ワインの品質判定 【知識0でもやってみたい機械学習】

昨今AIブームが騒がれる中、少しでも機械学習をやってみたい。そう思ったことがある人は少なくないはずです。でも機械学習って数学の知識とか難しいプログラミングとかしないといけないんでしょ?
必要な知識、技能
タイトル通り知識は必要ありません。この記事に辿り着けているだけで十分な知識があります。
少し数学のお話が出てくるのですが、噛み砕いて説明するのでどうか構えずに読んでください笑
必要な機材、ソフト
本来は機械学習用の環境構築をするのですが、皆さんが持っている環境 ( pc ) が同じでは無いので Google 先生の力を借ります。
Google Colaboratory というサービスでは機械学習を行う環境を Google 先生が揃えてくれています。しかも全て無料で使うことができます。
今回は Google Colaboratory (以下 colab )を使って機械学習をしていきましょう!
colab の使い方は「colab の使い方(操作手順)」という記事で説明してあるので、使い方がわからない方は下記のリンクから使い方をマスターしてみてください。
機械学習をしてみよう
いよいよ本題ですが、今回は機械学習を使って赤ワインの品質を判定したいと思います。
機械学習にはデータが必要ですが、UCI が公開している機械学習のデータがあるのでそれを使うことにします。酸性度、揮発性酸性度、クエン酸などのワインの成分値と、品質( 0 - 10 ) 11 段階評価が収録された有名なデータセットです。
まず、先ほどと同じように画面左上の「ファイル」から「Python 3 の新しいノートブック」を押します。
新しいタブで Python 3 の実行環境が出来上がるので、左上の「ノートブック名」を winequality に変更しておきましょう。
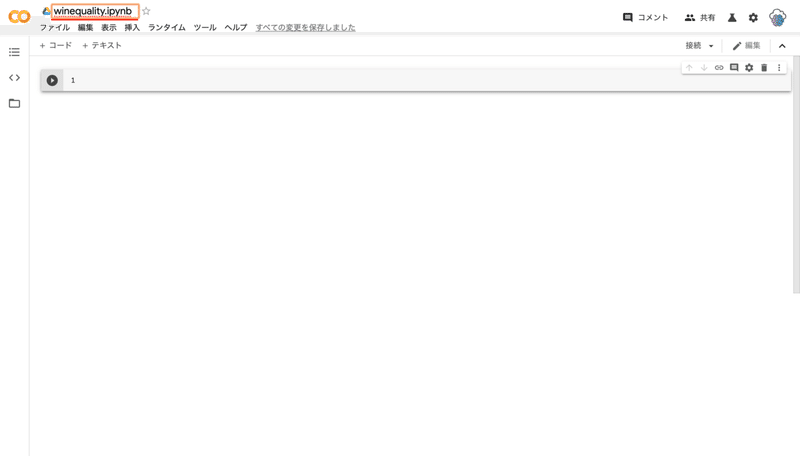
コードを説明する際に行番号がついていた方が説明しやすいので、画面右上の歯車マークの「設定」から「エディタ」そして「行番号を表示」にチェックを入れて保存します。
ここからは Python のコードを書いていきますが、一つ一つ解説をするので読めなくても問題ありません。写経していきましょう!
まずは今のセルの上に「テキスト」のセルを追加してタイトルを付けます。
もし間違えて不要なセルを追加してしまった場合は、セルの右側にあるゴミ箱マークの「セルの削除」からセルを消すことができます。
「テキスト」のセルが追加できたら、セルをダブルクリックしてタイトルを書きます。マークダウン方式なので見出しは「#」と半角スペースをタイトルの前に付けます。
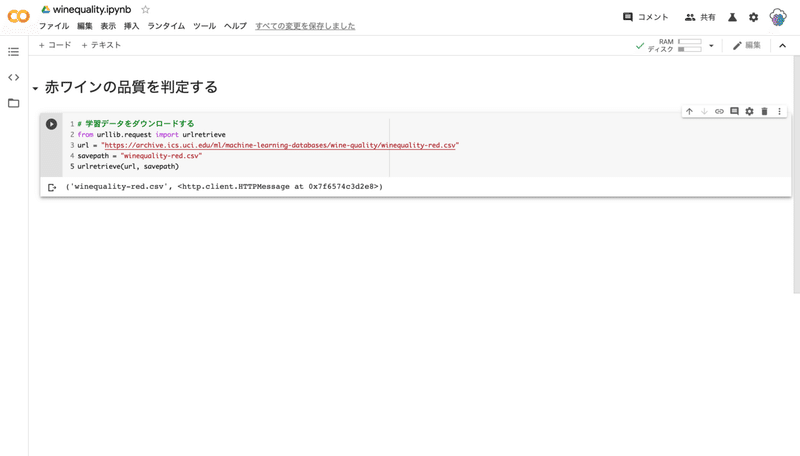
タイトルが書けたら「コード」セルに下記のコードを書いて実行します。手打ちでコードを書きたいのであれば止めはしませんが、url など間違えやすい物はコピペすることをおすすめします。
# 学習データをダウンロードする
from urllib.request import urlretrieve
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
savepath = "winequality-red.csv"
urlretrieve(url, savepath)
--- コード解説 ---
一行目の「#」はコメントアウトです。「#」以降の文字は実行されません。
二行目以降は UCI のサイトから CSV 形式のデータをダウンロードしています。
--- コード解説終わり ---
実行が終わったら、画面左のファイルアイコンから「ファイル」を開き winequality-red.csv がダウンロードされていることを確認してください。
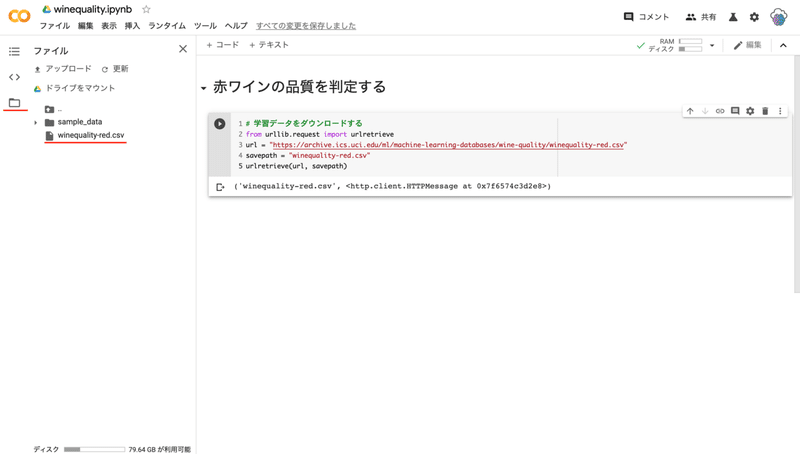
確認できたら「コード」セルを追加し、下記のコードを書いて実行します。
# データの読み込み
import pandas as pd
wine = pd.read_csv("winequality-red.csv", sep=";", encoding="utf-8")
wine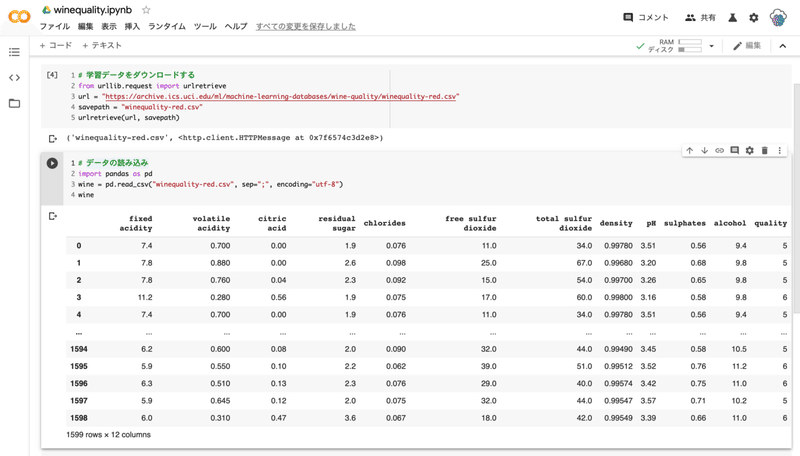
--- コード解説 ---
先ほどダウンロードした CSV 形式のファイルを読み込んでいます。データ同士の区切り文字が「;」で、文字コードが「utf-8」の指定をしてあります。
--- コード解説終わり ---
出力結果から 0 - 1598 までの 1599 個のデータがあることがわかります。
実行が終わったら「コード」セルを追加し、下記のコードを書いて実行します。
# データをラベルとデータに分離
y = wine["quality"]
x = wine.drop("quality", axis=1)
--- コード解説 ---
今回は酸性度、揮発性酸性度、クエン酸などのワインの成分値から、品質を予測したいので、y という変数に quality (品質) を、x という変数に drop(quality) (品質以外) を代入しています。
--- コード解説終わり ---
今回は代入しただけなので、実行しても何も起こりません。
実行が終わったら「コード」セルを追加し、下記のコードを書いて実行します。
# 学習用とテスト用に分類する
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8, shuffle=True)
--- コード解説 ---
ダウンロードしたデータの全てを学習してしまった場合、どのデータを予測してもおおよそ正解してしまうことが予想できます。なので今回はダウンロードしたデータの 8 割を学習させて、残りの 2 割を未知のデータ(学習していないデータ)として使うことにします。shuffle=True を指定することで、データの順番をシャッフルしてから学習データと未知のデータに分類することができます。
--- コード解説終わり ---
今回も分類しただけなので、実行しても何も起こりません。
実行が終わったら「コード」セルを追加し、下記のコードを書いて実行します。
# 学習する
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(x_train, y_train)
--- コード解説 ---
いよいよ学習ですが、今回はランダムフォレストというアルゴリズムを使います。このアルゴリズムを噛み砕いて説明すると、まず「酸性度」が 5.9 より大きいか?で二分されます。その次に「揮発性酸性度」が 0.510 より大きいか?でさらに二分されます。その次に「クエン酸」が 0.13 より大きいか?でさらに二分されます。その次に... というように条件分岐で分類されていき、最終的にこの分類は品質 5 、この分類は品質 7 、と決まっていきます。(わかりやすいように噛み砕いたので、数値や条件などは適当です)
--- コード解説終わり ---
今回も学習しただけなので、実行しても何も起こりません。
実行が終わったら「コード」セルを追加し、下記のコードを書いて実行します。
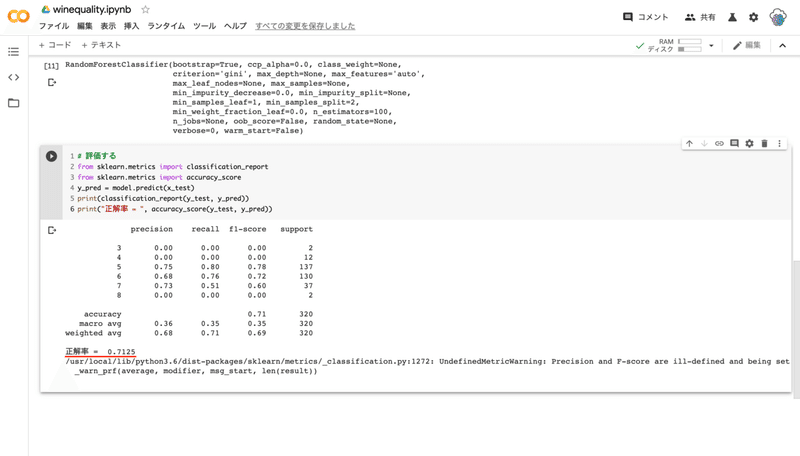
# 評価する
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("正解率 = ", accuracy_score(y_test, y_pred))
--- コード解説 ---
どれくらいの精度で判定できたのかを確認します。学習用データで学習したモデルに未知のデータ(学習していないデータ)を与えて、実際の品質(正解)と予測した品質(機械学習)を比較します。
正解率は 0.7125 ( 71.25% ) でした。(学習データをシャッフルしたため、正解率には個人差があります)
--- コード解説終わり ---
ここまで実行できれば機械学習をすることができたと言えます。知識0の状態から機械学習をすることができ、素晴らしいと思います。
さて、先ほどの正解率 0.7125 という数値は精度が高いと言えるのでしょうか?
実はあまり精度が高いとは言えないのです。
機械学習の本当の楽しさはここからで、どうすれば正解率を上げることが出来るのか?を考えて工夫するところこそ面白いのです。
という訳でこの続きでは、このモデルを正解率 0.95 くらいまで上げていこうと思います。
実は精度が高くない原因が既に書かれていたのですが、わかりますか?最後の実行をした際に「UndefinedMetricWarning」という警告文が出ていました。
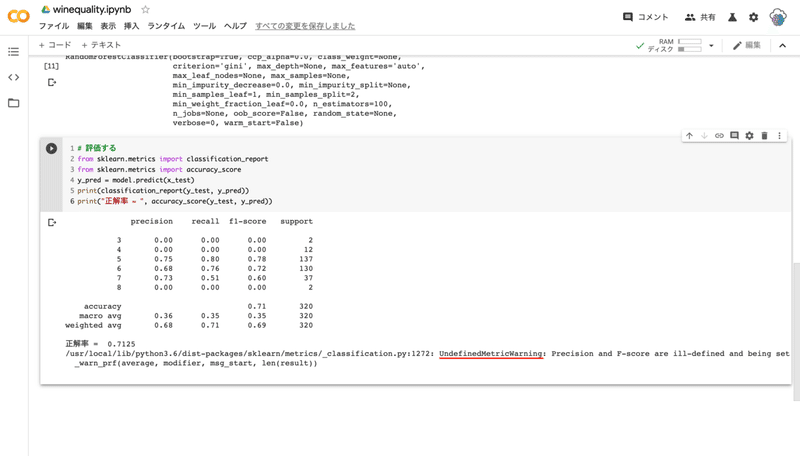
これはワインのデータに原因があり、全てのラベルにデータが分類されていない事を表しています。
言い換えるとワインのデータのラベル、つまり品質は 0 - 10 の 11 段階評価で数値が付けられていますが、分類されていない品質の数値があるという事です。
では、それぞれの品質のデータがいくつ存在するのか調べてみます。
最後の実行の下に「コード」セルを追加し、下記のコードを書いて実行します。
import matplotlib.pyplot as plt
# 品質データごとにグループ分けして、数を数える
count_data = wine.groupby('quality')["quality"].count()
print(count_data)
# 数えたデータをグラフに描画
count_data.plot()
plt.savefig("wine-count.png")
plt.show()
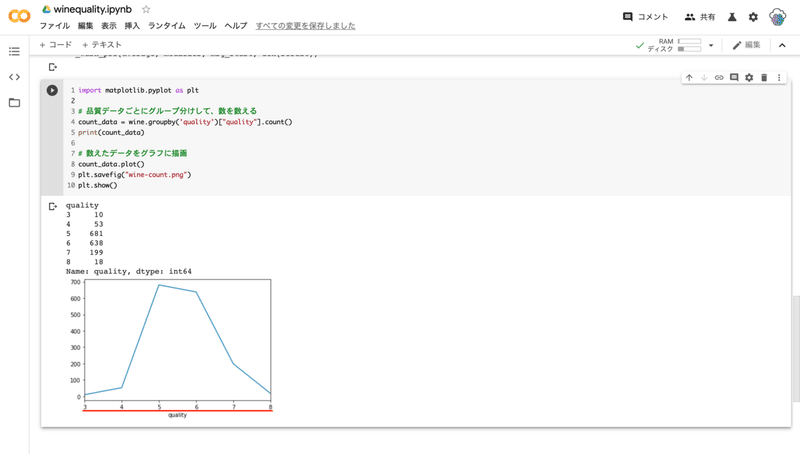
--- コード解説 ---
データから品質 ( quality ) の値をカウントします。この際、groupby() を使う事で、データをまとめてカウントできます。
カウントしたデータはグラフとして描画することもできます。生の数値で見るよりも分かりやすいです。
--- コード解説終わり ---
数値とグラフの横軸を見て貰えば分かりますが、なんとこのデータには 2 以下と 9 以上の数値がありません。そして 3 と 7 のデータは数が少ないことが分かりました。
これだけデータに偏りがあると精度が高くならないのも理解できます。アルゴリズムを変えるというアプローチもありますが、今回はラベルを付け直して精度を上げたいと思います。
コードが続きから書けないので「テキスト」セルを追加し、新しい見出しをつけて最初からコードを書きます。
見出しを付け終えたら「コード」セルを追加し、下記のコードを書いて実行します。
2020/2/3 追記:Python という言語ではインデント(半角スペース)が意味を持ちます。コードを手打ちする際は、行頭を詰めてしまわないように注意してください。
import pandas as pd
from urllib.request import urlretrieve
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
savepath = "winequality-red.csv"
urlretrieve(url, savepath)
wine = pd.read_csv("winequality-red.csv", sep=";", encoding="utf-8")
y = wine["quality"]
x = wine.drop("quality", axis=1)
# ラベルを付け直す
newlabel = []
for v in list(y):
if v <= 3:
newlabel += [0]
elif v <= 7:
newlabel += [1]
else:
newlabel += [2]
y = newlabel
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8, shuffle=True)
model = RandomForestClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("正解率 = ", accuracy_score(y_test, y_pred))
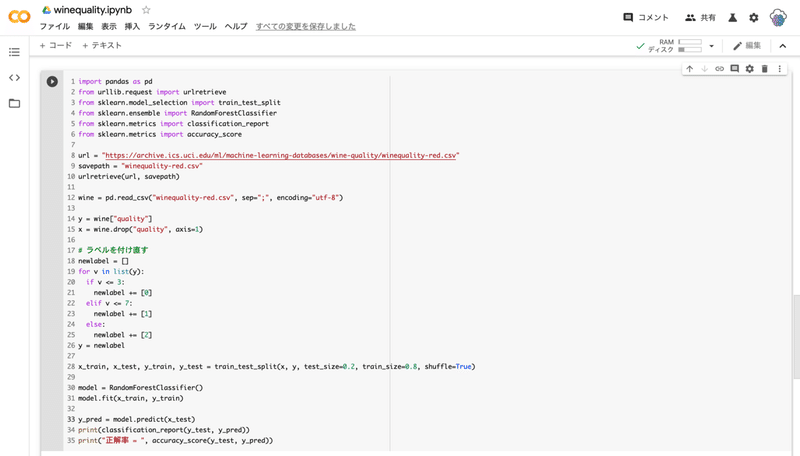

--- コード解説 ---
17 行目から 26 行目では、for 文を使って 3 以下の品質は 0 に、4 - 7 の品質は 1 に、8 以上の品質は 2 という新しいラベルに付け直しています。
--- コード解説終わり ---
ラベルを付け直すことで正解率を 0.978125 (97.81%) まで上げることができました。しかし、「UndefinedMetricWarning」という警告文は消えませんでした。今回の場合 1599 個のデータを扱っていましたが、3 以下の品質のデータが 10 個、8 以上のデータが 18 個、と少なかったため警告文が消えませんでした。データの母数に対して、各ラベルのデータが極端に少なくなければこの警告文は消えます。
今回はラベルを付け直すというアプローチで正解率 0.95 くらいまで上げることができました。アルゴリズムを変えるだけではなく、時にはデータを手直しすることも重要です。
ここまでオマケとしてやってきましたが、ここまで全て実行できた人は自走する力があるのでこれからの活躍に期待しています笑
手を動かしながら勉強してみて、機械学習が少しでも楽しい、面白いと思っていただけたら幸いです。
白ワインバージョンのコードのダウンロードと Twitter の DM での質問等を受け付けたいと思います。
白ワインバージョンのコードですが、下記からダウンロードすることができます。(当たり前ですが二次配布は禁止いたします)
使い方は、ダウンロードが完了したら画面左上の「ファイル」から「ノートブックをアップロード...」を押します。
ファイル選択画面が出てくるので、ダウンロードした winequality-white.ipynb を選択することで新しくダウンロードしたノートブックを開くことができます。
今まで書いていたコードに上書きされる訳ではないので安心してください。
Twitter ですが、下記のリンクから私のホームに飛ぶことができます。DM を一般公開しておきます。(純粋な感想もとても嬉しいです)
質問をする際は、質問を投げるだけではなく、何がしたいのか?どこまで試したのか?等を説明していただけると答えやすいです。
それでは最後まで読んでいただきありがとうございました。
サポートは書籍購入や記事を書く際の素材費として使わさせていただきます!