
【JKI】009_Simple_Anonymization

【JKI_009】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

DeepL翻訳するとこちら。
課題9 簡単な匿名化
レベル 中程度
説明 KNIMEフォーラムに質問を投稿したいが、共有できない機密データを持っている。この課題では、データの機密事項(場所、名前、性別など)を明らかにする列を削除する(または変換する)ワークフローを作成します。その後、残りの列の行をシャッフルして、各数値列が元の統計的分布を維持しながら、他の列と関係を持たないようにする必要があります。これらの列も同様に、ワークフローの最後には特定の意味を持たないような名前に変更します。例を見てみましょう。
例は上述の通りです。参考情報として
データの匿名化に関する当社のリソースをご参照ください。参考までに、このソリューションでは匿名化のために7つのノードと、データが本当に匿名化されたかどうかを確認するために3つのノードを追加で使用しています。
【匿名化について勉強】
匿名化って正しくはどういう意味なんだろうと調べてみました。
特定の個人に関するデータから、個人の識別に直接関わる個人情報を取り除くこと。
上述のKNIMEでの匿名化実装例の記事に加えて日本語化されたディスクリプションを引用してみます。
Anonymization:個人名などの識別子を匿名化するために使用
SHA-1アルゴリズムを適用して、選択した列の値をハッシュ化します。
匿名化をより安全にするために、ソルティング(ここでは固定シード)を適用することもできます。このアプローチの追加の利点は、変換テーブルが2番目の出力ポートで使用できるため、元のデータに戻ることができることです。
Create Hierarchy:組み合わせによって個人を識別できる準識別子に適用
階層を構築するという考え方は、元のデータ(つまり、変更されていないデータ)から精度が低下し、最終的に完全に抑制されたデータに至る複数のレイヤーを持つ複雑なビニングルールを定義することです。ARXには4つのタイプの階層があります。
1.間隔ベースの階層:比率スケールの変数の場合。
2.順序ベースの階層:順序スケールの変数の場合。
3.マスキングベースの階層:この汎用メカニズムでは、文字を「*」に置き換えるだけで、幅広い属性の階層を作成できます。
4.日付ベースの階層:時系列データ用。
下記の記事ではk-匿名化技術を例示してくれていたので引用しておきます。
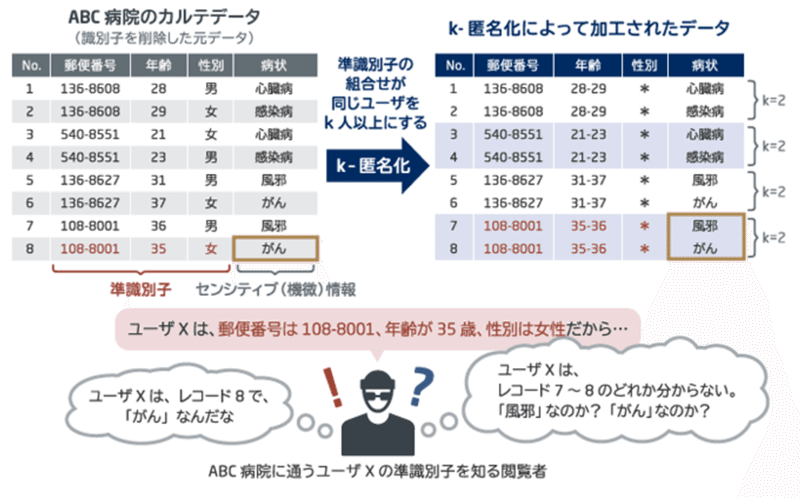
また、匿名化は個人情報保護などには欠かせない技術でありつつも、個人の特定を防ぐことの難しさもある程度は想像できます。
本格的な匿名化技術の難しさは十分伝わってきました。
さて、実は上記全て寄り道です。興味の赴くままに走り出してしまいすみません。
【今回の匿名化手法の特殊さについて】
実は今回の課題は上記技術を利用しないで解答が可能でした。
大きく分けて3つの要求がありましたね。
データの機密事項(場所、名前、性別など)を明らかにする列を削除する(または変換する)
その後、残りの列の行をシャッフルして、各数値列が元の統計的分布を維持しながら、他の列と関係を持たないようにする必要があります。
これらの列も同様に、ワークフローの最後には特定の意味を持たないような名前に変更します。
特に2番目が一般的にはあまりしない匿名化手法ではないかと思うのです。他の列と関係を持たないように列の行をシャッフルします。すなわち各行では特定の個人の状態を表現しませんので、各列の関連性の解析は不可能となり、各列の分布解析程度しかできなくなると考えられるからです。
この手法は匿名化よりもむしろ、機械学習での説明変数の寄与度を評価する時に使う技術のように思いました。
さて、ではworkflow(WF)を作ってみます。
【CSVファイルの格納と読込】
いつも通りのダウンロードとWFファイル内への格納をしました。
データ入手先:
CSV Reader設定:
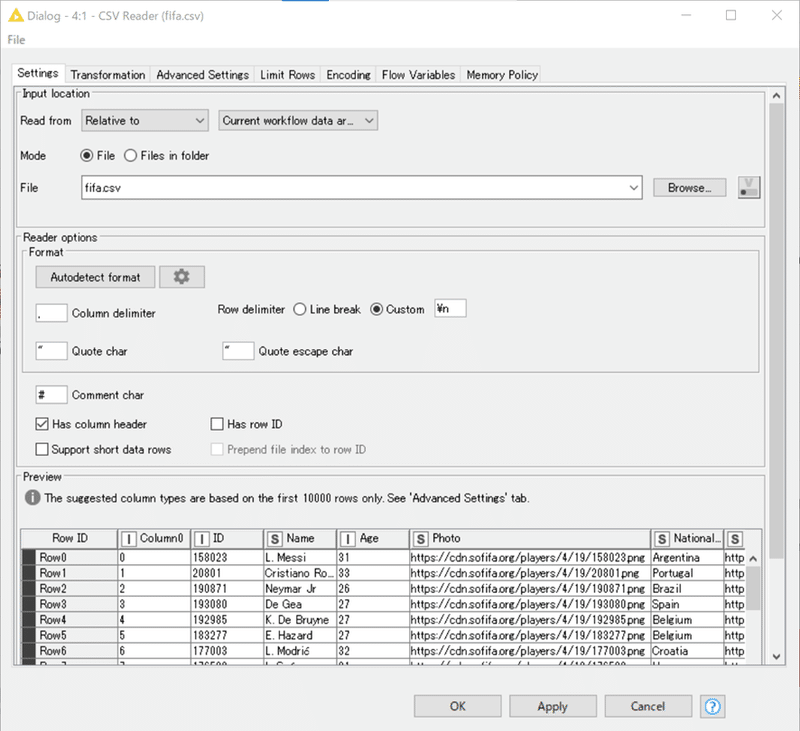
結果:

バルセロナのメッシを筆頭に18207名のデータが!カラム数も89と豊富です。私がサッカーファンなら道草だけで1章書きそうです。
データソースは違うものの参考情報を。道草してすみません。
【機密事項の削除】
データの機密事項(場所、名前、性別など)を明らかにする列を削除する(または変換する)ワークフローを作成します。
どの列が相当するかは明示されなかったので個人的に判断して下記の通り削除しました。
設定:
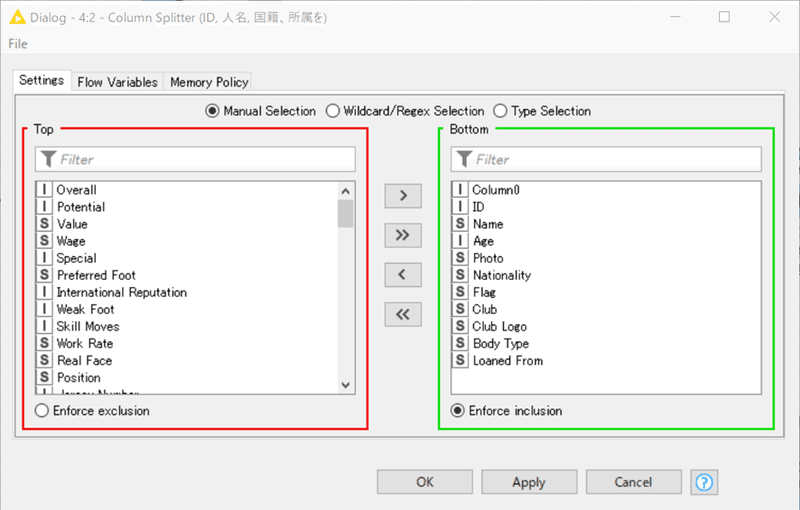
クラブ名は場所データに相当すると判断しています。
Body Typeは普通は体形の判別だと思うのですが、この列のデータに不備があるようで一部個人名などが入力されていましたので削除します。Body Type = Messiってどんなん?

あと、削除しなかったカラム群についてもいくつかのノードでデータ分布を確認して、個人特定につながりうるような偏りがないかなども一応見ました。
例えばですけど、18207名のデータが18207通りに分かれるカラムが残されてしまったら、IDと同じように使えてしまいますよね。本当に詳しく考えると上述のように複数カラムの組み合わせまで検証すべきかもしれませんが、今回は手が出ませんでした。

別件でKNIME日本コミュニティでも話題になっていましたが、こういう時に手軽にデータ分布を見ることができるStatisticsノードって便利だと思います。
【残りの列の行をシャッフル】
残りの列の行をシャッフルして、各数値列が元の統計的分布を維持しながら、他の列と関係を持たないようにする必要があります。
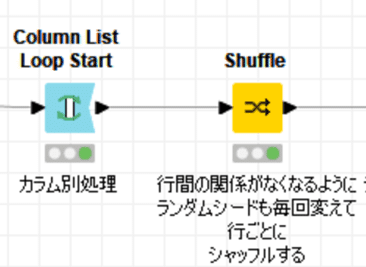
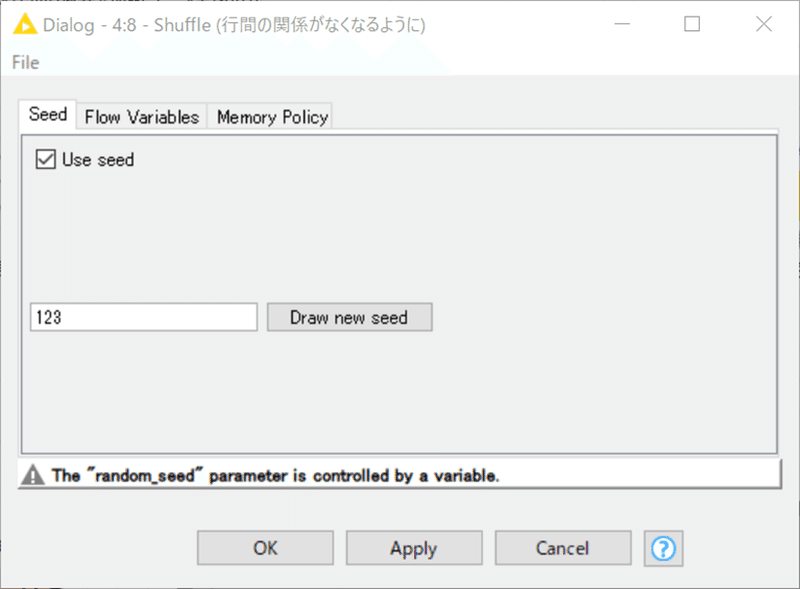
カラム別にループをかけてShuffleすればいいので、上記のようにしています。ランダムシードを指定しなくてもいいのでしょうが、必ず変わるようにと変数で定義して見たりしました。
設定:


【列名も匿名化】
これらの列も同様に、ワークフローの最後には特定の意味を持たないような名前に変更します。
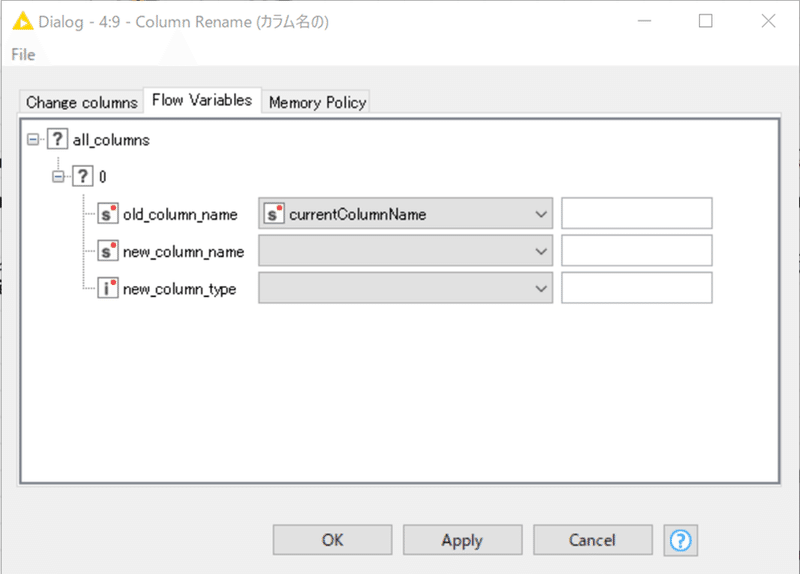
Column Renameで実装可能です。
設定:
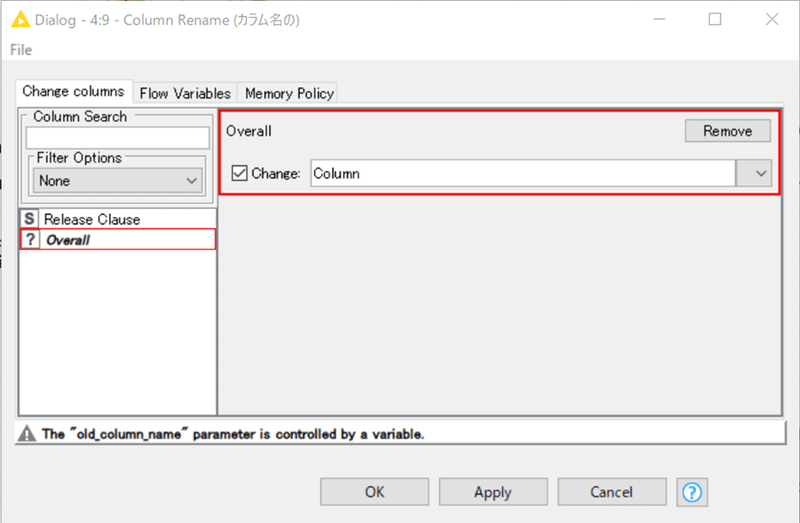
一見するとエラーが出ているように見えますが、ループ処理が完了した状態だと実行前の設定時とは違うカラムがループ処理されている場合に表示されます。実際には改名前のカラム名は変数で指定するので問題なく動作します。
【見事に引っかかりました】
これでLoop Endとつないで完了かと思ったんですよ最初は。でもこれでは匿名化には失敗します。
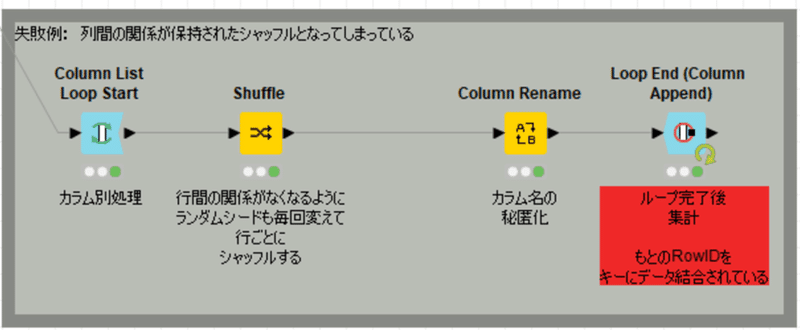
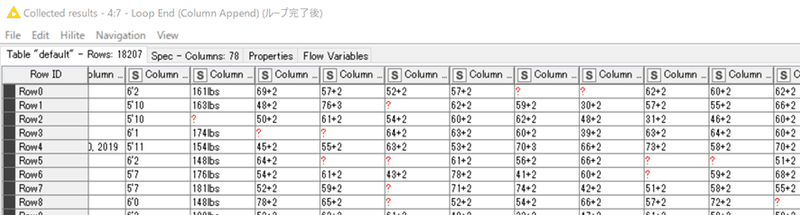
失敗した結果:
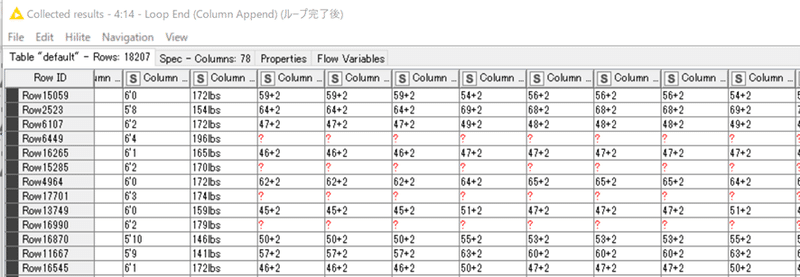
「他の列と関係を持たないようにする必要があります」が、元の関係性を保ったままで単に行順がシャッフルされています。
理由はデータ結合の仕様によります。
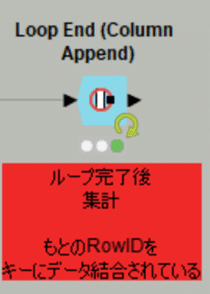
日本語化されたノードディスクリプションから引用します。
ループの最後に位置するノードで、テーブルを行IDで結合して中間結果を収集します。
各反復において、ノードは現在の入力テーブルと前の結果を結合します。
結合は、入力テーブルの行IDに基づいて行われます。
このノードの典型的な使用例は、ループ本体で新しい列のセットを計算し、新しく作成された列のみをこのループエンドノードに供給することです。
このノードは、すべての中間結果(各反復の結果)を結合操作(RowIDカラムのフルアウター結合)で結合します。
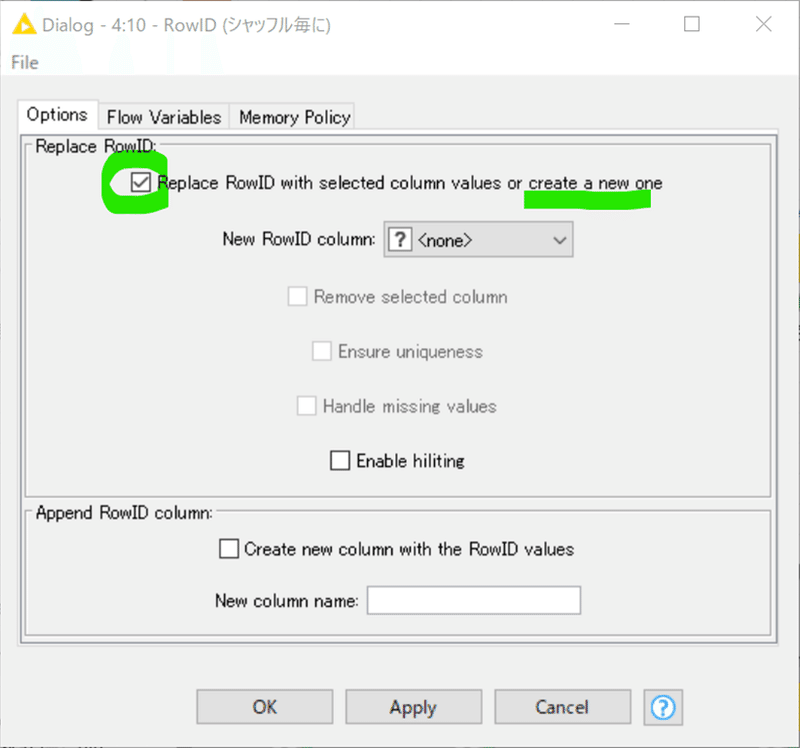
単にシャッフルしただけでRowIDカラムが変化してなければ、もともとのRowIDをキーにデータ結合されるのですから上記の結果になるのが当たり前ということです。
見事に引っかかった感があります。
【解答例の提出】
修正後WFはこちらです。
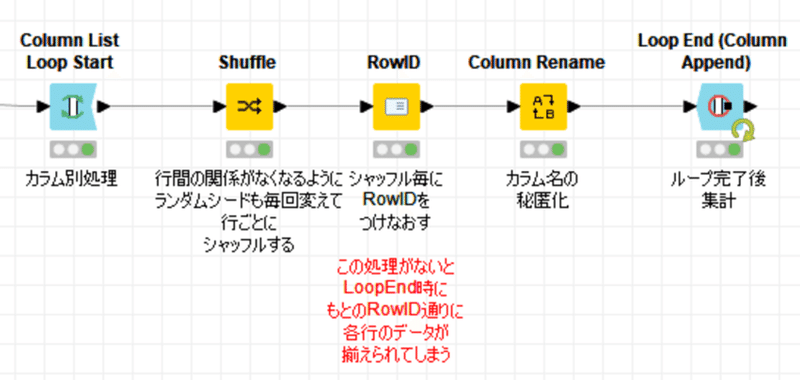
結果:
RowIDは下記の設定で再発番をしています。
WFはアップロードしました。
おまけ:
【JKI_008感想戦】
公式解答しか見ることができていないのですが、なかなか興味深いものでした。
棒グラフは解答1回目で充てた人は誰もいないことは表現する必要がなかったらしく私が独りで問題を難しく考えてあれこれしてしまったようでした。
公式解答は色遣いがきれいだなと思ったので紹介しておきます。

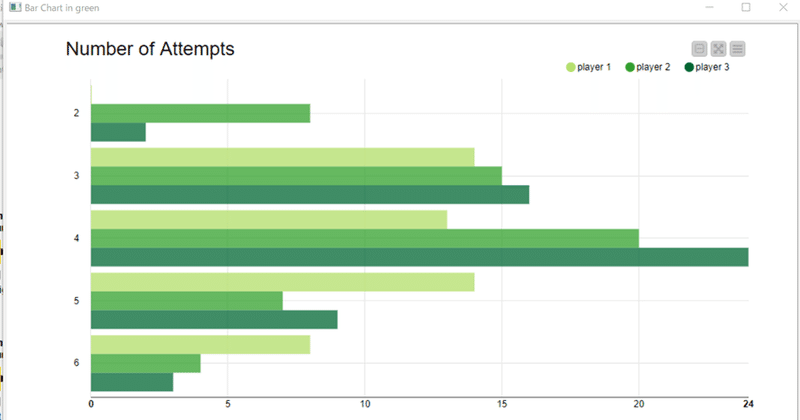
他には、
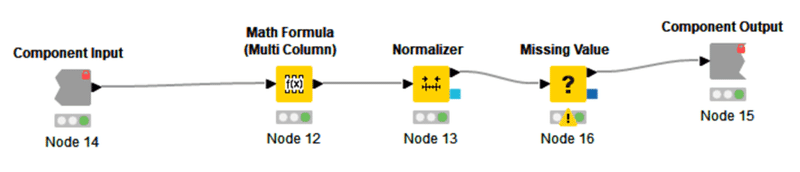
0から10の範囲でのスコアリングにNormalizerを使われていて自分にはない新鮮な発想だと思いました。
重みづけスコアリングについて私は愚直に加重平均を算出に行きました。
一方で、公式解答は目的が順位付けなのでより簡便に実装していました。
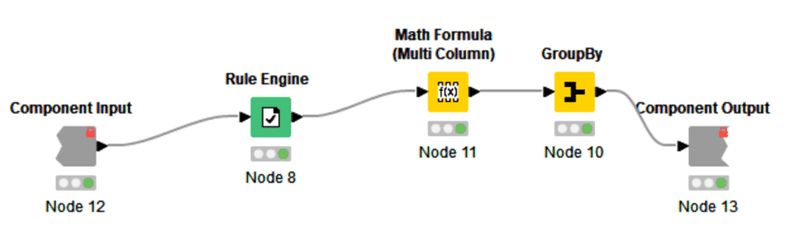
Meanで算出しているから正確には加重平均ではないでしょうが、順位付けには影響がないんですよね。合理的だなと思いました。
以上小並感想戦でした。
最近他の方のWF群までちゃんと味わえていないのがもったいないんです。自分で一回苦労してから他の人の美麗な回答を見ると記憶に深く残るんで、一層勉強になると思うのです。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。