【Python(1)】Googleキーワード検索ボリュームを自動取得しよう。

こんにちは(@t_kun_kamakiri)
ブログのアクセスを集めるためにはキーワード検索ボリュームを調べてどのキーワードを狙うべきか見定めるはとても重要なことです。
いつもはキーワード検索ボリュームはキーワードプランナーを使って手動で調べているですが、この作業がめちゃくちゃ面倒です。
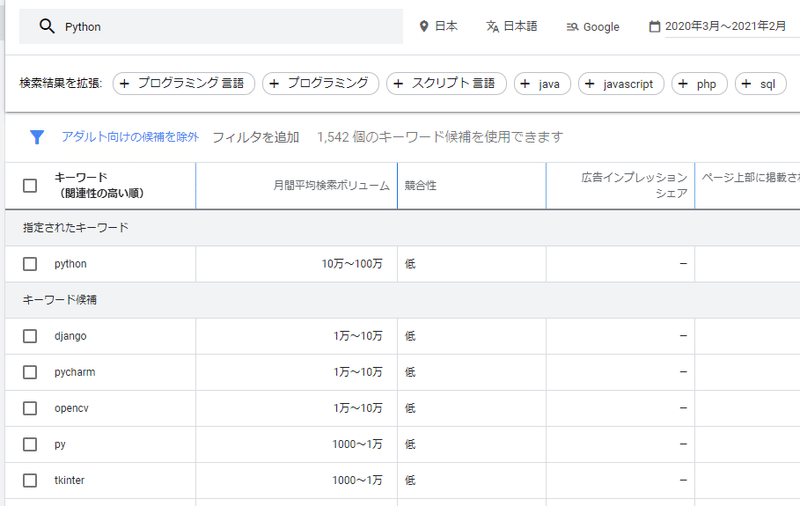
↑手動でこんな感じで調べます・・・・
できれば自動で取得するプログラムがあればなんと便利なことか。
本記事ではPythonを使ってGoogleのキーワード検索ボリュームの自動取得までの流れを解説したいと思います。
参考にした記事はこちらです。
アカウントとアクセスキーを取得
こちらの記事を参考に以下の必要なアカウントとアクセスキーを取得します。
●Googleアカウント: Google広告を利用できるアカウント
●MCCアカウント:developer_token
クライアント センター(MCC)アカウントは、複数のGoogle広告アカウント管理のためのアカウント。API開発者トークン取得
●APIプロジェクトアクセス用アカウント :
client_id , client_secret,refresh_token
●テストアカウント :login_customer_id
APIプロジェクトの作成とOAuthクライアント作成
こちらの記事を参考に認証用のclient_secretxxxxxxx.jsonファイルを作成してください。
Pythonの必要なライブラリをインストール
コマンドプロンプトで
pip install google-ads==8.2.0と打って「google-ads」ライブラリをインストールしましょう。
最新版は「google-ads 10.0.0」なのですがPython 3.8.5との相性が悪いのかインポートがうまくいかないため今回はバージョン指定して、「google-ads 8.2.0」としてインストールします。
必要なファイルを入手
必要なファイルは下記から入手します。
google-ads.yaml
examples/authentication/authenticate_in_desktop_application.py
examples/planning/generate_keyword_ideas.py
↓こちらはどちらのファイルでも良いです。
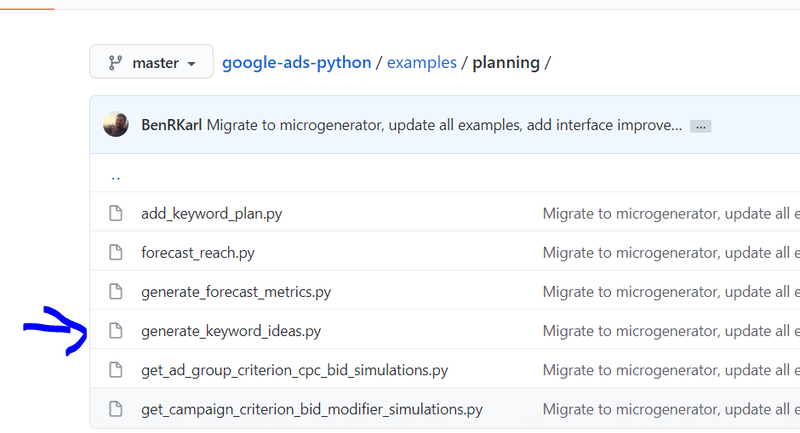
OAuth認証とリフレッシュトークンの取得
ここまでの手順でrefresh_token以外は作成出ました。
以下のコマンドをコマンドプロンプトで打ってrefresh_tokenを作成します。
詳しくはこちらの記事で解説があります。
jsonファイルの名前はclient_secret.jsonとしておきましょう。
python authenticate_in_desktop_application.py --client_secrets_path ./client_secret.jsonキーワードアイデア取得スクリプトの実行
そして「google-ads.yaml」に以下の記述を書いておきます。
developer_token: xxxxxxxxxxxxxxx #開発者トークン
client_id: 149351412578-pre9tcg4rr........com #client_secret.jsonから抜き出し
client_secret: gOQHW................... #client_secret.jsonから抜き出し
refresh_token: 1//0e4.................... #リフレッシュトークン
login_customer_id: 1234253142 # テストユーザーのID(ハイフン無し)このgoogle-ads.yamlはGoogleキーワード検索ボリュームを調べる際に読み込まれるのですが、デフォルトの読み込み場所が「Cドライブ」直下なのでCドライブ直下に置いておきます。
Googleキーワード検索ボリュームを自動取得
では、「「planning/generate_keyword_ideas.py」のファイルを以下のようにして実行してみましょう。
python3 generate_keyword_ideas.py -c 1234253142 -k "ブログ"ここで「1234253142 」はご自身のlogin_customer_idを指定するのですが、毎回pythonファイルを実行するときにコマンドプロンプトに打ち込むのは面倒ですよね。
その他にもいろいろとファイル内を書き換えておいた方が良い内容があるので以下ので修正箇所を解説します。
ファイル内を変更
●login_customer_idはファイル内に書き込む
●検索の言語を日本語対応にする
●検索地域を指定する
上記の内容を変更します。
特に検索の言語を日本語にしておかないとデフォルトがNY(ニューヨーク)なので日本語で検索してもうまく検索ボリュームを調べることができません。また、検索ボリュームを調べる地域もデフォルトがNY(ニューヨーク)なので上記のことを踏まえてコードを変更しました。
generate_keyword_kamakiri.py
※ファイル名は変えました。
#!/usr/bin/env python
# Copyright 2019 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""This example generates keyword ideas from a list of seed keywords."""
import argparse
import sys
from google.ads.google_ads.client import GoogleAdsClient
from google.ads.google_ads.errors import GoogleAdsException
import os # add
import pandas as pd #add
# 日本全地域のIDs
# df = pd.read_csv('geotargets-2020-11-18.csv')
# df_JP = df[df['Country Code']=='JP']
# ParentIDs = df_JP['Parent ID'].unique().astype(int)[:-1].astype(str)
'''
都道府県ランキングトップ10
https://ja.wikipedia.org/wiki/%E9%83%BD%E9%81%93%E5%BA%9C%E7%9C%8C%E3%81%AE%E4%BA%BA%E5%8F%A3%E4%B8%80%E8%A6%A7
東京、神奈川、大阪、愛知、埼玉、千葉、兵庫、北海道、福岡、静岡
'''
ParentIDs = ["20636", "20637", "2392", "20646", "20634", "20635", "20651", "20624", "20663", "20645"]
# Location IDs are listed here: https://developers.google.com/adwords/api/docs/appendix/geotargeting
# and they can also be retrieved using the GeoTargetConstantService as shown
# here: https://developers.google.com/google-ads/api/docs/targeting/location-targeting
_DEFAULT_LOCATION_IDS = list(ParentIDs)[0:11] # location ID for New York, NY
# A language criterion ID. For example, specify 1000 for English. For more
# information on determining this value, see the below link:
# https://developers.google.com/adwords/api/docs/appendix/codes-formats#languages.
_DEFAULT_LANGUAGE_ID = "1005" # language ID for English
# customer_id
customer_id = "1234253142 "
# [START generate_keyword_ideas]
def main(
client, customer_id, location_ids, language_id, keyword_texts, page_url
):
keyword_plan_idea_service = client.get_service(
"KeywordPlanIdeaService", version="v6"
)
keyword_competition_level_enum = client.get_type(
"KeywordPlanCompetitionLevelEnum", version="v6"
).KeywordPlanCompetitionLevel
keyword_plan_network = client.get_type(
"KeywordPlanNetworkEnum", version="v6"
).GOOGLE_SEARCH_AND_PARTNERS
gtc_service = client.get_service("GeoTargetConstantService", version="v6")
locations = [
gtc_service.geo_target_constant_path(location_id)
for location_id in location_ids
]
language = client.get_service(
"LanguageConstantService", version="v6"
).language_constant_path(language_id)
# Only one of these values will be passed to the KeywordPlanIdeaService
# depending on whether keywords, a page_url or both were given.
url_seed = None
keyword_seed = None
keyword_url_seed = None
# Either keywords or a page_url are required to generate keyword ideas
# so this raises an error if neither are provided.
if not (keyword_texts or page_url):
raise ValueError(
"At least one of keywords or page URL is required, "
"but neither was specified."
)
# To generate keyword ideas with only a page_url and no keywords we need
# to initialize a UrlSeed object with the page_url as the "url" field.
if not keyword_texts and page_url:
url_seed = client.get_type("UrlSeed", version="v6")
url_seed.url = page_url
# To generate keyword ideas with only a list of keywords and no page_url
# we need to initialize a KeywordSeed object and set the "keywords" field
# to be a list of strings.
if keyword_texts and not page_url:
keyword_seed = client.get_type("KeywordSeed", version="v6")
keyword_seed.keywords.extend(keyword_texts)
# To generate keyword ideas using both a list of keywords and a page_url we
# need to initialize a KeywordAndUrlSeed object, setting both the "url" and
# "keywords" fields.
if keyword_texts and page_url:
keyword_url_seed = client.get_type("KeywordAndUrlSeed", version="v6")
keyword_url_seed.url = page_url
keyword_url_seed.keywords.extend(keyword_texts)
try:
keyword_ideas = keyword_plan_idea_service.generate_keyword_ideas(
customer_id,
locations,
False,
keyword_plan_network,
language=language,
url_seed=url_seed,
keyword_seed=keyword_seed,
keyword_and_url_seed=keyword_url_seed,
)
# 空リストを用意
keyword = []
keyword_ave = []
keyword_competition_value = []
for idea in keyword_ideas:
competition_value = keyword_competition_level_enum.Name(
idea.keyword_idea_metrics.competition
)
keyword.append(idea.text)
keyword_ave.append(idea.keyword_idea_metrics.avg_monthly_searches)
keyword_competition_value.append(competition_value)
# print(
# f'Keyword idea text "{idea.text}" has '
# f'"{idea.keyword_idea_metrics.avg_monthly_searches}" '
# f'average monthly searches and "{competition_value}" '
# "competition.\n"
# )
except GoogleAdsException as ex:
print(
f'Request with ID "{ex.request_id}" failed with status '
f'"{ex.error.code().name}" and includes the following errors:'
)
for error in ex.failure.errors:
print(f'\tError with message "{error.message}".')
if error.location:
for field_path_element in error.location.field_path_elements:
print(f"\t\tOn field: {field_path_element.field_name}")
sys.exit(1)
# [END generate_keyword_ideas]
# 辞書型に変換
keyword_dict = {
'keyword': keyword,
'keyword_ave' :keyword_ave,
'keyword_competition_value' :keyword_competition_value
}
# DataFrameに変換する
df_all = make_df(keyword_dict)
print(args.keyword_texts)
# print(df_all) # ファイルに出力
df_all[:21].to_csv(f'search_{args.keyword_texts}.csv',columns=['keyword'],header=False, index=False)
df_all[:21].to_csv(f'search_{args.keyword_texts}_all.csv',header=False, index=False)
def make_df(keyword_dict):
df = pd.DataFrame(keyword_dict)
df = df.sort_values(by='keyword_ave', ascending=False).reset_index(drop=True)
df_hight = df[df['keyword_competition_value'] == 'HIGH']
df_midium = df[df['keyword_competition_value'] == 'MEDIUM']
df_low = df[df['keyword_competition_value'] == 'LOW']
df_all = pd.concat([df_low,df_midium])
return df_all
if __name__ == "__main__":
# GoogleAdsClient will read the google-ads.yaml configuration file in the
# home directory if none is specified.
google_ads_client = GoogleAdsClient.load_from_storage()
parser = argparse.ArgumentParser(
description="Generates keyword ideas from a list of seed keywords."
)
# The following argument(s) should be provided to run the example.
# parser.add_argument(
# "-c",
# "--customer_id",
# type=str,
# required=True,
# help="The Google Ads customer ID.",
# )
parser.add_argument(
"-k",
"--keyword_texts",
nargs="+",
type=str,
required=False,
default=[],
help="Space-delimited list of starter keywords",
)
# To determine the appropriate location IDs, see:
# https://developers.google.com/adwords/api/docs/appendix/geotargeting.
parser.add_argument(
"-l",
"--location_ids",
nargs="+",
type=str,
required=False,
default=_DEFAULT_LOCATION_IDS,
help="Space-delimited list of location criteria IDs",
)
# To determine the appropriate language ID, see:
# https://developers.google.com/adwords/api/docs/appendix/codes-formats#languages.
parser.add_argument(
"-i",
"--language_id",
type=str,
required=False,
default=_DEFAULT_LANGUAGE_ID,
help="The language criterion ID.",
)
# Optional: Specify a URL string related to your business to generate ideas.
parser.add_argument(
"-p",
"--page_url",
type=str,
required=False,
help="A URL string related to your business",
)
args = parser.parse_args()
main(
google_ads_client,
# args.customer_id,
customer_id,
args.location_ids,
args.language_id,
args.keyword_texts,
# ['火星'],
args.page_url,
)まず、「customer_id = "1234253142 "」を変数に設定してコマンドプロンプトでidを打ち込まなくていいようにしました。
次に、検索の言語を日本語に変更する必要があります。
↑こちらで言語IDを調べることができ日本語は「1005」となっているので、そちらに変更します。
# https://developers.google.com/adwords/api/docs/appendix/codes-formats#languages.
_DEFAULT_LANGUAGE_ID = "1005" # language ID for Englishさらに検索する地域ですが、どうやら都道府県ごとに細かく分かれているみたいです。都道府県ごとの詳細を知りたい場合もあるかもしれませんが、日本全体の検索ボリュームを知りたいので日本全地域の合計値に変更する必要があります。
ただ、全地域を指定することができず最大で10地域だけしか調べることができません。なので、今回は人口ランキングトップ10を対象にして検索ボリュームを調べることにします。
※追々全地域調べれるようにプログラムを変更します。
都道府県ランキングトップ10
https://ja.wikipedia.org/wiki/%E9%83%BD%E9%81%93%E5%BA%9C%E7%9C%8C%E3%81%AE%E4%BA%BA%E5%8F%A3%E4%B8%80%E8%A6%A7
東京、神奈川、大阪、愛知、埼玉、千葉、兵庫、北海道、福岡、静岡
'''
ParentIDs = ["20636", "20637", "2392", "20646", "20634", "20635", "20651", "20624", "20663", "20645"]
# Location IDs are listed here: https://developers.google.com/adwords/api/docs/appendix/geotargeting
# and they can also be retrieved using the GeoTargetConstantService as shown
# here: https://developers.google.com/google-ads/api/docs/targeting/location-targeting
_DEFAULT_LOCATION_IDS = list(ParentIDs)[0:11] # location ID for New York, NYもうひとつ工夫として、検索ボリュームの競合が「低」と「中」だけを抽出するプログラムに変えています。
# 辞書型に変換
keyword_dict = {
'keyword': keyword,
'keyword_ave' :keyword_ave,
'keyword_competition_value' :keyword_competition_value
}
# DataFrameに変換する
df_all = make_df(keyword_dict)
print(args.keyword_texts)
# print(df_all) # ファイルに出力
df_all[:21].to_csv(f'search_{args.keyword_texts}.csv',columns=['keyword'],header=False, index=False)
df_all[:21].to_csv(f'search_{args.keyword_texts}_all.csv',header=False, index=False)
def make_df(keyword_dict):
df = pd.DataFrame(keyword_dict)
df = df.sort_values(by='keyword_ave', ascending=False).reset_index(drop=True)
df_hight = df[df['keyword_competition_value'] == 'HIGH']
df_midium = df[df['keyword_competition_value'] == 'MEDIUM']
df_low = df[df['keyword_competition_value'] == 'LOW']
df_all = pd.concat([df_low,df_midium])
return df_all結果はcsvファイルで出力します。
df_all[:21].to_csv(f'search_{args.keyword_texts}.csv',columns=['keyword'],header=False, index=False)
df_all[:21].to_csv(f'search_{args.keyword_texts}_all.csv',header=False, index=False)”Python”という検索ボリュームを調査
ではコマンドプロンプトで以下のコマンド実行してみましょう。
python .\generate_keyword_kamakiri.py -k 'python' > search_log.txt>search_log.txtとするとprint文の結果が「search_log」のファイルに出力されます。※文字コードの関係でエラーが出る方がいるかもしれません。その場合は「python .\generate_keyword_kamakiri.py -k 'python'」だけにしてください。
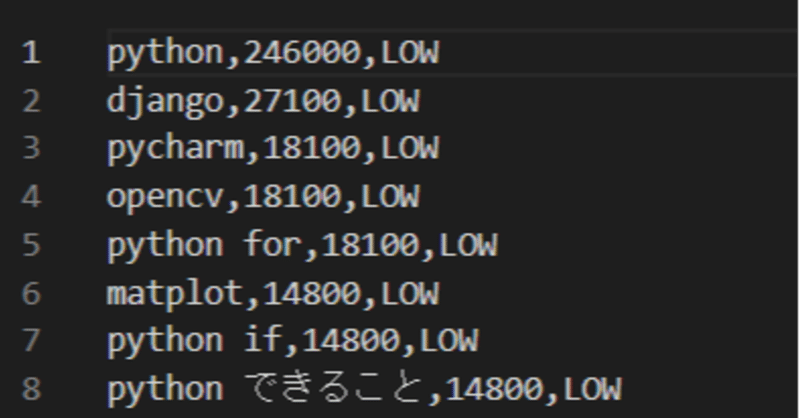
今回は「Python」で検索ボリュームを調べていました。
search_['python']_all.csvには「低(LOW)」のうち検索ボリューム上位20だけが書かれています。
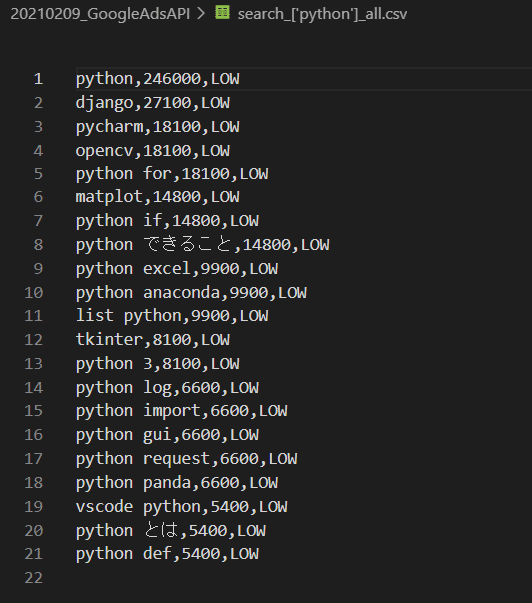
一方その単語だけを抜き取ったのがこちらです。
search_['python'].csv
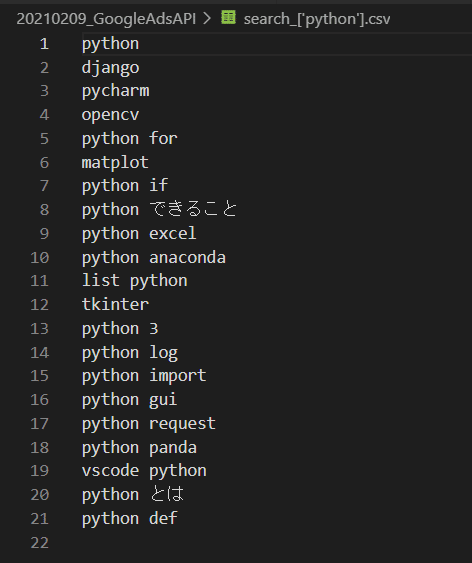
このように単語だけを抜き取っておくと、後々にスクレイピングをするための単語リストして役に立ちますよね。
まとめ
今回はGoogle検索ボリュームの自動取得をPythonを使って行いました。
コードをさらに解読して自分用にカスタマイズすると便利なプログラムが作成できるでしょう(^^♪
Twitter➡@t_kun_kamakiri
Instagram➡kamakiri1225
ブログ➡宇宙に入ったカマキリ(物理ブログ)
ココナラ➡物理の質問サポートサービス
コミュニティ➡製造業ブロガー
この記事が気に入ったらサポートをしてみませんか?