
[Python]辞書型リストをpandasのDataFrameに変換する

はじめに
Pythonで、辞書型のリストをpandasのDataFrame型に変換する実装についてご紹介します。
使用するライブラリ
pandas
データ分析、機械学習の実装で最も使用されるライブラリ。
動作環境
・windows10
・Jupyter Notebook 6.2.0
実装
1. pandas.DataFrame()を使用する
import pandas as pd
vegtables1_1 = [
{
'name': 'バナナ',
'category': 'フルーツ',
'price': 100
},
{
'name': 'りんご',
'category': 'フルーツ',
'price': 120
}
]
df1_1 = pd.DataFrame(vegtables1_1 )
print(df1_1)今回の例のように、シンプルな構造の辞書型のリストをDataFrame型への変換が可能です。
辞書のキーが列名となります。
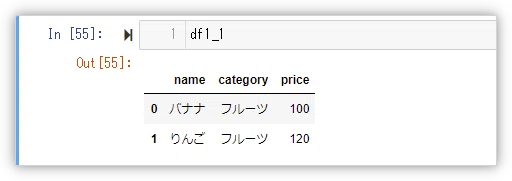
また、指定したキーがない場合の要素は欠損値(NaN)となります。
import pandas as pd
# 'name'がりんごの'price'キーが存在しない
vegtables1_2 = [
{
'name': 'バナナ',
'category': 'フルーツ',
'price': 100
},
{
'name': 'りんご',
'category': 'フルーツ',
},
]
df1_2 = pd.json_normalize(vegtables1_2)
print(df1_2)
2. pandas.json_normalize()を使用する
import pandas as pd
vegtables1_1 = [
{
'name': 'バナナ',
'category': 'フルーツ',
'price': 100
},
{
'name': 'りんご',
'category': 'フルーツ',
'price': 120
}
]
df2_1 = pd.json_normalize(vegtables1_1)
print(df2_1)1.と同様、シンプルな構造の辞書型のリストをDataFrame型への変換が可能です。
辞書型の値がネストしている場合でも、DataFrame型への変換が可能です。
import pandas as pd
vegtables2 = [
{
'name': 'バナナ',
'category': 'フルーツ',
'price': 100,
'id' : {
'code' : 10003,
'lot' : 2106150001
}
},
{
'name': 'りんご',
'category': 'フルーツ',
'price': 120,
'id' : {
'code' : 10009,
'lot' : 2106010008
}
}
]
df2_2 = pd.json_normalize(vegtables2)
print(df2_2)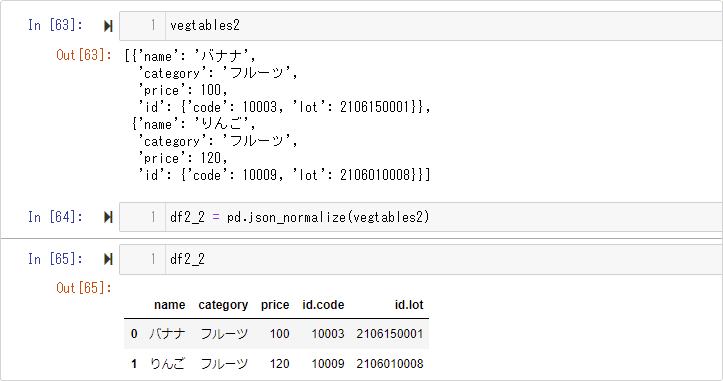
この場合の列名は、デフォルトは、親のキー.子のキーとなります。.部分の指定は、引数sepで設定することが可能です。
pandas.json_normalize()について
pandas.json_normalize()は、pandas1.0.0以前のバージョンでは、pandas.io.json.json_normalize()という名前でした。pandas1.0.0以降のバージョンで、pandas.io.json.json_normalize()を使用すると、下記のようにWarningメッセージが表示されます。
![]()
まとめ
今回は、Pythonで、辞書型のリストをpandasのDataFrame型に変換する実装についてご紹介しました。DataFrame型に変換しておくと、その後のデータ分析作業やデータの出力が、ラクになります。
参考サイト