの研究も進められています。
まとめ
違いをまとめてみました。
機械学習と数理最適化の違いがよくわからないという人が多いです。
私もわかりませんでした。
この2つを混同してしまったのは、両方とも使用者に対して「問いに対する答え」を出すためです。
その「答え」の意味するものは違うのですが、使用者は「何かしらの答えを出してくれる」ことの方に注目してしまいます。
「入力」と「出力」が似たようなものは、過程はどうであれ同じものに見えてしまいます。
これが私が混同していた理由でした。
裏を返すと、使用者にとって何かしらの指標を示してくれるのであれば、それが機械学習であろうが数理最適化であろうがどっちでもよいです。
どちらが優秀というわけではなく、解決したい「問題」と「状況」に対してどちらが適切かをよく考えて選択するのがよさそうです。
モデルを開発する際の大きな違いは、「学習用データが必要かどうか」かなと思います。
機械学習ではデータ収集と前処理がかなり大変です。
モデル開発中にデータ収集からやり直しになったという話はよく聞きます。
他にもメリットはありますが、学習用データが不要という点はかなり大きいと思いました。
この記事が気に入ったらサポートをしてみませんか?