
データ基盤にSnowflakeを導入して分析を爆速にした話

初めて技術記事を書きます。noteでデータエンジニアをやっています、久保田です。
noteにはデータ基盤が存在しており、記事の閲覧やユーザーの行動など、さまざまなデータをログとして保存しています。
そんなデータ基盤に2022年4月、Snowflakeを導入しました。
Snowflake:データウェアハウジングやデータレイク、データエンジニアリング、データサイエンス、データアプリケーションの開発などを行うことができるフルマネージド型のサービス
今回はなぜSnowflakeを導入したのか、なぜSnowflakeだったのか、導入した当時の技術的な話などを書いていきたいと思います。
Snowflake導入前の課題とアーキテクチャー
2022年4月以前、noteのデータ基盤はある課題を抱えていました。それは
クエリーの結果が返ってくるのがとにかく遅い
ことです。
ここでSnowflake導入前のデータ基盤を紹介します。
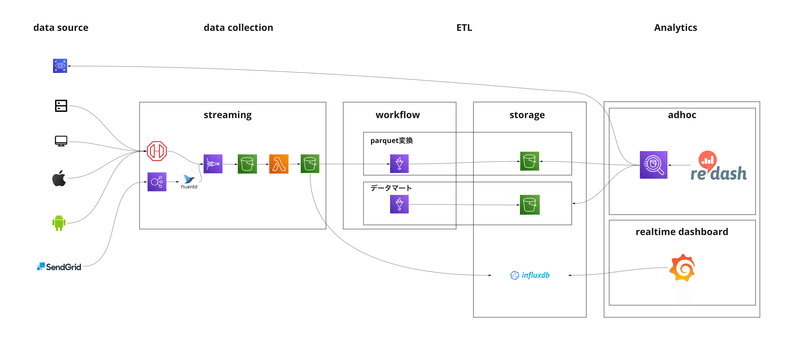
Athenaを利用し、S3においてあるファイルに対しクエリーをかけていました。
上図のアーキテクチャのときは処理速度を向上させるために、日付・時間でパーティションを切ったり、parquet変換してファイルをまとめたりと、ある程度は効率的にデータが取得できるようにしていました。しかし、ログのファイル数が増えたときに、長期間にわたる集計を行うと、時間がかかってしまったり、タイムアウトが発生していました。
ここで時間がかかると、集計や分析作業時に、
ストレスがたまる
分析作業中に他の作業をしてしまったり、思ったようにデータが取れないので、分析作業をうまく進められない
という問題が起きます。
現在noteでは、残念ながらデータ活用は必須のものではなく、ビジネスに付加価値を与えるものです。
上記のように作業自体にストレスが溜まる状況だと、データ活用はなかなか進まず、データへの興味関心が薄れいき、データ基盤は使われなくなります。
そうすると、社員はデータから離れ、僕らの仕事は無くなってしまいます。
データが会社の意思決定に必須なものとなるためには、このデータ活用の課
題を解決することが必要だと考えました。
Snowflake導入後のアーキテクチャーと大幅な速度改善
速度改善のため、DWHの比較検討を進めた結果、Snowflakeの導入に至りました。
Snowflake導入後の現在のアーキテクチャーがこちらです。
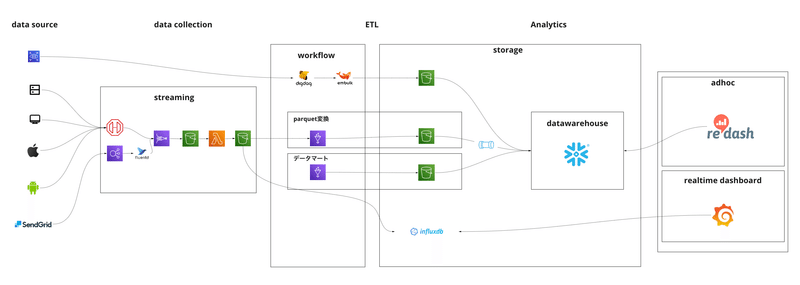
SnowflakeにS3からデータを入れ、RedashからSnowflakeにクエリーをかけています。
(移行途中なので、もちろんまだAthenaのワークロードは動いてはいます。)
上記のアーキテクチャーにした結果、あるダッシュボードではデータの取得・可視化まで数十分かかっていた処理が30秒になったり、
今までできなかったデータ取得開始時から全期間のデータを取得できるようになったりしました。
Snowflakeを組み込んだことで、集計・分析時のストレスが軽減され、かつ直感的に分析作業が可能になり、データ活用の土台が整ったかと思います。
なぜSnowflakeだったのか
当時、BigQuery、Redshiftと比較をし、結果的にSnowflakeを選定しました。
BigQueryとRedshiftはどちらもそれぞれいい点がありましたが、Snowflakeの導入を決めたのは、特に以下のような点が優れていたからです。
コンピュートリソースであるwarehouseの分離により、ワークロードごとにリソースの強い・弱いの割り当てが可能
S3においてあるファイルの取り扱いが楽
ストレージの圧縮率が非常に高い
めっちゃ早い
特に、導入時はS3においてあるファイルの取り扱いが楽という点は特に助かりました。
CREATE STORAGE INTEGRATION production_storage_integration
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'AWSアカウントに設定したROLEのARN'
STORAGE_ALLOWED_LOCATIONS = (
'許可するS3バケットの一覧'
);
CREATE OR REPLACE STAGE PRODUCTION_STAGE_PARQUET
storage_integration = production_storage_integration
url = 'S3バケット'
file_format = (type = PARQUET);
Snowflakeでは、ストレージインテグレーションとステージというデータソースを定義しておける機能があり、この機能を使うと、データのインポートがさらに楽になります。
COPY INTO LOG_TABLE FROM (
SELECT
$1:column1::varchar,
$1:column2::integer,
$1:column3::datetime,
substr(split_part(metadata$filename, '/', 2), 6),
substr(split_part(metadata$filename, '/', 3), 7),
substr(split_part(metadata$filename, '/', 4), 5),
substr(split_part(metadata$filename, '/', 5), 6)
from @PRODUCTION_STAGE_PARQUET/log_table/
)
FILE_FORMAT = (TYPE = PARQUET)
ON_ERROR = 'continue';
どこのクラウドで、どのバケットで、どんなフォーマットなのかを定義することで、copyが楽になります。
このようにするだけで、データのcopyが非常に簡単にできます。
数億のレコードが数分で取り込めました。
copy時の注意点としては、parquetの取り込み時は、$1:column1::varcharのように元ファイルのカラム名を正しく指定してあげる必要があります。
この設定をミスると、カラムにnullが入り、copyした時のリソースが完全に無駄になります。
また、Athenaからの移行に際し、ファイル内にはなかった、AthenaのパーティションのカラムもSnowflakeで再現したかったので、
substr(split_part(metadata$filename, '/', 2), 6)
のようにしてファイルパスから値を取り出してcopy時に追加しています。
Snowflakeを導入した感想
このように、Snowflakeは、クエリーの速度を爆速にするだけでなく、データ分析のサイクルを早くし利用者をストレスから解放してくれます。
エンジニア視点で見ると、導入までのコストが非常に低く、簡単に社内のデータ活用ユーザーに対していい体験を届けることができたと思います。
現代のデータ活用は、直感的でいつでもデータが取れる環境が求められています。なので、データ分析が遅い・なかなかデータ活用が進まないという場合は、Snowflakeを導入してみることをおすすめします。
ここで告知になりますが、DATA CLOUD WORLD TOUR JAPAN
にカスタマースピーカーとして登壇します。
この記事でも触れている内容についてより詳細にお話をさせていただくので、ぜひこちらもよろしくお願いします。
この記事が気に入ったらサポートをしてみませんか?