
【JKI】006_Most Popular News Sources_01_TidyData

【JKI_006】課題を確認
Just KNIME It! (JKI)
今回の挑戦はこちら

DeepL翻訳すると
課題6: 最も人気のあるニュースソース
レベル 簡単
説明
ある研究グループが最近のニュース消費の変化を理解するための調査を行っています。彼らは3,000人を対象に、普段どこでニュースを読んでいるかを尋ねるアンケートを実施しました。参加者は、「ソーシャルメディア」、「オンライン新聞」、「印刷された新聞」、「ラジオやテレビ」の中から3つまで選択でき、CSVファイルに数値コードで記録されます。それぞれの説明的な名称は小さな表にまとめてあります。
あなたの仕事は、
(1) アンケートデータのコードを、対応する記述名に置き換えること、
(2) それぞれの選択肢が何回選択されたかを示す対話型のダッシュボードを作成することです。
ダッシュボードでは、ユーザーが興味のある選択肢をフィルタリングできるようにする必要があります。
注:この課題は、さまざまな可視化ノードを試す機会として自由にお使いください。
データ視覚化の自由課題とは。KNIMEユーザにとって視覚化はなかなかチャレンジングな課題ではないかと常々思っているので、とてもEasyとは思えませんが始めます。
【データ視覚化技術いろいろ】
この課題を見て真っ先に思い出したのがまっきーさんのツイートでした。
めっちゃ面白いhttps://t.co/rjNT4yquqF
— まっきー | デジタル推進課 (@makkynm) February 27, 2022
最近視覚化技術についていくつか物しておられるまっきーさんが勧めるだけのことはあるので是非どうぞ。
余談ですがまっきーさんはSpotfireファンのようですね。確かに業界最強な気がします。お高いだけのことはあります。
さて、KNIMEでの視覚化、どこまでできるか。私はあまりダッシュボードのデザイン経験がないので、Infocom社さんからの情報を紹介します。
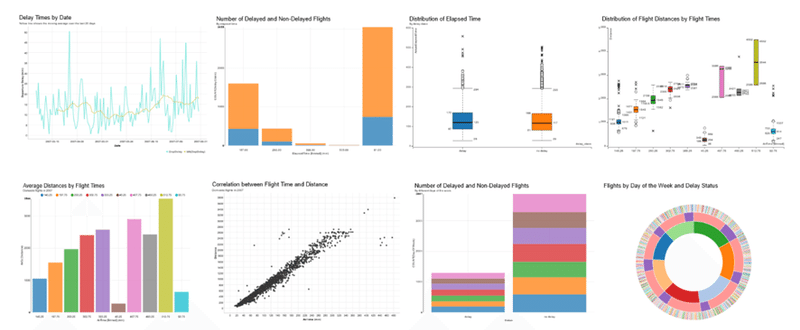
おお、私がやり方を知らないだけで結構できるんだ。
他にもこんなworkflow(WF)を日本語化して下さっています。
これはほぼカンニングになりそうなのであとで見ることにします。
【データセットを入手】
公式サイトからファイル2つを入手し、いつものようにknime-workspace内にdataフォルダを作って格納しました。JKI_005でも同様にしてましたね。
それぞれのReaderで読み込みます。今回も設定画面のみ以下に。
設定:

結果も見ての通り、0-3の4通りの定義のみ。


こちらの読み込み結果は視覚化前の前処理の対象なので詳しく見ていきます。
【データの中身と利用目的で前処理は変わる】
視覚化するにあたって、データの内容を確認しないといけません。場合によってはデータクレンジングだけで全工数の8割を超えることもあると思うのです。
私はこういったことを確認しました。
① 重複するデータはあるか
② 空白値はあるか
③ データ総数は何件ぐらいか
④ 大まかな分布は
そして一番大事だけど単一解はない、結局何を視覚化したらデータのユーザーにとって有用かという問題も考えないといけません。


上記のノード群などいろいろ使ってみてデータを調べました。今回は既にデータをかなり整えてある3000行にしてくれていたので助かりました。
それでも今回のデータで集計上注意した方がよさそうなことを挙げておきます。
【NewsSources.csvファイル】
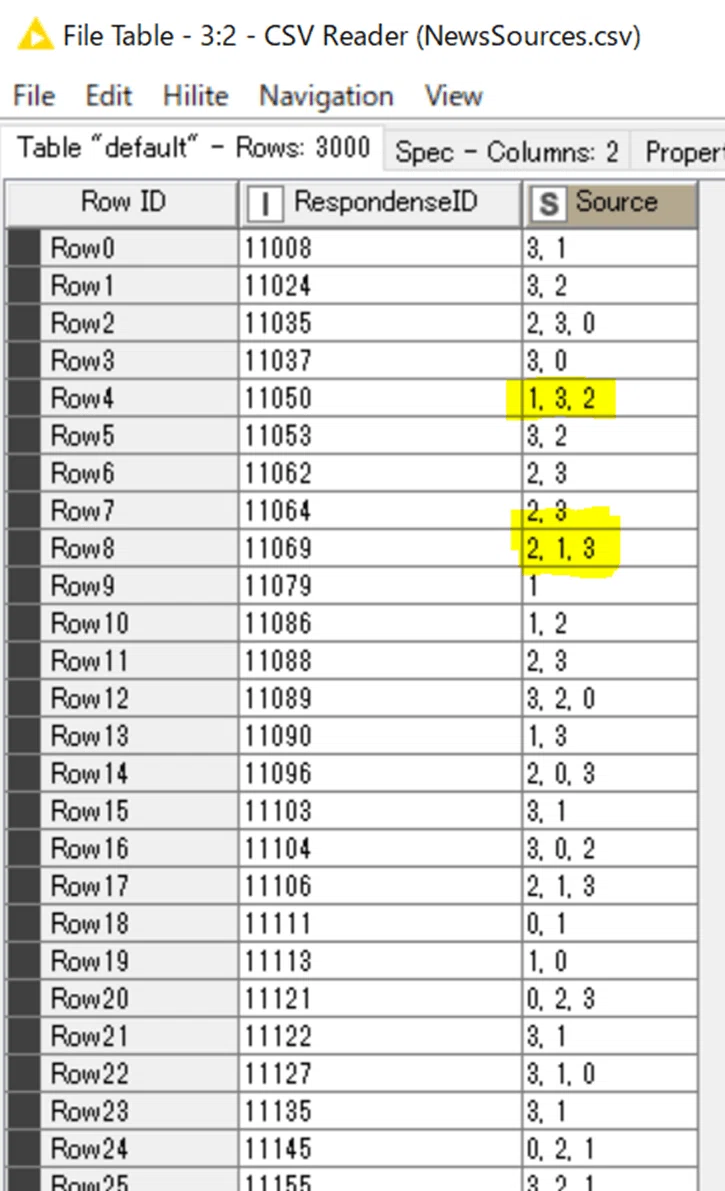
RespondenseIDに重複はなく、Sourceに空白値はなかったですし、1-3項目のみのリストでした。
Webシステムとかで回答された、最多で3つ選べるアンケート結果で回答があった者のみ集めた想定のデモデータかなと思いました。これがExcelでの手入力データだったりすると、リスト部分の区切り文字や空白、全角は混じってないか、リスト内に同じ項目の重複はないかなど一苦労しますよね。
注意するのは複数項目のリストは項目の順序は不定であることかなと思います。たとえば「1, 3, 2」「2, 1, 3」と記載上は異なるけど実際には同じ項目ですよね、
今回の目的の集計であれば同じ項目のセットを使った方がよさそうに思いました。
【リストとセット】
リストとセットで何が違うかというと、例えば順序の情報を含むかどうか、重複を許すかどうかなどが違います。
以下Java使いの方の解説ではあるのですが、KNIMEでのリストとセットと同様なので引用します。
Ordered collection vs Unordered collection
Listは順序があるCollectionです。 Listにデータを入れる順序が保証され、そのため、indexで特定のアイテムを取得することができます。
Setは順序を保証していないCollectionです。そのため、indexで特定のアイテムを取得することができません。
重複許可
Listは重複を許可します。つまり、重複したアイテムをListに追加することができます。
Setは重複を許可していません。つまり、重複したアイテムは、Setに追加されません。重複した値を追加しようとする無視されます。
今回は、回答者がどの項目を先に選んだかは重要ではないし、同じ項目の重複はそもそも生じないデータの入手法だったようですのでSet型のデータとして使おうと思いました。
【Tidy Data】
データ処理の玄人さんはデータをTidy Data型(整然データ)にしてほしいとよく言います。私を含め余り解析ツールに慣れていない人は、Excelでよく現場ユーザー向けに提供される1行ごとに横並びに欲しい情報が並べられたPivot型を好むのと対照的に縦並びの方が解析時の余計な前処理の手間が省けるのだそうです。
「1列1変数」は整然データの最も基本となる条件であり、整然データ作成の出発点とも言えます。
t-kahiさんがとてもわかりやすくKNIMEでのTidy Data型(整然データ)の活用例を紹介して下さっています。
https://speakerdeck.com/tkahi/201128-mishimasyk?slide=9
また、より専門的かつ玄人向けの資料もあるのでお勧めしておきます。
正直玄人さんはTidy Data作成のためのETLにはKNIMEを使うかもしれないですが、視覚化はRとかSpotfire、Tableauを使う気がします。求めるレベルが高いので仕方ないかなと思います。
<ETLツールとしてのKNIME>
いろいろ話すうちに2000字を超えてしまいました。寄り道が過ぎますね。
今回は記事作成はここまでとして、WFを先にKNIME Hubに上げてみました。
もしご興味持っていただけたらKNIMEでご覧ください。

正直に言うと、私はどのツールであろうとも視覚化の経験があまりありません。そのため、KNIMEでのダッシュボードのデザインに四苦八苦しています。次回はその苦闘の途中経過の報告までになりそうです。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。