
読書感想文「Vision Transformer 入門」

先日,今年の 9 月末に出版された「Vision Transformer 入門」を 技術評論社様 から献本いただきました.
本記事はその読書感想となります.
Computer Vision (CV) の分野に Transformer を応用する Vision Transformer (ViT) の論文が ArXiv に投稿されてから二年が経ちました (Oct. 2022 現在).
論文が発表されてから現在に至るまで僅か二年の間に,私が知る限りでも非常に多くの ViT に関する研究論文が発表されています.研究が盛んなのはとても良いことですが,これらの研究にキャッチアップし知識を体系立てていくのはとても大変です(私は既に挫折しています).
そのような中でいち早く出版された本書は,今後の研究動向を追いかける際のバイブルや出発点となりそうです.
また,本書の著者陣は CV 分野の第一線の研究者の方々であり,本に盛り込む内容の取捨選択・解説の信頼度も含め,他の web 等の記事とは一線を画していると思います.
その点で,ViT のサーベイ論文が書籍化されたのが本書であるといっても良いのかもしれません.
そこで,本記事では CV の「非研究者」の視点で,参考になった点を章別に述べていきたいと思います.
1. Transformer から ViT への進化
Transformer の応用分野を
自然言語処理 (2017 ~ )
Vision and Language (2019 ~ )
CV (2020 ~ )
と,論文の発表年順に紹介しています.
本章では,マイルストーンとなった論文や関連論文,ならびにそれらが発表された学会も含め,Transformer の関連項目を包括的に紹介しています.少し後の章になってしまいますが,第 6 章「ViT 派生手法の分類」にある分類マップ(図6.1)と照らし合わせて読むと,さらに理解が進むかもしれません.
Hot な分野というのは研究数が多く煩雑になりがちなため,研究動向を把握するのは大変です.本章では研究変遷も絡める形で説明してくれているため,理解がしやすくなっている印象を受けました.
紹介されていたモデルの中では,放射線画像で事前学習した Transformer-based の Vision and Language モデル MedViLL
Moon JH, Lee H, Shin W, Kim Y-H, Choi E. Multi-modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training. IEEE J Biomed Health Inform 2022:1–10.
が個人的には気になりましたので,近々読んでみたいと思いました.
(その後読みましたので,140 文字以内で簡潔にまとめました: https://twitter.com/Maxwell_110/status/1584664781532766208)
2. ViT の基礎と実装
実際に手を動かして PyTorch で ViT を実装してみよう,という章です.
これまでに,ViT の原理を解説する web 記事は多く目にしてきましたが,本章ほど丁寧に解説しているものはなかったように思います.
本章と似た形で,論文のコアとなるモジュール等を PyTorch で実装して紹介している,labml.ai という有名なサイトがあります.
labml.ai には,コードと各コードブロックに対応した annotation 形式での解説しかありません.一方で,本章は「図 及び 文章」・「数式」・「実装」と,三つの視点を交えてとても丁寧に解説をしています.解説用の図の描画方法を変更した場合に注釈をいれたりなど,読者の誤解や脱落を防ぐための配慮が随所になされている点も素晴らしいと思いました(見習いたいものです).
本章と他の web 記事を読み終えた後の理解度を比較した場合,その差は大きなものとなるでしょう.
これから ViT を学習しようという方には,must reading であると自信をもってお薦めできる章です.また,Transformer の encoder の学習にも活用できると思います.
3. 実験と可視化による ViT の探求
CNN と ViT の性能の比較実験を通して,ViT の性能改善に重要となる key point を解説している章です.合わせて,self-attention の attention map を使用した方法(https://arxiv.org/abs/2005.00928)と Grad-CAM like な Transformer Explainability(https://arxiv.org/abs/2012.09838)という XAI の解説もしています.
ViT が CNN の性能を上回るためには膨大なデータ(JFT-300M 等)による事前学習を前提としますが,その点を実験を通してしっかりと伝えています.また,データ拡張(data augmentation: DA)の重要性と,どの DA が性能に影響するかを実験(ablation study)している点も,説得力のある解説といえるのではないでしょうか.私も Kaggle を通して,マルチクラスの分類問題における CutMix の強力さは経験的に認識しており,本章の DA の実験結果は感覚的にも相違ないものでした.
4. CV タスクへの応用
Transformer の
画像認識
物体検出
セグメンテーション
動画認識
オブジェクトトラッキング
3-D ビジョン
等の分野での応用に関して,ベンチマークデータセットや CNN ベースの手法との比較等をメインに解説した章です.
取り扱っている分野が多いため,CNN ベースの手法に関しては駆け足気味での説明しかなされていませんが,Transformer を導入することで CNN ベースの手法における問題点がどのように改善されたのか,というポイントを抑えた解説がなされています.
紹介されていたモデルの中では,医療画像の Transformer-based のセグメンテーションモデルである
Yang D, Myronenko A, Wang X, Xu Z, Roth HR, Xu D. T-AutoML: Automated Machine Learning for Lesion Segmentation using Transformers in 3D Medical Imaging 2021.
が気になりましたので,こちらも時間をみつけて読んでみたいと思っています.
5. Vision and Language タスクへの応用
Vision Question Answering(画像に関する質問への回答)
Image Captioning(画像に対する説明文の生成)
Embodied AI(ロボットを想定した様々なモーダリティタスクに対応した AI モデルの構築)
Text-to-Image Generation(テキスト情報による画像の生成)
などのタスクにおける Transformer の応用を解説している章です.4 章と同様に,タスクとそれに付随したベンチマークの説明に続き,Transformer 導入以前・後の手法を対比させる形で解説をしています.
今年の夏から世間を賑わせている stable diffusion こと Rombach et al. の Latent Diffusion Models (https://arxiv.org/abs/2112.10752) は執筆の時期的な関係のためか本書内では言及されていませんが,DALL・E2 (http://arxiv.org/abs/2204.06125) などの今年前半に発表された最新モデルは簡単な解説がされています.
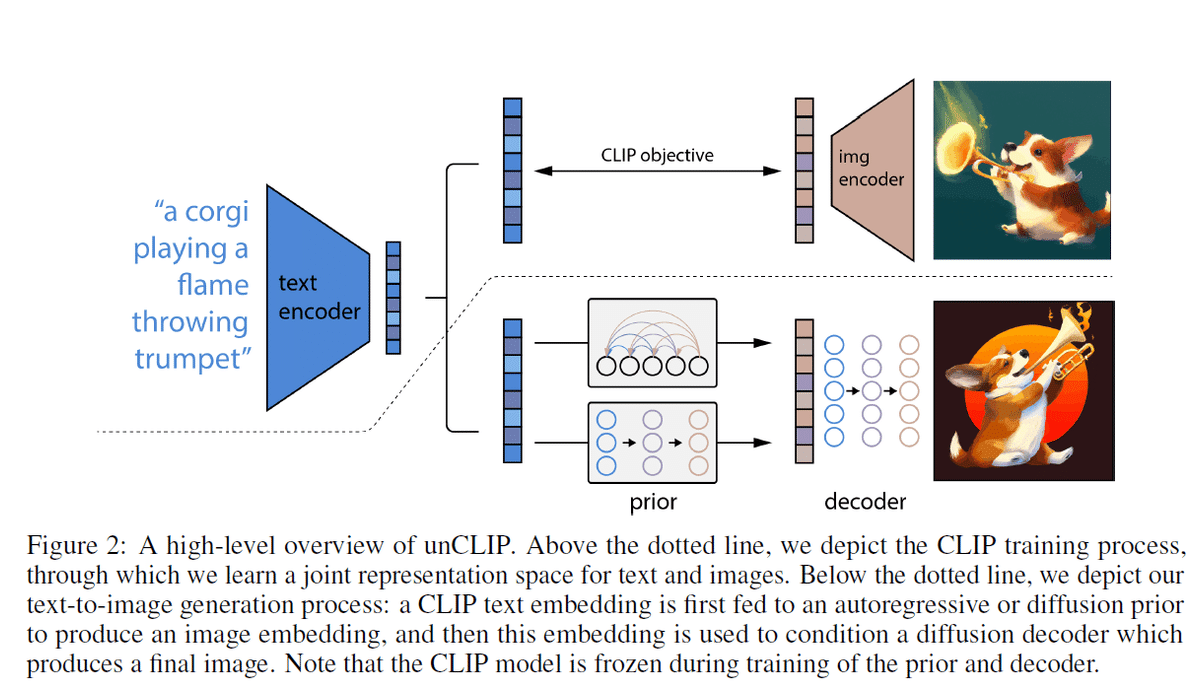
本章の内容は,2022 年のトレンドといわれるマルチモーダルや foundation model に関して勉強する際にも役にたつでしょう.
6. ViT 派生手法の分類
ViT が発表されてから 2022 年前半に至るまでの様々な派生手法をまとめ,代表的な手法を解説した章です.
特に,章の冒頭に記載された派生手法の分類ダイアグラムは必見といえるでしょう.全 100 近くの手法が一頁分の図にまとめてられています.
数多くの手法の中から
Swin Transformer (Shifted-window Transformer)
DeiT (Data-efficient image Transformers)
CvT (Convolutional Vision Transformer)
SegFormer
TimeSformer
MAE (Masked AutoEncoder)
の解説がされています.
深く踏み込んだ説明はなされていませんが,各手法のキーポイントはおさえられていますので,概要を把握することができると思います.
7. Transformer/ViT の謎を読み解く
第 7 章と 8 章は,どちらかといえば研究者視点で Transformer 及び ViT にまつわるいくつかの疑問点を議論している章です.
第 7 章では,Transformer における
位置埋め込み(positional embedding)に 三角関数を使うのはベストなのか?位置埋め込みは学習するようにした方が良いのか?位置埋め込みの入力位置はどの層が良いのか?
Multi-Head Self-Attention の多様性の確保の仕方
Feed Forward Network の果たす役割
Layer Normalization の挿入位置はどこが良いか(post/pre)?そもそも必要?
といったトピックを,それらに関する研究を列挙・解説した上で議論しています.特に私の場合は,三角関数を使った positional embedding の目的・意味の理解が浅かったので,本章を読むことで理解がより進みました.
第 8 章では
MLP-Mixer (https://arxiv.org/abs/2105.01601) の紹介
ViT と CNN は下層(入力側)において局所特徴量を捉えている
ViT は形状を,CNN はテクスチャを捉えやすい
ViT は全層で大域的な情報を捉えている
ViT と CNN の敵対的攻撃に対する頑健性とその違い
CNN と ViT の hybrid model のもつ可能性
などのトピックを,第 7 章同様に議論しています.
新しい提案手法がでてくる都度,本当にその手法が良いのか,なぜその手法なのか,それともただ単にベンチマークに overfit しているだけではないのだろうか等と,疑問は尽きません.Transformer や ViT に関しても多くの研究者の間でそういった疑問が多く湧いたことでしょうし,今も尚,現在進行形で謎を解き明かす研究が行われていることと思います.
その点で,研究のほぼ最前線の内容を解説した第 7, 8 章はとても貴重な内容でした.
個人的には,CNN を入力側に使用した ViT が良さそうだと直感的に思っていましたが,その考えをサポートする最新の研究事例を知ることができて良かったです.
8. 総括
最後に,全体を通しての感想を箇条書きで記して筆を置きたいと思います.
とても内容の濃い本でしたので,読了するのに時間がかかりました(参考文献に寄り道したせいもあるかもしれません).派生手法を含むとはいえ,一つのモデルに本一冊分の分量を費やして解説するという時点で,内容が濃いのは当たり前なのかもしれません.その意味でとても贅沢な本であるとも言えそうです.
全体を通して,第 2 章「ViT の基礎と実装」以外は参考文献をしっかりと参照しながらでないと深い理解を得ることはできないのではないかと思いました.とはいえ,内容が包括的で多岐に渡っているにも関わらず本一冊に納めていますので,仕方のないことだと思います.最低でも CNN を使用した手法に対する事前知識はあったほうが良いでしょう.そして,本書で紹介されている参考文献の数は相当な量です.
第 2 章の説明の分かりやすさは特筆に値します.ViT のコアコンポーネントの原理はこの章だけでも十分に理解できると言えるでしょう.
第 7, 8 章「Transformer と ViT の謎を読み解く」は,書籍では滅多にお目にかかれない深い洞察が記された章です.これから ViT の派生手法や改善手法などを研究していこうという院生の方々にとっても,リサーチクエスションを設定する上で参考になるのかもしれません.個人的には一番面白く読めた章でした.
それでは,長くなってしまいましたが,読書感想文を終わりにしたいと思います.最後までおつきあいいただきありがとうございました.
また,別の感想文でお会いしましょう.
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?