
システム障害に強いチームにするため、障害対応訓練を継続している話

こんにちは。シニアエンジニアの佐々木です。
育休が明けて半年ほど経ち、子供も生後8ヶ月になりました。最近はハイハイで家中を駆け巡っており、いろんな意味で目が離せません。
さて、今日はシステム障害に強いチームにするため社内で実施している障害対応訓練について紹介したいと思います。
訓練をする背景
訓練の内容を紹介する前に、訓練を実施する背景についてまずは触れておきたいと思います。
Web開発をしてるエンジニアにとって、システム障害は必ず向き合わないといけないものの一つです。テストを充実させたり、SPOF(単一障害点)を取り除いたり、どれだけ品質高く作り込んでいたとしても、障害は急にやってきます。
しかも想定していないものが来ることがほとんどです。どんな障害が発生するかわかっていれば当然先手を打つこともできますが、それは難しい話です。
そのため、実際に障害が発生した場合は経験豊富なエンジニアが対応することが多くなりがちです。この状況が続くと、以下のような課題が見えてきます。
経験豊富なエンジニアに負担が偏る
特定のエンジニアがいないと対処できない
上記から、復旧に遅れが出るなどサービスの信頼性に関わる可能性がある
想定していないものが来るのはどうしようもありませんが、見える課題には対処することが可能です。
負担の偏りを減らし、特定のエンジニアが不在でもチームとして安定的に対応できる体制を改めて作っていくにはどうしたらよいか。
クラシコムでは、最初のステップとしてシステム障害の対応訓練を複数回行い、今後も継続して実施・改善していくことに決めました。
訓練の内容
運用ルール
訓練を実施するにあたり、訓練内容をどういったルールで運用するかがまずは大事になってきます。クラシコムでは全員フルリモート前提で、下記のようなルールで実施しています。
障害対応のシミュレーションに留める
AWS Fault Injection Simulatorを使用するなどカオスエンジニアリングまではしない
シミュレーションは「障害発生 → 集合 → 対応するとしたらこうする」というところを実際にやってみる
役割分担、役割ごとの作業もやれるところまでやる
シミュレーションのお題は担当者が考え、抜き打ちで実施
部長が休み、経験豊富なエンジニアが不在など、一部リアルな状態での実施も意図的に行う
基本はこのルールで、実際の訓練時間はおおよそ1時間ほど、一ヶ月に1度くらいの頻度で実施しています。一回一回の負担は少なく、まずは回数をこなしていくことを目的としています。なお、初期は集合までやってみることにしていましたが余裕ができたのか気づいたら集合より先のことまでやるようになっていました。
具体的な実施例
具体的な実施例として、「メールが届かなくなってしまった」場合の対応内容を簡単に時系列で列挙したいと思います。
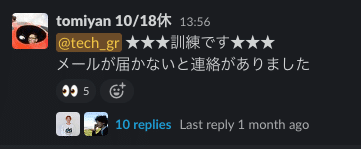
メールが届かないという一報がSlackでチームメンション宛で届く
一報を見て障害と判断したエンジニアがSlackで集合をかける
Aroundに集合(AroundはオンラインMTGツール)
集合できたメンバーで状況を確認。AWSがダウンしSESで障害が起きメールが届かなくなった、長期的な障害になりそうという仮定であることをお題担当者から共有される
役割分担を実施
対応を検討、実際に対応可能そうなのかを確認
確認中に復旧報が届く
関係各所に復旧を連絡したことにして終了
流れとしては以上ですが、訓練時に重要視していることをいくつかピックアップします。
1つ目が集合です。
まずは集まるというだけのことなのですが、これが遅れると被害が広がる可能性があるのでとても重要です。実際に障害になっているかどうかの確認を待たず、怪しければまずは声掛けして複数人で確認しよう、というルールにしています。

次が役割分担です。基本的に以下の役割を分担するようにしています。
インシデントコマンダー
対応の意思決定を行う人で他役割とのハブになる
対応が長期に渡る場合の休憩判断も行う
作業者
影響範囲調査・修正対応で実際に手を動かす人
手分けできる場合は複数人アサイン
事業担当
お客様へのアナウンス、他部署への進捗共有などを担当
書記担当
Google Docsにあるテンプレートを使い障害内容を記録する
センシティブな内容を記載することもあり権限管理しやすいなどの理由からGoogle Docsを採用している
部長
インシデントコマンダーからの情報共有を元にリスクを含んだ対応方針の合意を行う人
中でも、対応の意思決定を行うインシデントコマンダーは経験・スキルのあるメンバーが自然とやりがちなので、訓練のタイミングでは経験の少ないメンバーをアサインして経験を積んでもらいます。
また、各々の役割は訓練でもSlackにポストするなりGoogle Docsに記録するなりを実際に実行します。
実施したあとの振り返り
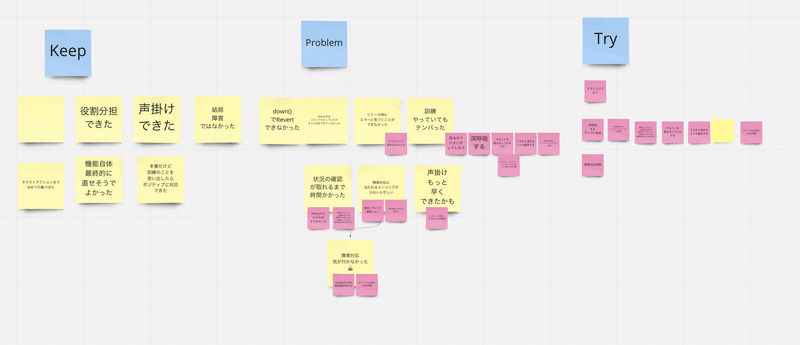
実施したあとは振り返りが大事です。振り返りでよく出る改善点が以下です。
全体の対応フロー
集合の声掛け
各役割がやるべきこと
書記テンプレート
振り返ってみて「次はこれをちゃんとやろう!」となっても、実際に突然障害が起きるとできないことも多いです。
例えば、集合の声掛けなどは訓練だとわかっていればしやすいのですが、本当に起きた場合は「これは障害なのか…?みんなに声かけるべき…?」と判断に迷い躊躇することもあると思います。
振り返りをした結果、「そこで一人で判断に迷うくらいなら障害になっているかの確認を待たず怪しければ声掛けしましょう」とチームで認識を揃えました。
このように都度見直し、少しずつ仕組みの手直しを行いチーム全体で練度を上げられるよう取り組んでいます。
また、実際にシミュレーションしてやっていると「このシステムの仕様見直したほうが良いのでは?」ということもあり、システムの改善ポイントも副次的に見つかることがあります。個人的に、お題内容によってプレモーテムに近いときがあるのかもと思っています。
訓練は活かされているのか
クラシコムが運営している北欧、暮らしの道具店は、実際には安定している方だと思いますし安定させるよう取り組みを行っています。
サイトトップを外形監視しているが、深夜・早朝のメンテナンス作業を除けば2022年は一度もダウンしていない
一部機能に障害・不具合が発生するなどは少なからずあるが局所的
試験的にSLI/SLO運用中
サーバー監視にMackerel、SLI/SLO計測にshimesabaを使用
毎週SRE定例で確認・振り返りを実施
幸い直近では大きな障害が発生していない状況ですが、局所的な障害・不具合は稀にあるので、その時に訓練での経験・振り返りが活かされています。
最後に
システム障害は起きないにこしたことはありませんが、めまぐるしく変化し続ける外部環境・内部環境から発生をゼロにすることはできません。
クラシコムのエンジニア組織はさほど規模は大きくなく、課題も山積みです。しかしこれからも様々な変化を受け入れ、着実に進んでいければと考えています。
チームでシステムを安定運用し育てていくことに興味を持っている方、いらっしゃったらぜひ一度お話できればと思います。
/assets/images/10049949/original/8229793c-89fb-4c19-a227-d33db59c26e6?1659578854)