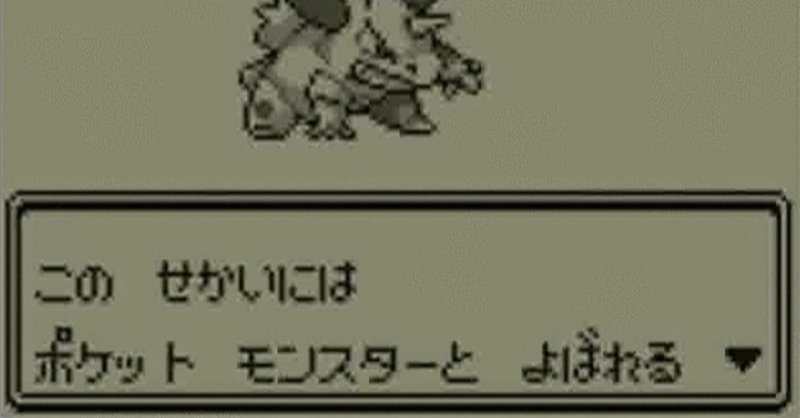
ポケモン てきな メッセージに へんかんする プログラム ▼

かの ゆうめいな ゲーム
ポケットモンスター の がめんで
▼
もちいられる
メッセージひょうじを
▼
さいげんする プログラムを
つくりました!
▼

(「ポケットモンスター赤・緑」のゲーム画面より)
なんで こんな ことを
したのかって?
▼
たんに わたしが ポケモン
すきだからです
▼
2020ねん 2がつ 27にち
24しゅうねん おめでとう!
▼
COTOHA とは

COTOHAは
NTTコミュニケーションズ が
かいはつした
▼
にほんご じしょを かつようした
しぜんげんごしょり
▼
おんせいにんしきAPIです
▼
にほんご を かいせきして
▼
こうぶんかいせき
キーワードちゅうしゅつ
▼
かんじょうちゅうしゅつ
▼
おんせいにんしきなどが できる
スゴイ やつです
▼
これを りようして
ポケモン てきな メッセージを
つくるPythonスクリプトです
▼
しょうさいは いかの Qiita
の ページを みてください!
▼
ライセンス
この きじの いんようぶぶんと
ぼうとうの ゲームがめんを
▼
のぞく ほんぶんは
CC BY 4.0で
▼
ライセンスしています
▼
ソースコードは
MITライセンスです
▼
ソースコード
どうさかんきょう
・Python 3.6.9
・COTOHA API
GitHubも みてください
▼
import requests
import json
import sys
import jaconv
import re
from kanjize import int2kanji, kanji2int
BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/"
CLIENT_ID = "COTOHA Client ID を いれる"
CLIENT_SECRET = "COTOHA Client Secret を いれる"
def auth(client_id, client_secret):
token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
headers = {
"Content-Type": "application/json",
"charset": "UTF-8"
}
data = {
"grantType": "client_credentials",
"clientId": client_id,
"clientSecret": client_secret
}
r = requests.post(token_url,
headers=headers,
data=json.dumps(data))
return r.json()["access_token"]
def parse(sentence, access_token):
base_url = BASE_URL
headers = {
"Content-Type": "application/json",
"charset": "UTF-8",
"Authorization": "Bearer {}".format(access_token)
}
data = {
"sentence": sentence,
"type": "default"
}
r = requests.post(base_url + "v1/parse",
headers=headers,
data=json.dumps(data))
return r.json()
def ne(sentence, access_token):
base_url = BASE_URL
headers = {
"Content-Type": "application/json",
"charset": "UTF-8",
"Authorization": "Bearer {}".format(access_token)
}
data = {
"sentence": sentence,
"type": "default"
}
r = requests.post(base_url + "v1/ne",
headers=headers,
data=json.dumps(data))
return r.json()
# カタカナ以外の単語のみひらがなに変換し、
# 金額表現が含まれる場合は "円" の漢字だけ残して変換する
def conv_word(token, pricelist):
if len(pricelist) > 0:
price = pricelist[0]
if token["form"] == price:
price = pricelist.pop(0)
# 漢数字で表現されている場合はアラビア數字に変える
if not re.search('[0-9].+', price):
price = str(kanji2int(price.replace("円", ""))) + "円"
# 半角数字を全角数字にして返す
return jaconv.h2z(price, digit=True, ascii=True)
if token["form"] != token["kana"]:
word = jaconv.kata2hira(token["kana"])
else:
word = token["kana"]
return word
# 金額表現が含まれる語をリストに入れる
def make_pricelist(ne_document):
pricelist = list()
for result in ne_document['result']:
if result['class'] == 'MNY':
pricelist.append(result['form'])
return pricelist
if __name__ == "__main__":
document = "君は今、カントー地方への第一歩を踏み出した!" # サンプルテキスト
document = "強いポケモン、弱いポケモン、そんなの人の勝手。本当に強いトレーナーなら、好きなポケモンで勝てるように頑張るべき。" # サンプルテキスト
document = "秘密のポケモン、コイキングがなんとたったの500円!どうだい買うかね?" # サンプルテキスト
args = sys.argv
if len(args) >= 2:
document = str(args[1]) # 引数があればサンプルと入れ替え
access_token = auth(CLIENT_ID, CLIENT_SECRET)
parse_document = parse(document, access_token)
ne_document = ne(document, access_token)
pricelist = make_pricelist(ne_document)
result_list = list()
for chunks in parse_document['result']:
text = "" # 空のテキストを用意しておく
for token in chunks["tokens"]:
word = conv_word(token, pricelist)
if "固有" in token["features"]:
text += word + " " # 全角スペースを足す
elif token["pos"] == "句点" or token["pos"] == "読点":
if "疑問符" in token["features"]:
text += "?\n"
elif "感嘆符" in token["features"]:
text += "!\n"
else:
text += "\n"
else:
text += word
result_list.append(text)
line = ""
lineCounter = 0
for word in result_list:
if len(line) == 0:
line = word
newLine = line
else:
newLine = line + ' ' + word
if '\n' in newLine:
if len(newLine) > 16:
print(line)
print(word)
else:
print(newLine);
lineCounter = 2
line = ""
elif len(newLine) <= 16:
line = newLine
else:
print(line); lineCounter += 1
line = word
if lineCounter >= 2:
print(" ▼"); input()
lineCounter = 0
print(line, end='') # 最後の改行を除いているご寄進ください。念を送ります。