
スマートスピーカーでビジネスを考える際に気をつけたいデータの話

データ領域はオンラインから、日々の生活に直結するオフラインへと徐々に広がってきています。日本でも、スマートスピーカーを始めとして家の中でオフラインデータを提供する週間が広がりつつあります。
今回の記事では、特にスマートスピーカーに限定してユーザー視点でオフラインで提供するデータに関するプライバシー侵害の脅威と、事業者視点でのデータの取得リスクに関して紹介したいと思います。
スマートスピーカーとは
スマートスピーカーとは対話型の音声操作に対応したAIアシスタント機能を持つスピーカーで、内蔵マイクを活用して音声を認識することで情報を検索したり、連携した家電を操作したりする事ができるスピーカーです。
2018年12月に電通デジタルが行った調査によると日本国内でのスマートスピーカーの普及率は約6%で、Google Homeが首位の2.9%、AmazonのAlexaが次いで2.4%、そこからLINEのCloverなどのプレイヤーが続きます。
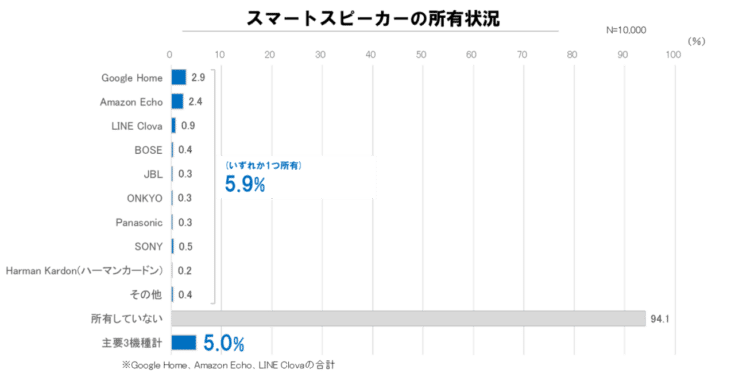
(画像:国内のスマートスピーカー普及率は約6%、認知率は約76%、電通Dが調査レポートを公開)
一方、米国ではVoicebotが紹介するレポートで成人人口に当たる2億5500万人に対して、2019年1月で約6640万台(約26%)、2020年1月には8770万台(34%)と3割以上の普及率まで拡大して来ています。
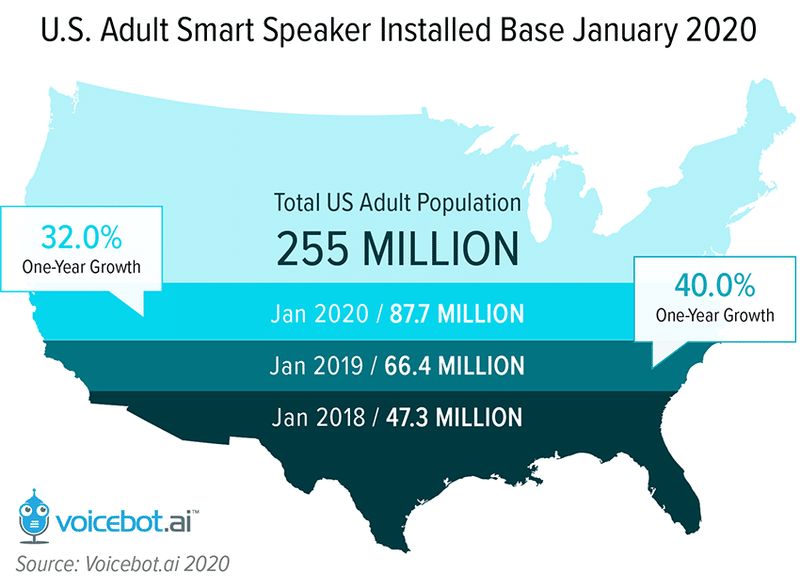
(画像:米国のスマートスピーカーの普及率は34.4%に達し、メーカ別シェアはAmazon53%、Google31%に)
年率で見ると成長率は少し鈍化しているものの、引き続きユーザー数の拡大が期待されています。日米で差が出る背景としては、文化的な問題(話すと書く)や正確性の問題(日本語での反応)などが利便性に関わってくるという事が考えられます。
今後、スマートスピーカーは家の中だけでなく、オフィスや商業施設などの空間での利用に加えて、内蔵された仕組みを応用する事で音声で認識が必要な様々な場面への応用が検討されています。
利用シーンと回数が増えるにつれて私たちの日々の生活で必要な情報をデータとしてデバイスに提供する事になり、明確な個人データとして処理が行われます。
昨今ではスマートスピーカーに対する個人データ利用に関して懸念する声も徐々に広がりつつあり、各社が対応を始めています。
特に懸念されるポイントとしては、AlexaではSkill、Google HomeではActionと呼ばれる開発者が第三者的に仕組みを提供した際の個人データ利用に関する問題です。
"目的外利用" に加えて、"透明性" や "データガバナンス" の問題もいくつか研究結果を通じて問題点として取り上げられています。
スマートスピーカー内でのデータ循環の仕組み
Amazon EchoやGoogle Home内でのデータの流れは以下のフローで処理が行われます。ポイントとしては、Amazon、Google以外に開発者が提供するクラウド上でユーザーリクエストが送信される点です。
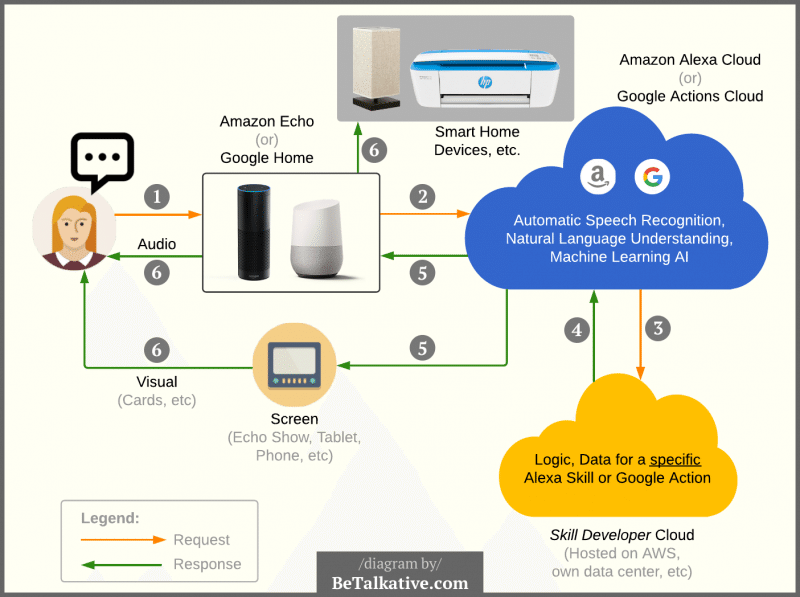
(画像:How Alexa Skills and Google Actions Work)
①ユーザーが声でデバイスに対して質問や特定の指示を行います。
②デバイスはAmazon、Googleのクラウドにリクエストデータを送信します。送信されたリクエストデータはクラウド上で、自動音声認識(ASR)技術を活用して録音データを文字列に変換し、自然言語理解(NLU)技術を活用して文字列のテキストデータから重要なキーワードを抜き出します。
③抜き出された整形データは開発者のサーバーへ転送されます(AWS、もしくは自前のサーバーなど)。開発者のサーバー上で整形されたリクエストデータの処理を行います。
④開発者のサーバー上で処理を行いAmazon、Googleのクラウド上にレスポンス作業を行います(応答)。応答データは画像や音声、テキストなどでレスポンスを行います。
⑤レスポンスは音声やテキストだけでなく、Amazonのクラウドを通じてAlexaアプリにビジュアルとして表示させる事も可能です。
⑥最終的にはユーザーに対してテキストや音声でのフィードバック、画像などでのビジュアルでのフィードバックを行います。
一連の流れを確認すると開発者がスマートスピーカーの機能を開発し、Alexaユーザーがリクエストしたデータを処理して、レスポンスしている事がわかります。
この機能をAmazon Alexaの場合は "Skill" と呼び、Google Homeの場合は "Action" と呼んでいます。
(動画:How Alexa Skills Work)
データの流れを仕組みから整理してみると、Amazonのクラウド上だけでなく、Skillを提供する開発者側のサーバーに保存されるデータも存在します。
開発者側で保存されるデータが個人データに該当する場合は、プライバシーポリシーを通じて、データ主体(データを提供するユーザー)に対して利用目的等を説明する必要があります。
スマートスピーカー のデータ処理で懸念されているのは「スピーカーを通じて取得したデータの第三者提供及び処理」の問題が該当すると言われています。
具体的に問題になる可能性があるポイントに関して、クレムゾン大学の研究結果から紹介したいと思います。
クレムゾン大学で実施されたAlexa、Google Homeに関する調査
クレムゾン大学ではスマートスピーカーに関する調査を実施しています。
64,720件のAmazon Alexa Skill、2,201件のGoogle Home Assistant Actionを調査対象としてデータ分析を行い、プライバシーポリシーに関する問題点をポイントにまとめて発表しています。
研究ペーパーの中では "Inconsistency" と呼ばれる、デバイスとSkill、Action間でのポリシー設計の不一致に関して問題が指摘されており、データコントローラー(Amazonや開発者)のアカウンタビリティ(個人データに対して明確な責任を示しているか)に対する欠陥が指摘されています。
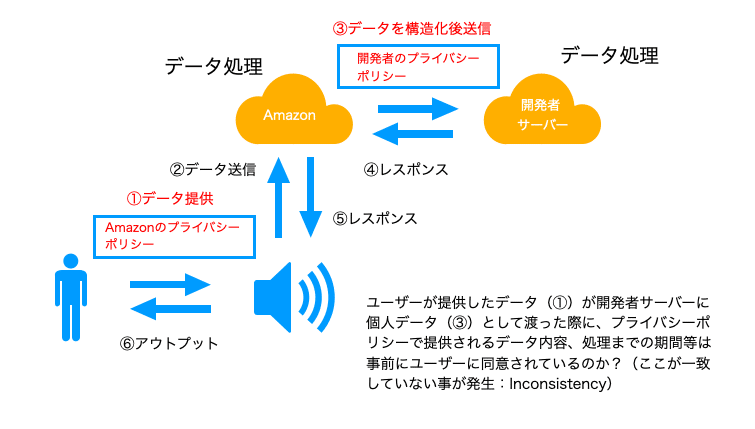
ポイントとしては、プライバシーポリシーがAmazonと開発者双方に存在した際に、別々の方針を持っている時に問題が発生します。同じ個人のデータを取り扱うとしても、ユーザーに対して約束した事が双方に異なると矛盾が見えて来ます。
クレムゾン大学の調査では、こういった矛盾点を分析を通じて理解し、ペーパーを通じて発表しています。
方法としては、クローラーを開発しSkillアプリのID、アプリ名、説明内容、プライバシーポリシーリンクを取得します。プライバシーポリシーに関しては、複数の形式で表示(HTMLページ、PDF、Googleドキュメント、txtファイルやその他)されているためそれぞれ照合します。プライバシーポリシー上での表記の抽出に関しては神経言語プログラミング(NLP)を活用し、問題のあるプライバシーポリシーの抽出を行います。
検証1:Inconsistency要素の検出
Inconsistencyのポイントとなる点としては、以下の要素が影響してくる事になります。
・開発者が提供するSkillが取得するデータは開発者アプリのプライバシーポリシーで明記されているのか?
・仮に明記されていない場合はAmazonのプライバシーポリシー上サービス提供できない事になるが、プライバシーポリシーに明記しない状態で存続しているアプリはあるのか?
特にAmazonのプライバシーポリシー上サービスを提供できなくなるというのは、開発者にとっても重要なポイントになります。
先ずは、Amazon Skillアプリのプライバシーポリシー提供状況に関してグラフで見ていきたいと思います。
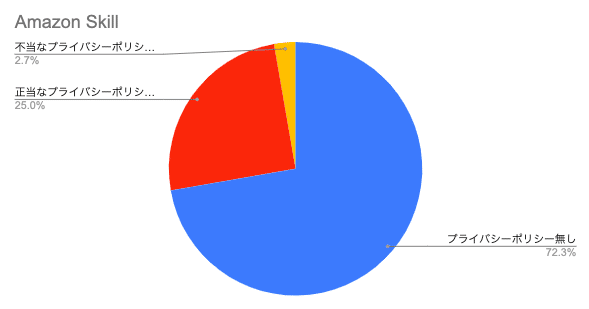
前アプリ総数64,720件のうちプライバシーポリシーを有している割合が約28%という結果になりました。開発者側で証明書発行の際にプライバシーポリシーを明記するかどうかを選択できるようになっており、データを取得する場合でも提供していなかったと考えられます。
一部不当なプライバシーポリシーを提供しているアプリも見受けられました。ここではいくつかのケースを紹介したいと思います。
・Rubetek(スマートホームソリューションを提供するRubetek)
Rubetekのケースではアプリページのプライバシーポリシーからのリンクがサイトへとアクセスする同線として設計されています。しかしリンク先はプライバシーポリシーではないため問題になっています。
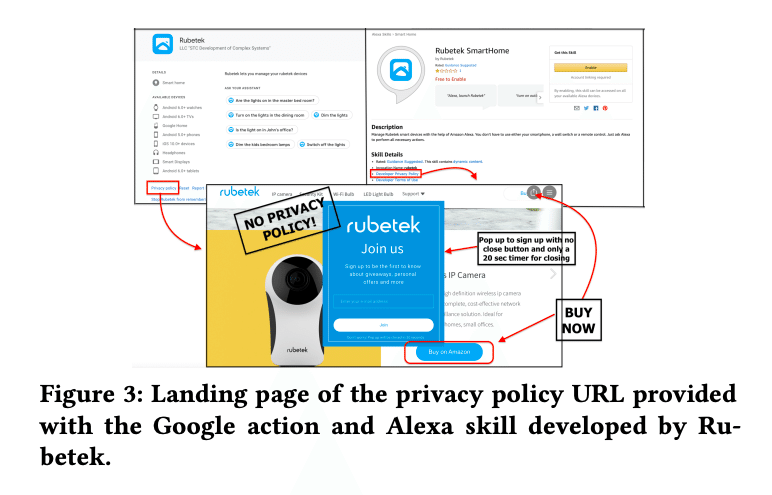
(画像:Measuring the Effectiveness of Privacy Policies for Voice Assistant Applications)
非常に細かいポイントですが、プライバシーポリシーリンクからの動線設計は非常に重要なポイントになります。リンクが別URLへアクセスするように設計されていたり、リンクが切れているなど確認が必要になります。
これ以外にも、プライバシーポリシーの使い回し(別のところと同じものを利用する)ケースも1,783件AmazonのAlexaでは見られたという事です。
検証2:Amazon、Googleが提供するアプリのプライバシーポリシー要素
AmazonのAlexaでは "Weather" と呼ばれるスキルアプリを提供しています。これは、すぐに利用できる物で提供元はAmazonです。問題となっているのは、利用する位置情報データに対するプライバシーポリシー表記です。
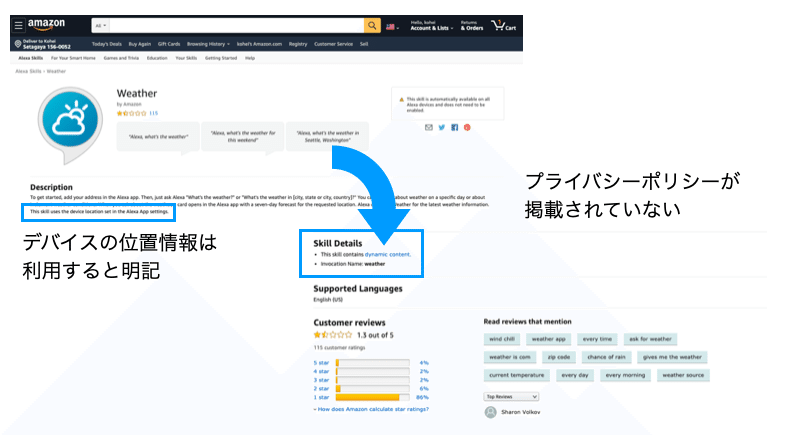
デバイスを通じて位置情報を取得すると明記しつつも、プライバシーポリシーを掲載していない点が懸念点として考えられます。
検証3:アプリのプライバシーポリシーの記載内容要素
アプリ上でプライバシーポリシーが掲載されていた場合でも、明確に個人データ取得の目的、及び利用に関して明記されていないケースもあります。
その場合は、AmazonやGoogleが事前に定義する開発者向けのプライバシーポリシーに準拠していない可能性も考えられます。
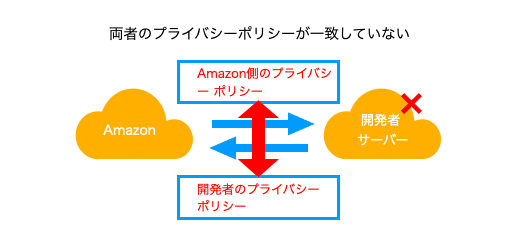
その場合は、開発者側のプライバシーポリシーに問題がある(ユーザーに伝えているプライバシーポリシーの内容と相違するため)ため修正を行う必要があります。
特にアプリの説明文ではデータを取得すると記載されている場合でもプライバシーポリシー上でそういった表記が見られないケースもあり、今後改善が必要になってくると考えられます。
検証4:子供向けコンテンツのプライバシーポリシーの要素
子供の個人データを取得する場合は米国だとCOPPA(児童オンラインプライバシー保護法)によって親の同意が必要と決められています。
子供のデータを取得する場合は、プライバシーポリシー上の記載だけでなく親の同意を前提とした設計が求められる事もあり、137件のSkillに関しては子供むけのアプリにも関わらず明確にデータ取得に触れられていない点が懸念として考えられます。
検証5:プライバシーポリシーの長さの要素
プライバシーポリシーに対する明確な同意を設計する上で、プライバシーポリシーの文章の長さは一つの大きな課題として残っています。
58%のプライバシーポリシーは1500文字を越える文章で設計されており、プライバシーポリシーを読み上げるためには12分以上かかる計算です。
平均を算出すると、AmazonのSkillで約2,336文字、GoogleのActionで1,479文字となっています。現時点ではユーザーが明確に理解した上で同意するとは考えずらく、明確に理解せずに利用している懸念が考えられます。
スマートスピーカーのプライバシーポリシー問題から学べる事
今後スマートホームやスマートオフィスなどモノとインターネットが繋がるだけでなく、取得したユーザーの個人データを共有する場面も数多く出てくるのではないかと考えられます。
AmazonやGoogle、Appleなどはプラットフォーマーとして、第三者への個人データ提供を行いビジネス領域を拡大していくため、プラットフォームに乗る側、プラットフォームを新しく作る側の両方の視点からプライバシーポリシーの設計を考える必要があります。
両方の視点からプライバシーポリシーを設計する上で事前に気をつけておきたいポイントを両側の視点から抑えていきたいと思います。
プラットフォームに乗る場合
1、取得する個人データを最小限に
クレムゾン大学での調査から個人データの取得量が増える事によって、プライバシーポリシーを通じて明記していくべき内容が大幅に変わってくる事になります。
第三者は直接ユーザーからデータを預かるわけではないため、ユーザー視点でのプライバシーポリシーの設計とプラットフォーマーに対する設計を同時に達成する必要があります。
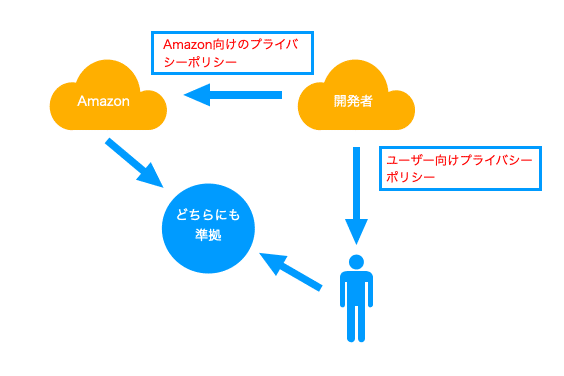
"どちらにも準拠" した選択を取る場合は過度に個人データを取得すると複雑になるため、できる限り取得データを減らしていく方が良いと考えられます。
2、プラットフォーマーのプライバシーポリシーを十分に理解して調整する必要性
今後プラットフォーマーは個人データ保護の文脈に合わせて、プライバシーポリシーの変更を頻繁に行っていく可能性があります。Youtubeなどは既に始めており、こういった流れはスマートスピーカー 等でも起きてくると考えられます。
その場合の対応策としてプラットフォーマーの対応をウォッチしておく必要があり、対応に合わせて個人データの取得などを検討していく必要があります。
プラットフォームを作る場合
1、第三者提供の際のプライバシーポリシーガバナンス設計に注意
Amazon SkillやGoogle Actionの例のように個人データを提供する第三者が適切にプライバシーポリシーを準拠、及び明確に設計し、運用しない可能性も考えられるため適切なガバナンスを設計して運用する必要があります。
プラットフォーム側としては、取得した個人データを悪用されるリスクなども考える必要もあり開発者の認証に関してもコストをかけていく必要があります。
また、プラットフォーマー自体のプライバシーポリシーも定期的に見直す必要があり、変更した際の開発者への通知、及びユーザーへの通知に関してもコミュニケーションを適切に考える必要があります。
2、ユーザーからのデータ要求への対応
ユーザーから個人データの要求があった際の対応に関して、明確な基準を持っておく必要があります。
特にデバイスを通じてどのようなデータが取得されているのかを内部でも明記しておく事に加えて、ユーザーに対しても積極的に開示していくことが求められます(アカウンタビリティの観点)。
このような透明性を担保した設計が求められるため、プラットフォーマーはSkillなどを提供する開発者を数だけで集めるのではなく、信頼できるパートナーとして限定して集めていく必要も出てくると考えられます。
そうなった場合は、これまでのビジネスモデルと変わってくるポイントもあるかと思うのでデータビジネスの再設計が必要になると思います。
3、デバイスを通じた同意取得の問題
これはスマートスピーカー に限った話ではないですが、"自動音声認識(ASR)技術を活用して録音データを文字列に変換し、自然言語理解(NLU)でデータを構造化" する際に、ユーザーから事前に構造化データを取得するということを明確に理解してもらえるのかがポイントになります。
ユーザー側では個人のプライベートデータを取得していると思っていない場合でも(気づくとスイッチが入っていた)同意を取るような設計が必要になります。
※例えば、データを取得始めた時はデバイスの色が変化するや、音声で通知されるなど
IoTとデータプライバシーの未来
今回はスマートスピーカー を題材に学んできましたが、これからモノとネットが繋がり、さらに横での連携が進むとデータの取り扱いに関する問題が発生してくるようになります。
特に個人データに関してはデータ保護の観点から取り扱いがより厳しくなっていくと考えられるので、リスクを事前に検討した上でビジネスモデルの設計を行っていく必要があります。
この辺りは、今後も事例が出てくると思うので引き続きご紹介できればと思います。
※一部法的な解釈を紹介していますが、個人の意見として書いているため法的なアドバイス、助言ではありません。
記事の内容やデータプライバシー×データビジネスに関するご質問はこちらまで!!
ブロックチェーン技術は世界中の人たちが注目している新しいビジネスのタネの一つです!気になったら気軽にメッセージください!