
DataRobotの無料版!?機械学習を自動化するライブラリ『PyCaret』入門

PyCaretとは
つい先日Announcing PyCaret 1.0.0という記事を拝見しました。
面白そうなライブラリだったため、この記事では、実際にPyCaretの使い方を解説していきます。
PyCaretとは、機械学習のモデル開発においてデータ前処理や可視化、モデル開発を数行のコードで出来てしまうPythonのライブラリです。
PyCaretはいくつかの主要な機械学習ライブラリ(scikit-learn, XGBoost, LightGBMなど)をPythonでラッパーしたものです。
分類や回帰、クラスタリング、異常検知、自然言語処理が扱えます。
言わば、PyCaretは、DataRobotの無料版のようなイメージです。
基本的に、前処理、モデリング、性能評価、チューニング、可視化まで一通り出来るそうです。
さらに、スタッキング等も出来ます。
(時系列解析やLog lossなどの一部の評価指標がなさげです。)
PyCaret/Github
また、対象読者は、既にscikit-learnを用いて機械学習の一連を入門したよ!って言う方です。
(機械学習初学者だと、内容がわからなくなる可能性があります。とりあえずなんか過ごそう。。って感じで終わると思います。自社サービスで恐縮ですが、AI Academyなどを使って、機械学習プログラミングを入門してみてください!)
PyCaretを使って、kaggleのCredit Card Fraud Detectionに取り組んだ解説動画もありますので、こちらも是非見てみてください。
PyCaretをやってみよう!
まずはPyCaretのインストールです。
ターミナルやコマンドプロンプトからインストールの場合は、以下のコマンドでインストール出来ます。
pip install pycaretJupyter NotebookやGoogle Colabでは先頭に!をつけて以下のコマンドにてインストール出来ます。
!pip install pycaret
## 必要なモジュールの読み込み&データの準備
今回は、irisデータセットを用いて多クラス分類をしてみます。
まずは必要なコードを読み込みます。
import warnings
# 不要な警告文消すよ
warnings.filterwarnings("ignore")
# 今回の主役!PyCaretを読み込みます。
from pycaret.classification import *
# Irisデータセットを読み込みます。
from sklearn.datasets import load_iris
# データフレーム扱うのでPandasも読み込みます。
import pandas as pd
次に、データを準備します。
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.DataFrame(iris.target, columns=["target"])
df = pd.concat([X,y], axis=1)
先頭5件表示。
df.head()
## 前処理
いざ!前処理。
setup()を使うと、欠損値処理、データ分割などを行なってくれます。
targetには、目的変数を渡します。
exp1 = setup(df, target = 'target')
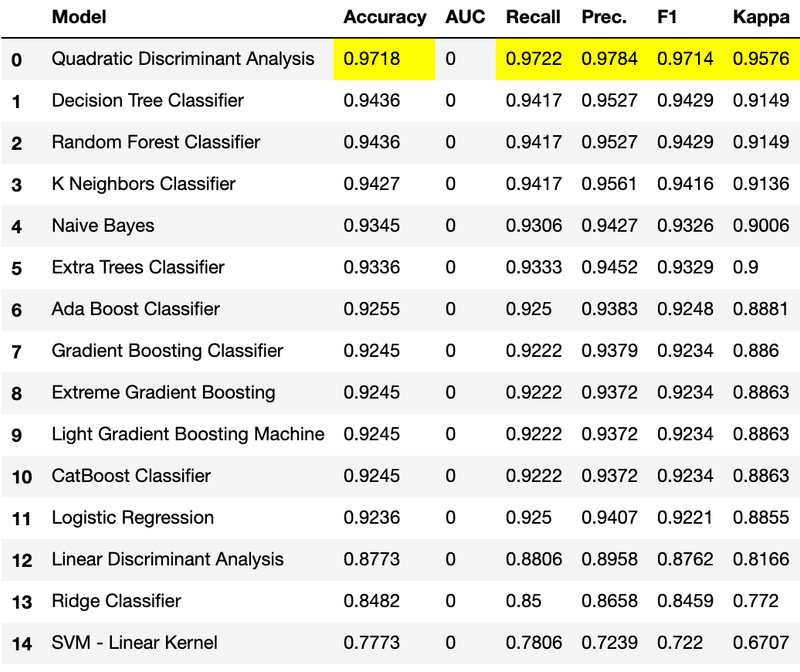
モデルを比較しよう
モデルの比較はcompare_models()を使うだけです。
compare_models()
モデリング
https://pycaret.org/create-model/を参考にして、学習に利用するアルゴリズムの名称を入力します。
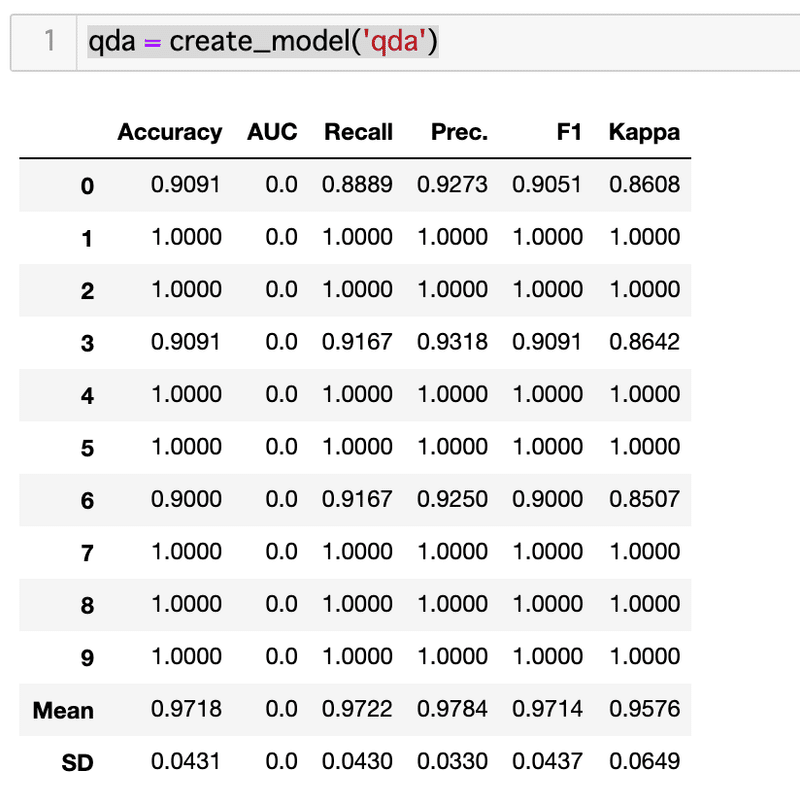
今回は、正解率が最も高かった『2次判別分析 (Quadratic Discriminant Analysis)』と決定木を利用します。
Quadratic Discriminant Analysisは、'qda'と入力すれば良いそうなので、今回はqdaと入力します。
qda = create_model('qda')
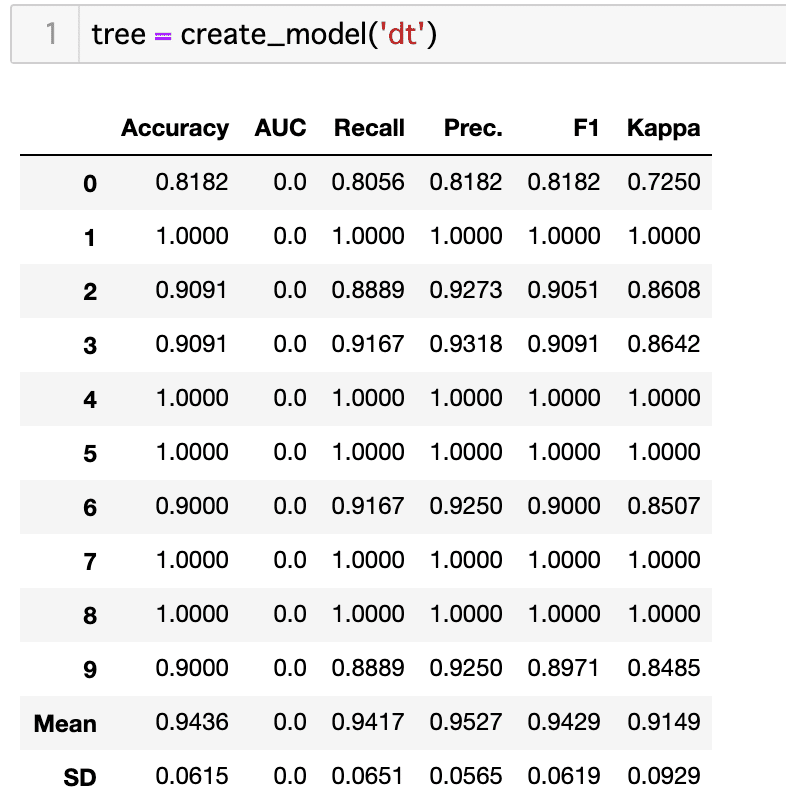
決定木も試してみましょう。
tree = create_model('dt')
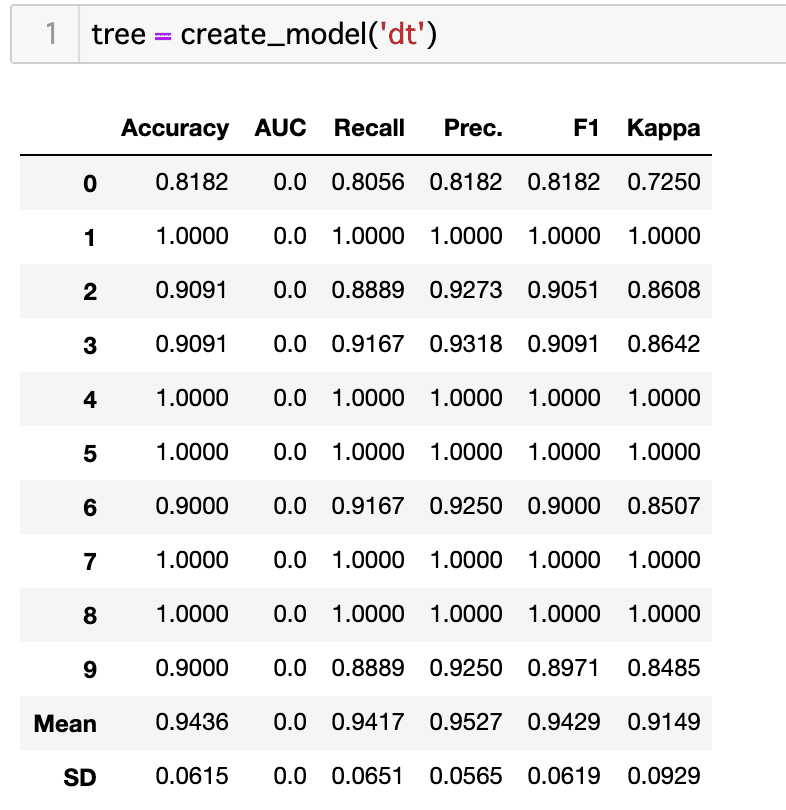
チューニング
決定木をチューニングしてみます。
tuned_tree = tune_model('dt')
パラメータの取得
tuned_tree.get_params
モデルの可視化
plot_model(tuned_qda)
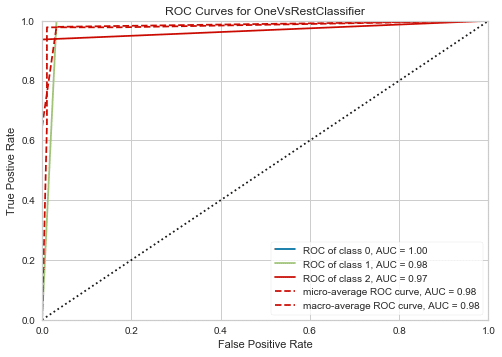
plot_model(tuned_tree)
アンサンブル学習
lgbm = create_model('lightgbm')
xgboost = create_model('xgboost')
ensemble = blend_models([lgbm, xgboost])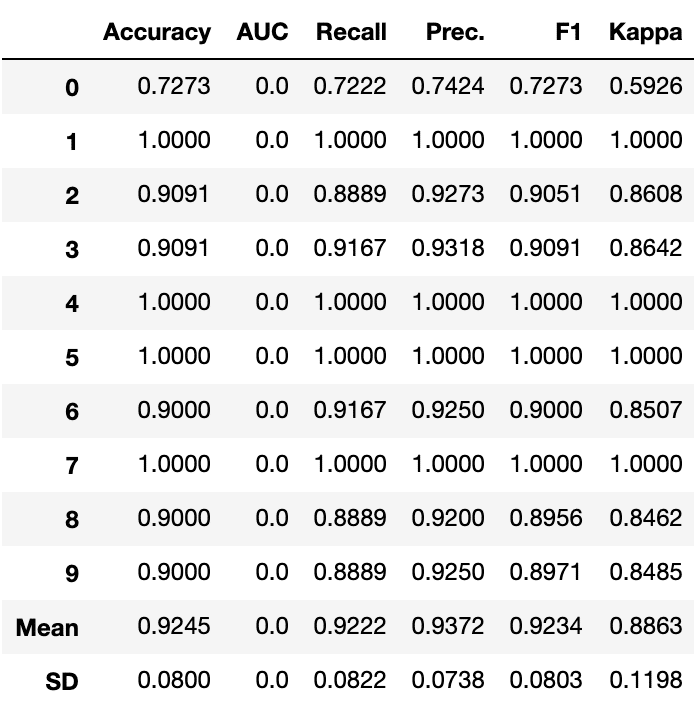
スタッキング
stack = stack_models(estimator_list = [xgboost], meta_model = lgbm)
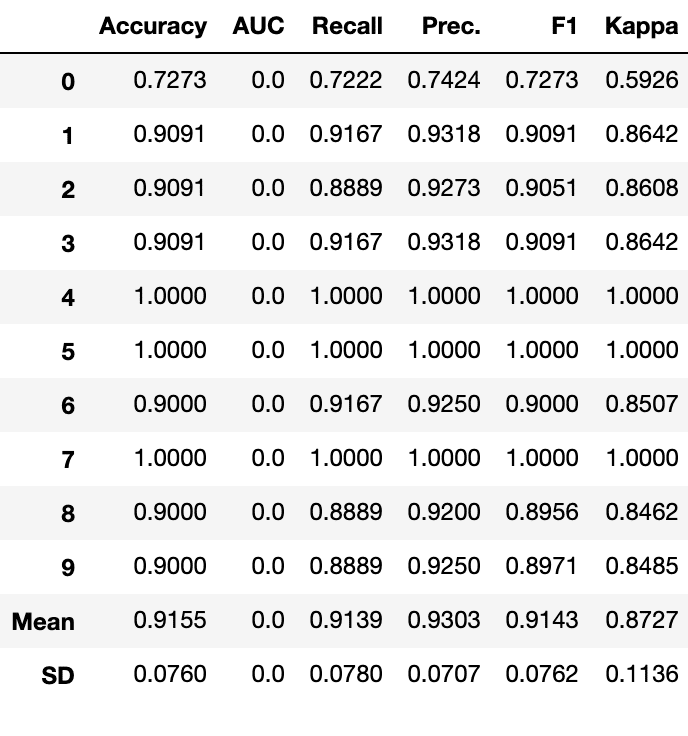
予測
pred = predict_model(qda)
はい、便利。
最後に
数行で、一通り出来ました。。
これから少しずつ使ってみようかと思います。
参考サイト
参考にさせて頂いた記事です。
この記事以外にも是非参考にしてみてください。
この記事を書いた人
サイバーブレイン株式会社
代表取締役CEO 谷 一徳
フォローお待ちしております!
Twitter
Facebook
5000名以上が参加しいてるAIコミュニティも運営しております。
毎日AIに関する情報を提供しておりますので、こちらのご参加もお待ちしております!
人工知能研究コミュニティ
AI Academy
この記事が気に入ったらサポートをしてみませんか?