
【実践編】集計からダッシュボードの作成まで1本化!PythonとDashによるデータ可視化アプリ開発 〜実データの集計・関数化・モジュールの作成〜

はじめに
マーケティングリサーチプラットフォームを提供している株式会社マーケティングアプリケーションズです。
弊社では、キリンビール様から発売中の本麒麟がなぜヒットしているのか、その要因を探るべく、アンケートでデータ収集→Pythonで集計→Dashでダッシュボードの作成を行い、データを可視化するWebアプリ開発に挑戦しました。
そして、そのDashに関する内容を【基礎編】・【Tips編】・【実践編】の3つに分けてYouTubeチャンネルに投稿し、ノウハウを全て無料で公開しました。
今回の記事は、その3つの動画の中の【実践編】の紹介記事になります。
実践編
今回の実践編では、本麒麟のヒット分析を行うにあたってDashを用いてどのようにダッシュボードを作成したのか、Tips編の内容を組み合わせてご紹介しています。
↓解説動画はこちら。(画像クリックで動画をご視聴頂けます。)

(※なお、本記事は動画の内容を記事にしたものですが、今回の記事では2人のキャラクターによる会話形式でご紹介します。)

データの読み込みから開発までの工程
講師:基礎編では環境構築やサンプルを表示、続くTips編では色々なグラフを表示しました。実践編となる今回は、関数を作るなど、より実践的な内容になっていきます。
田中さん:集計や関数・モジュールなど難しい単語が出てきていますが、ついていけるように頑張ります!
講師:一緒に頑張っていきましょう!それでは早速はじめていきましょう。まず、今回作成しているアプリはこのような流れで作成しています。
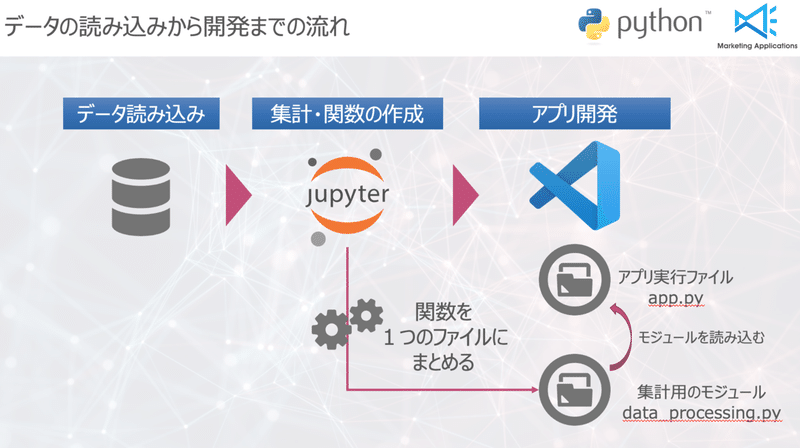
田中さん:前回までは、VSCodeだけ使っていましたが、今回からデータ分析でおなじみのJupyterNotebookも使うんですね。
講師:そうです。VSCode上で集計は行わず、まずはJupyterNotebookで集計を行います。集計を行ったコードは関数化して、1つのモジュールとして保存して、アプリを実行するapp.pyにインポートします。
田中さん:インポートをするということは、Pythonの外部ライブラリでお馴染みのPandasやNumpy、このシリーズで使ってきたDashのライブラリをインポートすることと同様のことをしているんですね。自分で作ったプログラムも他の外部ライブラリと同じようにインポート出来るんですね!
講師:そうなんです!このようにすることで、集計した値を取得してグラフの値に代入することが出来るようになるんです。そして、ここでは関数・モジュールという新しい言葉が出てきました。次の章ではこの2つの言葉を解説していきます。
関数とモジュールについて
講師:関数は、一つ一つの部品(CSVを用いて○○の値を使って集計するAという関数、△△の値を使って集計するBという関数)、モジュールは、関数(部品)を一つのファイルにまとめたものになります
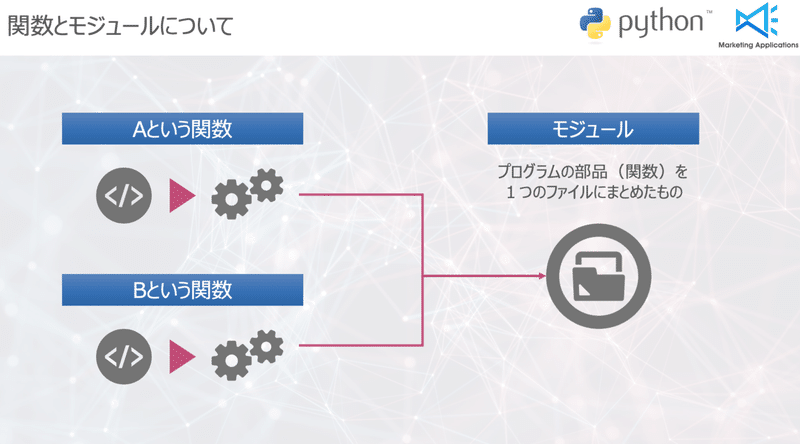
講師:関数を用いることは、いくつかの利点があります。
・チームで一緒に開発する人がどの部品でどのグラフを作成しているか分かる
・今回使用していた部品を次のプロジェクトで使い回すことができる
モジュールの利点としては、集めた部品を一つのモジュールという道具箱に入れておけば、いつでもその部品を取り出して使うことができるのです。
そして、今回のようにJupyter Notebookで集計だけしていたものをWebアプリ上に組み込んで使うこともできるようになります。
次の章では、この関数・モジュールを使用してグラフの可視化までどのように作成していくか、バブルチャートの作成を例に解説していきます。
バブルチャートを作成した時の工程
講師:こちらのバブルチャートを作成した時の工程を例にして進めていきます。コードの詳しい解説は、動画内で行っておりますので、そちらも合わせてチェックしてみて下さい。
Jupyter Notebookを使用して集計を行う
講師:Jupyter Notebookを起動して、セルごとにコードを書き、集計を行います。



田中さん:バブルチャートを作るために、【データを読み込む】・【X軸】・【Y軸】・【バブルサイズ】と、それぞれの関数を作っているんですね!そして、それを最後の関数でまとめているんですね。
知っておきたい関数化する時のポイント
講師:上記のコードは、工夫すれば↓このように1つのセル内に完結させることが出来ます。
田中さん:…一気に見るのがしんどくなってしまうコードになってしまいました…。どこの処理がどう関わっているのかも分かりづらいです。
講師:田中さんがおっしゃる通り、このプログラムには悪い点がいくつかあります。1つ1つ挙げていきましょう。
①可読性が悪い
1つ1つの部品が全部まとめられていて、どのような処理になっているのか分かりづらくなっています。
②セル内のコードが膨張していく
追加で新しく集計が必要になった場合にコードを継ぎ足していく必要がありますが、その際にコードはさらに膨張して、さらに可読性が悪くなるでしょう。
③使い回しがしにくい
このコードの1部分だけを使用して他のデータも集計をしたい場合に、どこからどこを切り分けて部品として使用すれば良いのか分かりにくいため、使い回しがしづらいコードになっています。
最後に、戻り値を見てみると、多次元リストとして返ってきていることが分かります。X軸の値を取りたい時に、インデックス番号で呼ばないといけません。

このコードの悪いところとして、
・他のチームメンバーが見ると、何の値を取得しているかわからない。
・時間が経った時にコードを見返すと「何を返す値だっけ?」と分からなくなり、本当にX軸を取得するのか不安になる。
などのことが挙げられます。
多次元リストは便利ですが、このような使い方はやめておくのが良いと思います。
関数にしたプログラムをモジュール「data_processing.py」に保存する
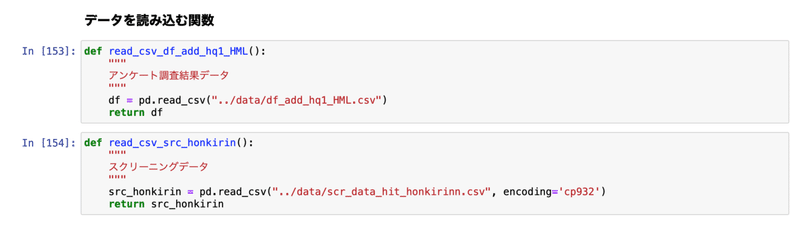
講師:それでは次に、出来た関数をまとめるモジュールを作っていきましょう。Jupyter Notebookで作成した関数をモジュール「data_processing.py」にコピペします。
Python:data_processing.py
# ============================================
# データを読み込む関数
# ============================================
def read_csv_df_add_hq1_HML():
"""
アンケート調査結果データ読み込み
"""
result = pd.read_csv("data/df_add_hq1_HML.csv")
return result
def read_csv_src_honkirin():
"""
スクリーニングデータ読み込み
"""
src_honkirin = pd.read_csv(
"data/scr_data_hit_honkirinn.csv", encoding='cp932')
return src_honkirin
# X軸の作成
# ============================================
def x_axis_list():
"""
集計方法:ピポットテーブル
行ラベル:hq1(性年代)
値:df_coefficient(飲用頻度の係数)
hq1(性年代)ごとのdf_coefficient(飲用頻度の係数)の平均値を算出
"""
df = read_csv_df_add_hq1_HML()
hq1_df = pd.pivot_table(
df, index="hq1", values="df_coefficient", aggfunc="mean")
result = [round(i, 1) for i in hq1_df['df_coefficient']]
return result
# Y軸の作成
# ============================================
def y_axis_list():
"""
集計方法:ピポットテーブル
行ラベル:hq1(性年代)
値:da_coefficient(飲用量の係数)
hq1(性年代)ごとのda_coefficient(飲用量の係数)の平均値を算出
"""
df = read_csv_df_add_hq1_HML()
hq1_da = pd.pivot_table(
df, index="hq1", values="da_coefficient", aggfunc="mean")
result = [round(i, 1) for i in hq1_da['da_coefficient']]
return result
# バブルサイズの作成
# ============================================
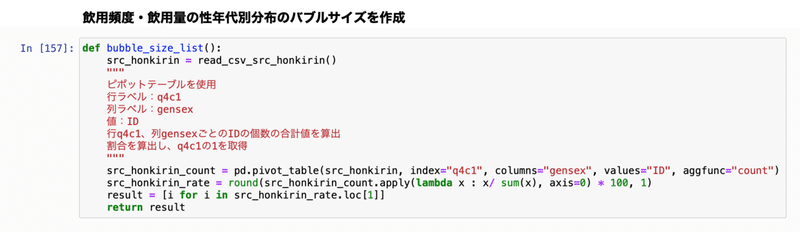
def bubble_size_list():
src_honkirin = read_csv_src_honkirin()
"""
集計方法:ピポットテーブル
行ラベル:q4c1
列ラベル:gensex
値:ID
行q4c1、列gensexごとの個数の合計値を算出
"""
src_honkirin_count = pd.pivot_table(
src_honkirin, index="q4c1", columns="gensex", values="ID", aggfunc="count")
src_honkirin_rate = round(src_honkirin_count.apply(
lambda x: x / sum(x), axis=0) * 100, 1)
result = [i for i in src_honkirin_rate.loc[1]]
return result
# ラベル用のテキストを作成
# ============================================
def text_list():
bubble_size = bubble_size_list()
gender_age = ['20代男性', '30代男性', '40代男性', '50代男性', '60代男性',
'20代女性', '30代女性', '40代女性', '50代女性', '60代女性', ]
result = []
for (gender_age, rate) in zip(gender_age, bubble_size):
i = '<b>' + str(gender_age) + '<br>' + str(rate) + '%' + '<b>'
result.append(i)
return result
# 飲用頻度・飲用量の性年代別分布作成用に関数をまとめる
# ============================================
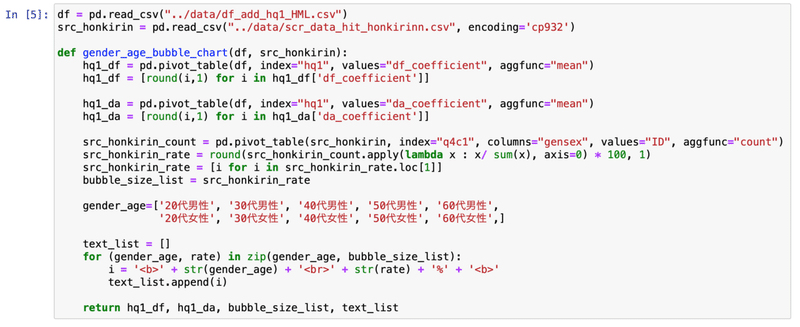
def gender_age_bubble_chart():
x_axis = x_axis_list()
y_axis = y_axis_list()
bubble_size = bubble_size_list()
text = text_list()
result = {'x_axis_list': x_axis,
'y_axis_list': y_axis,
'bubble_size_list': bubble_size,
'text_list': text}
return result
講師:続いて、app.pyにモジュール「data_processing.py」をインポートします。
Python:app.py
import collections
import pathlib
import random
import re
import dash
import dash_core_components as dcc
import dash_html_components as html
import numpy as np
import pandas as pd
import plotly
import plotly.express as px
import plotly.figure_factory as ff
import plotly.graph_objs as go
from dateutil import relativedelta
from plotly.subplots import make_subplots
# 自作モジュールをインポート
import data_processing as dpモジュールから関数を呼び出して値を取得する
講師:モジュールから関数を呼び出します。ここではバブルチャートのグラフを作成するために必要な「gender_age_bubble_chart」という関数を呼び出しました。
この関数を実行した時に返ってくる値を戻り値と呼びます。
戻り値は、X軸用のリスト・Y軸用のリスト・バブルサイズのリスト・ラベル用のリストを入れた辞書型のデータになっています。
下記のコードがそうですね
Python:data_processing.py
result = {'x_axis_list': x_axis,
'y_axis_list': y_axis,
'bubble_size_list': bubble_size,
'text_list': text}講師:x_axis_listのキーを呼べばx_axisが、y_axis_listのキーを呼べばy_axisが返ってきます。
田中さん:なるほど。このキーを呼んで、X軸の値やY軸の値を引っ張ってくるんですね。
app.py[準備]内の作業を進める
講師:バブルチャートを表示させるためのソースコードは以下の通りです。
準備として、データとレイアウトをそれぞれ作成していきます。
田中さん:前回のTips編で見たバブルチャートにコードが似ていますね。違う部分は…X軸やY軸・バブルサイズ・テキストが変数になっていますね!
講師:Tips編では、X軸・Y軸・バブルサイズ・テキストをそのまま手打ちしていましたが、ここでは集計した値を代入しています。
Python:app.py
# ============================================
# 飲用頻度・飲用量の性年代別分布
# ============================================
# 飲用頻度・飲用量の性年代別分布 ▶︎
# データの入力、データの表示を制御する場所
# ============================================
x_axis_list = dp.gender_age_bubble_chart()['x_axis_list']
y_axis_list = dp.gender_age_bubble_chart()['y_axis_list']
bubble_size_list = dp.gender_age_bubble_chart()['bubble_size_list']
text_list = dp.gender_age_bubble_chart()['text_list']
gender_and_age_distribution = go.Figure()
gender_and_age_distribution_data = go.Scatter(
x=x_axis_list, y=y_axis_list,
mode='markers+text',
text=text_list,
textposition=['top center', 'middle center', 'top center', 'middle center', 'middle center',
'middle center', 'middle center', 'middle center', 'middle center', 'bottom center', ],
marker=dict(
color=['#3371a0', '#3371a0', '#3371a0', '#3371a0', '#3371a0',
'#b24644', '#b24644', '#b24644', '#b24644', '#b24644'],
opacity=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
# 元のサイズは、16.5, 46.0, 37.5 *3
size=[bubble_size_list[0], bubble_size_list[1], bubble_size_list[2], bubble_size_list[3], bubble_size_list[4], bubble_size_list[5],
bubble_size_list[6], bubble_size_list[7], bubble_size_list[8], bubble_size_list[9]],
)
)
# 飲用頻度・飲用量の性年代別分布 ▶︎
# レイアウトを決める場所
# ============================================
layout = go.Layout(
title=dict(
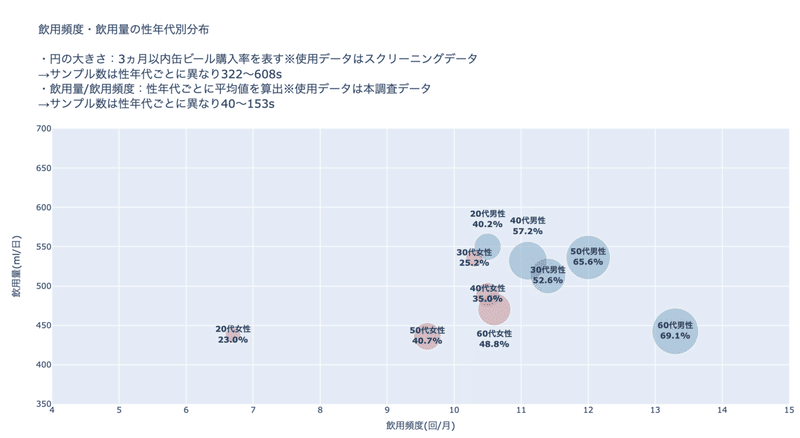
text='飲用頻度・飲用量の性年代別分布<br><br>・円の大きさ:3ヵ月以内缶ビール購入率を表す※使用データはスクリーニングデータ<br>'
'→サンプル数は性年代ごとに異なり322~608s<br>'
'・飲用量/飲用頻度:性年代ごとに平均値を算出※使用データは本調査データ<br>'
'→サンプル数は性年代ごとに異なり40~153s',
y=0.91,
yanchor="top"
),
height=650,
width=1185,
xaxis=dict(
title_text="飲用頻度(回/月)",
range=[4, 15],
dtick=1
),
yaxis=dict(
title_text="飲用量(ml/日)",
range=[350, 700]
),
margin=dict(t=200, r=0, b=0)
)
# 飲用頻度・飲用量の性年代別分布 ▶︎
# データとレイアウトをまとめ場所
# ============================================
gender_and_age_distribution = go.Figure(
data=gender_and_age_distribution_data, layout=layout)app.py[表示]内の作業を進める
講師:表示で、app.layout内にdataとlayoutが入ったgender_age_bubble_chartを代入します。無事に作成が完了したらバブルチャートが表示されます。
Python:app.py
html.Div(
[
html.Div(
[
html.Div(
[
html.Div(
[
dcc.Graph(
id="",
figure=gender_age_bubble_chart
),
], style={'background-color': '#ffffff', 'text-align': 'center', 'border-radius': '5px 0px 0px 5px', 'height': '700px',
'margin': '10px 0px 10px 10px', 'padding': '15px', 'position': 'relative', 'box-shadow': '4px 4px 4px lightgrey',
}
),
],
id="",
className="row container-display",
),
],
id="",
className="",
),
],
className="row flex-display",
),講師:以上がモジュールを使用した、集計からダッシュボードでグラフを可視化するところまでの方法です。
田中さん:先生ありがとうございます!コードを見て勉強したり、自分でもJupyterNotebookを使用して。集計から関数化・アプリの表示までをやってみたいと思います!
講師:田中さんお疲れ様でした!今回の技法は1日で全て身につくものではありませんので、ぜひ動画を見ながら、そしてご自身でもコードを実装しながら、理解を深めていって下さいね。
おわりに
本シリーズを通して、Dashでダッシュボードを表示させるデータ可視化アプリを作成するまでの基本的なことについて、ある程度押さえられたのではないでしょうか。ぜひ本記事と動画を見ながら、実際に触れてみて頂けたら嬉しいです。
この記事が気に入ったらサポートをしてみませんか?