
TotT: E2Eテストはほどほどに

こんにちは、kubopです。
Googleにはトイレテスト(TotT)という文化があるようで、テストに関するTipsをトイレに貼り出し、テストに関する知識を全社で共有しているらしいです。
昨今はリモート勤務が広まり、TotTの実施は難しく、SlackやBotを用いてもなかなか浸透するかどうか…
そこで、noteに書きつつ自分が勉強するために、少しずつ読んで内容や、所感を書いてみようと思います。
※ 翻訳・解釈の間違いなどあるかもしれません。
その場合はこっそり教えてください。
もっとテストを書いてほしいのです。そう、あなたです。テストは、コードをリファクタリングするときや他の開発者が機能を追加するときに、 あなたを守るセーフティネットであることはもうおわかりでしょう。また、テストがコードの設計に役立つこともご存知でしょう。
…
私たちは、この秘密兵器(this secret weapon)を世界中の人々と共有し、私たちのテストへの情熱を広めるとともに、あなた自身やあなたの会社の他の人たちに、この重要なトリックやテクニックを楽しく簡単に学んでもらうことにしました。
このブログで定期的にエピソードを紹介し、PDFを提供しますので、プリントアウトしてご自分のバスルーム、廊下、キッチン、月面基地、秘密の地下要塞、億万長者の創業者のプリウスなど、どこにでも貼り付けてください。
Just Say No to More End-to-End Tests
テストの世界では、エンドツーエンドテストを中心に構築されたテスト戦略が、しばしば失敗に終わることがあります。
テスターは、ユニットテスト、統合テスト、E2Eテストなど、多くの種類の自動テストを書くことに時間を費やします。
その際に、製品やサービスを全体としてユーザーのシナリオをシミュレートするE2Eテストを重点的に作成します。
理論上のE2Eテスト
E2Eのテストに依存するのはあまり良い考えでは無いですが、理論的には理にかなっています。
"Google's list of ten things we know to be true(Googleの、私たちが知っている真実の10項目)"の1つには
"ユーザーに焦点を当てれば、他の全ては後からついてくる。"という項目があります。
従って、ユーザーに焦点を当てたE2Eテストは、素晴らしいアイデアのように聞こえます。さらに、この戦略は多くの人にとって納得感のあるアイデアとして受け入れられます。
開発者は、テストの大部分を他人に任せることができる点で
マネージャーは、実際のシナリオをシミュレートし、失敗した場合にユーザーに与える影響を簡単に判定できる点で
テスターは、バグを見逃したり、実際の検証していないテストを心配しなくても良くなる点で
E2Eテストを好みます。
E2Eテストの実践・例
このテスト戦略は理論的にとても良いものだとするならば、
実際にはどこで失敗したと言えるのでしょうか?
以下のチームは良いテストインフラを所有していると仮定しましょう。
毎晩サービスの最新バージョンがビルドされ、
テスト環境にデプロイされ、全てのE2Eテストはこのテスト環境で実行され
さらにテスト結果をまとめたレポートがチーム内で共有されます。
次のリリースに向けて新機能を実装するために、あと1日で少なくとも90%のE2Eテストをパスしなければならない状況を想像してみてください。
以下は、リリースまでの残り日数(マイナス値はオーバー日数)とE2Eテストのその日の結果、Pass率を示したものです。
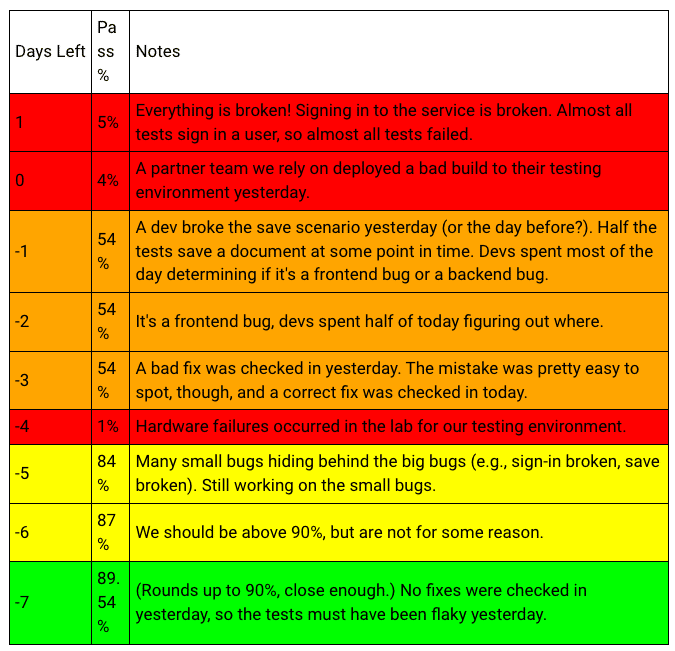
これらは、多くの問題を抱えながらも最終的には不具合を発見することができ、ユーザーに届く前に修正することができました。
しかし、マイルストーンを1週間遅れさせ、多くの時間外労働を要しました。
E2Eテストで失敗してしまったテストの根本原因を探すのは大変で、時間がかかります。
さらに、多くの些細なバグが大きなバグで隠されていて、しかもE2Eのテストが不安定になり、開発者は修正がうまくいったかどうか翌日まで待たざるを得ませんでした…。
E2Eの問題点は以下の通りです。
E2Eテストの失敗は根本原因を探すのが難しい。
E2EテストはときにFlakeyになることがある。
高速なフィードバックループを作れない。
これらの問題がE2Eテストにあるとわかりました。
では、テストへの正しいアプローチとはなんでしょうか?
テストの真の価値
一般的にテスターの仕事はテストが失敗した時点で終了です。
バグが報告され、そのバグを修正するのは開発者の仕事です。
しかし、E2Eはその境目が曖昧になり、どの部分の戦略が破綻しているのか特定することが難しい。(ここはかなり解釈違いがあるかもですが)
テストが失敗しても、ユーザーには直接の利益はありません。
製品が機能すれば、テストが機能すると言おうがしまいが、それは機能します。
製品が壊れていれば、テストが壊れていると言おうが言うまいが、それは壊れているのです。
テストに失敗してもユーザーのためにならないのであれば、何がユーザーのためになるのでしょうか?
bugfixは、直接的にユーザーに利益をもたらす。
ユーザーは意図しない動作、つまりバグがなくなって初めて満足します。
当然ですが、バグを修正するにはそのバグの存在を知らなければならず、
さらにバグの存在を知るにはそのバグを捕捉するテストが必要です。
テスト -> バグ発覚 -> バグ修正

このステップの中で最後のバグ修正でしか、価値を提供出来ません。
このように、どのようなテスト戦略で合っても大切なのは「開発者がどのようにバグを修正・予防出来るか」です。
正しいフィードバックループの構築
テストは、製品が動作しているかどうかを開発者に知らせるフィードバックループを作ります。
理想的なフィードバックループは以下の特性を備えています。
高速である。
信頼性が高い。
Flakyなテストは無視されがち。
失敗を切り分けることができる。
バグを修正するために、バグの原因となっている特定のコードを即座に知らせることができる。
小さく考え、大きく考えない
ユニットテストを作成する
ユニットテストは製品の小さな断片を取り出し、その断片を単独でテストします。
このテストは理想的なフィードバックループを作り出すことができます。
ユニットテストは高速で、信頼性が高く、失敗を分離します。
また、hermetic unit testは、Flakyなテストを完全に取り除くことができます。
hermetic unit test
Googleの新人が研修で行うストップウォッチのテスト
E2Eテスト VS ユニットテスト
E2Eテストでは、まず製品全体がビルドされ、次にデプロイされ、最後にすべてのE2Eテストが実行されるのを待たなければなりません。
E2Eテストは実際のユーザーシナリオをよりよくシミュレートしますが、この利点はE2Eフィードバックループの遅さで打ち消されてしまいます。
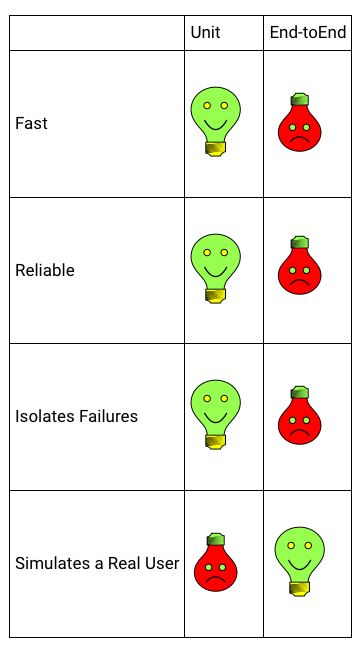
統合テスト
ユニットテストには、単体でうまく動作しても、それらがうまく連動するかどうかわからないという大きな欠点があります。
しかし、それでも必ずしもE2Eのテストが必要なわけではありません。
そのような場合は、統合テストを使用します。統合テストでは、小さなユニット群、多くは2つのユニットを取り上げ、それらの動作を全体としてテストし、それらが首尾よく一緒に動作することを検証します。
E2Eテスト : 統合テスト : ユニットテスト = 10% : 20% : 70%
といった配分でテストを構築する必要があります。
(これは以下を参照したほうがはやいため、割愛)
コメント追記:
"正確な組み合わせはチームによって異なるが、一般的にはピラミッド型を保つべきである。"ということを強調するべきです。
テスト自動化エンジニアの典型的な道筋は、次のようなものです。
1) できるだけ実際のユーザーの体験に近い形ですべてを行う。
2) ああ、このテストは遅すぎるし不安定だ。
3) ユニットテストに移行しよう。
4) ああ、ユニットテストは良いしグリーンだが、ここで重要なバグを見逃している。なぜなら、統合テストはあまりにも一般的な言葉であり、プロジェクトやチームが違えばもちろん、一つのプロジェクト内でも規模や価値が異なる可能性があるからです。
また、E2Eのテストは、ある程度ユニットテストとみなされるようなAPIテストの上に成り立っていることもある。ですから、割合について話すときは、それも考慮に入れる必要があります。
このようなことを踏まえて、私が言いたいのは、ピラミッドは理にかなっているが、70/20/10などにはあまりこだわらないことです。自分の製品、その特殊性、その課題という観点で考え、それに基づいて戦略や戦術を構築してください。
単体テストのFIRSTの特性について言及すべきです。FIRSTはなるべく全てのテストに適用すべきですが、範囲が大きくなればなるほど難しくなります。
テストやあらゆる種類の監視(アプリレベルの監視、ホスト、ユーザー、kpi)は、ソフトウェアの免疫システムの一部であると私は考えています。
私は70/20/10のアプローチに賛成ですが、ピラミッドの上にもう一つモニタリングのピラミッドを追加したいと思います。
特にCD(継続的デプロイメント)では、MTBF(平均故障間隔)よりもMTTR(平均復旧時間)の方がはるかに重要です。
私は、少なくともCDのシナリオでは、テストとモニタリングの投資時間は半々だと考えています。
ちなみに、夜間にテスト(どんなテストでも)が実行されるのを待たなければならないのは、CDを含め、多くの場合、とにかく意味をなさない。
エンドツーエンドテストとユニットテストの両方の利点を無視するのは間違いだ とはいえ、この記事はユニットテストのより困難な問題のいくつかを無視している。
特に、リファクタリングによって多くのテストが破壊され、リファクタリングされたコードではなく、テストが間違っている場合、リファクタリングの障害になります。
さらに、テストを完了させるためにかなりの量の状態が必要な場合、 ユニットテストでは結果を得られない可能性があります。
エンドツーエンドのテストであれば、リファクタリングしても壊れない可能性が高いです。もしend to endのテストに失敗があれば、もちろん分離する必要があり、その時に(より小さく焦点を絞った)ユニットテストが非常に役に立ちます。
Steve Freemanの "Growing Object-Oriented Software, Guided by Tests "を読んでいるところです。著者はエンドツーエンドテストについて非常に興味深い主張をしています。
「エンドツーエンドテストを実行することは、システムの外部品質について教えてくれるし、それを書くことは、私たち(チーム全体)がどれだけドメインを理解しているかについて教えてくれる。ユニットテストを書くことで、コードの品質について多くのフィードバックが得られます。また、ユニットテストを実行することで、クラスを壊していないことがわかりますが、やはりユニットテストは、システム全体が機能するという確信を十分に与えてくれません。
つまり、エンドツーエンドのテストは、私たちにフィードバックを与え、私たちが正しい方向に進んでいるかどうかを教えてくれるものだと私は理解しています。あなたの投稿を読んだ後、エンドツーエンドテストは時間の無駄だと感じました。開発の初期段階では重要な役割を果たすと思いませんか?
タイトルが誤解を招くような気がします。タイトルには反対ですが、記事には完全に同意します
E2Eテストは重要だが、それだけに頼ってはいけない。
E2Eテストは品質保証に適しており、ユニットテストと統合テストは開発者の助けになるものです。
多くの投稿者が、テストに設計をドライブさせることの重要性を無視しているように思います。
コードをどのようにテストするかを考えることは、クラスやサービスにおいて優れた抽象化を設計することを促し、ユニットレベルやインテグレーションレベルでビジネスプロセスをテストすることを可能にするはずです。
テストが機能やプロセスに密接に関連している場合、テストは適切かつ最新に保たれる可能性が高くなります。
Cucumber の E2E テストを大量に (1000個以上) 保有しているチームで働いていたとき、エンジニアがテストをメンテナンスしていても、そのテストが本当に適切なのか、単にレガシーのままなのか、よくわからない状況に陥ってしまいました。
E2E のため、特定のコードベースやライブラリ、サービスに対するテストの所有権を定義することが難しく、結局はメンテナンスの悪い「共通の」コードとなり、誰もそれを削除する権利を持っていないと感じています。
必然的にテストは増え続け、ビルド時間は手に負えなくなります。E2Eテストを使ってTDDを行っている場合、ロジックがコードベース全体に散らばってしまい、悲惨な結果になることがあります。
ぜひ、E2Eテストを導入して、広く浅く、つまり記事にあるような10%程度に抑えてください。
こんにちは、マーク 私は、大規模なコードベースでありながらカバレッジが不足しているという、このような特徴を持つプロジェクトに携わりました。
E2Eテストを手始めに開発に品質とスピードをもたらそうとするすべての試みは、コードの品質が低いために失敗しているように見えました。
もし、コードがユニットテストを書くのに十分簡単でないなら、数週間で良い結果を得るためのいくつかのアイディアがあります。
- 最も重要なコンポーネントのための統合テストを書き始める。
- 並行して、これらのコンポーネントのコードのリファクタリングとUnitテストを書き始める。
もし、e-2-e テストがたくさん失敗して、対応するユニットテストが失敗しないなら、問題はおそらくいくつかのユニットテストが欠けていることです。
もし可能なら、その問題を捕らえた単体テストを一つ以上書いてください。コードカバレッジツールが少しは役に立ちます。多くの場合、足りないテストを追加し(e-2-e で初めて表面化したバグを捕捉するためのものなので、最初は失敗するはずです)、ユニットテストの失敗を修正すると、e-2-e のテストの大半か全部が再びパスするようになるでしょう。ユニットテスト環境では見つけられないe-2-eテストの不具合も当然あります。そのような場合、失敗した e-2-e テストをスイートに含めたいものです。
また、e-2-e テストの 90% が合格したら出荷するというのは、おかしな話です。もし失敗したテストがスコープ外であるなら、それを取り除くか、パスするテストに置き換えます。10%」のe-2-eテストの破損で出荷するということは、出荷するものについての良いメンタルモデルを持っていないことを意味します。
ですから、必要なら問題のあるテストを捨ててください。しかし、捨てたテストごとに、それがいくつかの機能を捨てているのか、いくつかのエッジケースを防ぐ必要があるのか、あるいはそのテストが有効でなかった(あるいはもうない)のかを判断できるようにしておく必要があります。
🤔
コメント欄がかなり白熱していて読むのが大変でした。
かなりラディカルな意見もありましたが、E2Eテストが必要となるケースも、少なからずあるし、全てを無くせと言っているわけでは無いと思いました。
ユニット・統合テストが全く無い状態であれば、リグレッションを防ぐために手始めにE2Eテストを書きながらリファクタするという手段もあるし、
E2Eテストに時間がかかりすぎているなら、適切にユニット・統合テストに落として高速でまわせるようにする、といった手段があるなと思います。
テストピラミッドは絶対的な指標なのではなく、フェーズと状態を鑑みてどちらを増やすか、減らすかを戦略的に考えていく必要があるなと思いました。
単体テストのFIRSTの特性については知らなかったので、後で調べてみようと思います。
追記:
CICDのモニタリングをピラミッドの頂点におきたいというコメントは、以下のDevOpsバグフィルターに近い考えかもしれないです。
Licensed under a Creative Commons
Attribution–ShareAlike 4.0 License
この記事が気に入ったらサポートをしてみませんか?