
【Python(2)】複数のGoogleキーワード検索ボリュームを自動取得しよう。

こんにちは(@t_kun_kamakiri)
前回の記事では、Googleキーワード検索ボリュームの自動取得の手順について解説を行いました。
今回は前回のコードのアップデート版です。前回紹介したコードは「ひとつのキーワード」に対して検索ボリュームを調査するという内容でしたが、今回のコードはテキストファイルに書き込んだ複数のキーワードの検索ボリュームを順に調査するというブロガーがほしがるプログラムとなっております。
前回の記事でGoogleAdsAPIの取得やアクセスキーの取得が済んでいることが前提となります。
ファイル構成
generate_keyword.py
geotargets-2020-11-18.csv
main.py
post.py
検索キーワードリスト.txt
使用しているPythonとライブラリのバージョンも記載しておきます。
Python 3.8.5
google-ads==8.2.0
numpy==1.19.5
pandas==1.1.5
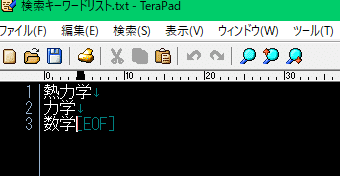
1.「検索キーワードリスト.txt」に調査したい単語を並べる
検索キーワードを手テキストファイルに書きます。
今回調査するキーワードは「数学、熱力学、力学」とします。
検索キーワードリスト.txt
キーワードボリュームとデータフレームを作成するモジュールを用意します。
generate_keyword.py
#!/usr/bin/env python
# Copyright 2019 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""This example generates keyword ideas from a list of seed keywords."""
import sys
from google.ads.google_ads.client import GoogleAdsClient
from google.ads.google_ads.errors import GoogleAdsException
import os # add
import pandas as pd #add
class KeywordVolume:
def __init__(self,
client, customer_id, location_ids,
language_id, keyword_texts, page_url):
print(keyword_texts)
self.client = client
self.customer_id = customer_id
self.location_ids = location_ids
self.language_id = language_id
self.keyword_texts = keyword_texts
self.page_url = page_url
# [START generate_keyword_ideas]
def generate_keyword(self):
keyword_plan_idea_service = self.client.get_service(
"KeywordPlanIdeaService", version="v6"
)
keyword_competition_level_enum = self.client.get_type(
"KeywordPlanCompetitionLevelEnum", version="v6"
).KeywordPlanCompetitionLevel
keyword_plan_network = self.client.get_type(
"KeywordPlanNetworkEnum", version="v6"
).GOOGLE_SEARCH_AND_PARTNERS
gtc_service = self.client.get_service("GeoTargetConstantService", version="v6")
locations = [
gtc_service.geo_target_constant_path(location_id)
for location_id in self.location_ids
]
language = self.client.get_service(
"LanguageConstantService", version="v6"
).language_constant_path(self.language_id)
# Only one of these values will be passed to the KeywordPlanIdeaService
# depending on whether keywords, a page_url or both were given.
url_seed = None
keyword_seed = None
keyword_url_seed = None
# Either keywords or a page_url are required to generate keyword ideas
# so this raises an error if neither are provided.
if not (self.keyword_texts or self.page_url):
raise ValueError(
"At least one of keywords or page URL is required, "
"but neither was specified."
)
# To generate keyword ideas with only a page_url and no keywords we need
# to initialize a UrlSeed object with the page_url as the "url" field.
if not self.keyword_texts and self.page_url:
url_seed = client.get_type("UrlSeed", version="v6")
url_seed.url = self.page_url
# To generate keyword ideas with only a list of keywords and no page_url
# we need to initialize a KeywordSeed object and set the "keywords" field
# to be a list of strings.
if self.keyword_texts and not self.page_url:
keyword_seed = self.client.get_type("KeywordSeed", version="v6")
keyword_seed.keywords.extend(self.keyword_texts)
# To generate keyword ideas using both a list of keywords and a page_url we
# need to initialize a KeywordAndUrlSeed object, setting both the "url" and
# "keywords" fields.
if self.keyword_texts and self.page_url:
keyword_url_seed = client.get_type("KeywordAndUrlSeed", version="v6")
keyword_url_seed.url = self.page_url
keyword_url_seed.keywords.extend(self.keyword_texts)
try:
keyword_ideas = keyword_plan_idea_service.generate_keyword_ideas(
self.customer_id,
locations,
False,
keyword_plan_network,
language=language,
url_seed=url_seed,
keyword_seed=keyword_seed,
keyword_and_url_seed=keyword_url_seed,
)
# 空リストを用意
keyword = []
keyword_ave = []
keyword_competition_value = []
for idea in keyword_ideas:
competition_value = keyword_competition_level_enum.Name(
idea.keyword_idea_metrics.competition
)
keyword.append(idea.text)
keyword_ave.append(idea.keyword_idea_metrics.avg_monthly_searches)
keyword_competition_value.append(competition_value)
# print(
# f'Keyword idea text "{idea.text}" has '
# f'"{idea.keyword_idea_metrics.avg_monthly_searches}" '
# f'average monthly searches and "{competition_value}" '
# "competition.\n"
# )
except GoogleAdsException as ex:
print(
f'Request with ID "{ex.request_id}" failed with status '
f'"{ex.error.code().name}" and includes the following errors:'
)
for error in ex.failure.errors:
print(f'\tError with message "{error.message}".')
if error.location:
for field_path_element in error.location.field_path_elements:
print(f"\t\tOn field: {field_path_element.field_name}")
sys.exit(1)
# [END generate_keyword_ideas]
# 辞書型に変換
keyword_dict = {
'keyword': keyword,
'volume' :keyword_ave,
'keyword_competition' :keyword_competition_value
}
# DataFrameに変換する
df_all = self.make_df(keyword_dict)
# print(df_all) # ファイルに出力
return df_all
def make_df(self,keyword_dict):
df = pd.DataFrame(keyword_dict)
df = df.sort_values(by='volume', ascending=False).reset_index(drop=True)
df_hight = df[df['keyword_competition'] == 'HIGH']
df_midium = df[df['keyword_competition'] == 'MEDIUM']
df_low = df[df['keyword_competition'] == 'LOW']
df_all = pd.concat([df_low,df_midium]).reset_index(drop=True)
return df_allこちらのファイルをモジュールとしてメインファイルから呼び出すようにします。
main.py
from generate_keyword import KeywordVolume
from google.ads.google_ads.client import GoogleAdsClient
from google.ads.google_ads.errors import GoogleAdsException
import argparse
import pandas as pd
import os
from time import sleep
# データフレームごとのキーワードの存在判定、キーワードがない場合はvolume = 0
def search_key_volume(df, search_key):
dfx = df[df['keyword'].isin([search_key])]
if len(dfx):
index = dfx.index[0]
else:
index = 0
dfx.at[index, 'volume'] = 0
return index, dfx
def keyword_volueme_JP(search_keyword):
# customer_id
customer_id = "53483*****" #自身のキーワードプランナーのid(テストアカウントを使用すること)
# A language criterion ID. For example, specify 1000 for English. For more
# information on determining this value, see the below link:
# https://developers.google.com/adwords/api/docs/appendix/codes-formats#languages.
_DEFAULT_LANGUAGE_ID = "1005" # language ID for English
df_ParentIDs = pd.read_csv('geotargets-2020-11-18.csv', encoding="cp932")
df_JP = df_ParentIDs[df_ParentIDs['Country Code']=='JP']
ParentIDs = df_JP['Parent ID'].unique().astype(int)
ParentIDs_list = ParentIDs[:-1]
ParentIDs_lists = []
for i in range(round(len(ParentIDs_list)/10)):
ParentIDs_lists.append(ParentIDs_list[10*i:10*(i+1)])
df_volume = pd.DataFrame()
for i in range(len(ParentIDs_lists)):
ParentIDs = ParentIDs_lists[i]
# Location IDs are listed here: https://developers.google.com/adwords/api/docs/appendix/geotargeting
# and they can also be retrieved using the GeoTargetConstantService as shown
# here: https://developers.google.com/google-ads/api/docs/targeting/location-targeting
_DEFAULT_LOCATION_IDS = ParentIDs # location ID for New York, NY
# GoogleAdsClient will read the google-ads.yaml configuration file in the
# home directory if none is specified.
google_ads_client = GoogleAdsClient.load_from_storage()
parser = argparse.ArgumentParser(
description="Generates keyword ideas from a list of seed keywords."
)
# The following argument(s) should be provided to run the example.
# parser.add_argument(
# "-c",
# "--customer_id",
# type=str,
# required=True,
# help="The Google Ads customer ID.",
# )
parser.add_argument(
"-k",
"--keyword_texts",
nargs="+",
type=str,
required=False,
default=[],
help="Space-delimited list of starter keywords",
)
# To determine the appropriate location IDs, see:
# https://developers.google.com/adwords/api/docs/appendix/geotargeting.
parser.add_argument(
"-l",
"--location_ids",
nargs="+",
type=str,
required=False,
default=_DEFAULT_LOCATION_IDS,
help="Space-delimited list of location criteria IDs",
)
# To determine the appropriate language ID, see:
# https://developers.google.com/adwords/api/docs/appendix/codes-formats#languages.
parser.add_argument(
"-i",
"--language_id",
type=str,
required=False,
default=_DEFAULT_LANGUAGE_ID,
help="The language criterion ID.",
)
# Optional: Specify a URL string related to your business to generate ideas.
parser.add_argument(
"-p",
"--page_url",
type=str,
required=False,
help="A URL string related to your business",
)
args = parser.parse_args()
keyword_texts = search_keyword
# KeywordVolumeインスタンス化
keyword = KeywordVolume(
google_ads_client,
customer_id,
args.location_ids,
args.language_id,
keyword_texts,
args.page_url,
)
# キーワード検索ボリュームのデータフレーム
df_all = keyword.generate_keyword()
df_all = df_all[:100]
for index in range(df_all.shape[0]):
search_key = df_all['keyword'][index]
# データフレームごとのキーワードの存在判定、キーワードがない場合はvolume = 0
index_, dfx_ = search_key_volume(df_all, search_key)
# df0にvolumeの合計数値を計算
df_all['volume'][index] = df_all['volume'][index] + dfx_.at[index_, 'volume']
sleep(1)
# csvファイルの保存先
path = os.getcwd()
csv_dir = rf'{path}\volume_csv'
if not os.path.isdir(csv_dir):
os.mkdir(csv_dir)
# csvファイルの保存
df_all.to_csv(rf'{csv_dir}\search_{keyword_texts}.csv',columns=['keyword'],header=False, index=False)
df_all.to_csv(rf'{csv_dir}\search_{keyword_texts}_all.csv',header=False, index=False)
if __name__ == '__main__':
# 検索キーワードリストの読み込み
with open('検索キーワードリスト.txt', encoding='utf-8') as f:
keyword_list = [s.rstrip() for s in f.readlines()]
print(keyword_list)
for search_keyword in keyword_list:
keyword_volueme_JP([search_keyword]) #キーワードはリストにする
sleep(1)※最大10件の地域の検索キーワードの合計値が取得できるが、日本の全体の地域は48件になるため「for i in range(len(ParentIDs_lists)):」で5回ループを回しています。
※5回に分けて取得した検索ボリュームの合計値を「for index in range(df_all.shape[0]):」のループで足し合わせています。
※面倒なのが5回に分けて取得した検索ボリュームの順番がバラバラなので各キーワードに対応したボリュームを足すというプログラムを「def search_key_volume(df, search_key):」を使って判定しています。
メインファイルがこんなに長くなってしまった('ω')
ちゃんと構成考えなきゃ_(._.)_
2.コマンドプロンプトで`python main.py`と打ち計算実行
これで準備ができたのでコマンドプロンプトでファイルを実行してみましょう。
python main.py
こんな感じで計算が進みます。
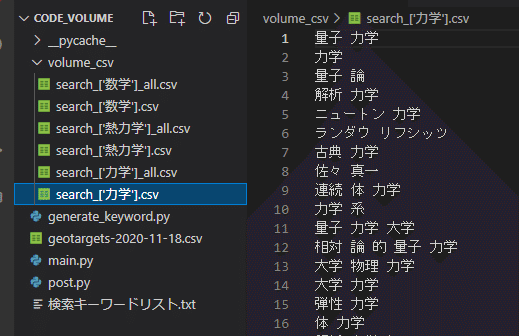
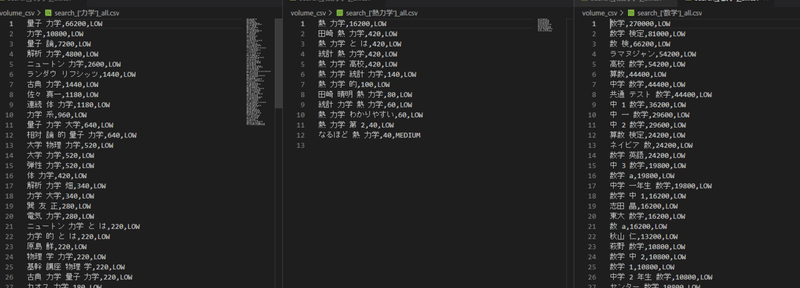
3.「volume_csv」フォルダが作成され単語ごとにcsvファイルが出力。
計算が終わると「volume_csv」フォルダにcsvファイルが出力されます。
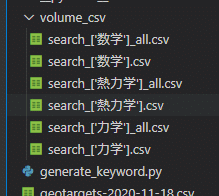
_all.csvというファイルが検索ボリュームの結果が書かれたファイルです。
※csvファイルをExcelで開くと文字コードの関係でエラーが出るのでテキストファイルで開いてください。
例)search_['力学']_all.csv
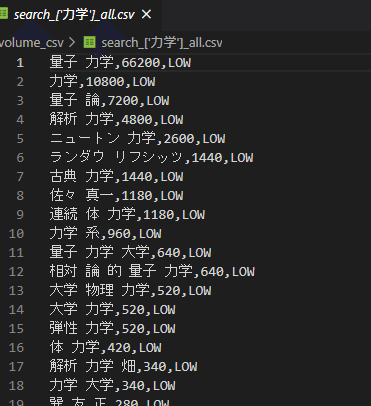
例)search_['力学'].csv
こちらは単語だけを抜き取ったファイルです。
※スクレイピングに使用するファイルです(別途紹介)。
オプションとして検索キーワードボリューム上位に並び変えるプログラムも作成しました。
4.コマンドプロンプトで`python post.py`と打ち計算実行
ここまでで各キーワードに対してバラバラでキーワード検索ボリュームを出すことができました。
できればどのキーワードが検索ボリュームとして上位に来ているのかが知りたいですよね。
なので各csvファイルをひとつにまとめてソートするプログラム作成しました。
post.py
import pandas as pd
import glob
import os
csv_list = glob.glob(r'volume_csv\*_all.csv')
df = pd.DataFrame()
for csv_file in csv_list:
df_ = pd.read_csv(csv_file, names=["keyword", "volume", "keyword_competition"])
df = pd.concat([df,df_], axis=0)
df_sort = df.sort_values('volume', ascending=False)
# csvファイルの保存先
path = os.getcwd()
csv_dir = rf'{path}\volume_csv'
df_sort.to_csv(rf'{csv_dir}\search_sort.csv',header=False, index=False)こちらを実行します。
python post.py「volume_csv」にsearch_sort.csvが出力されます。
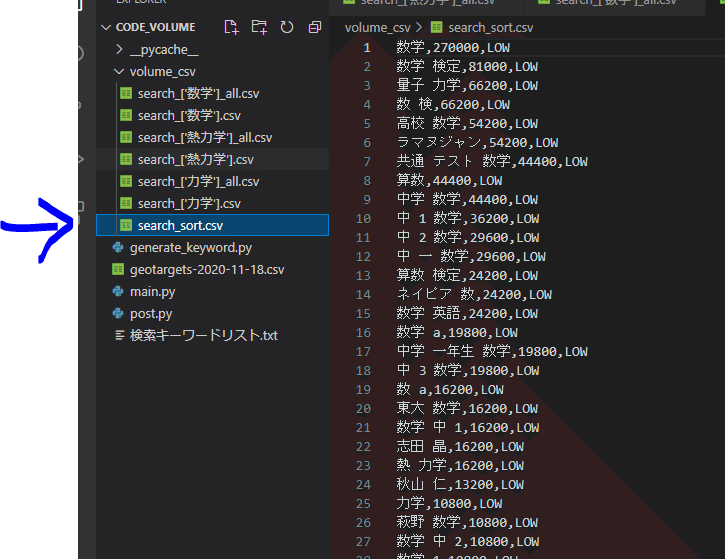
5.「volume_csv」にsearch_sort.csvが出力される。テキストで閲覧。
では今回調査した「数学、熱力学、力学」に関する検索ボリュームボリュームの全体順位を見てみましょう。
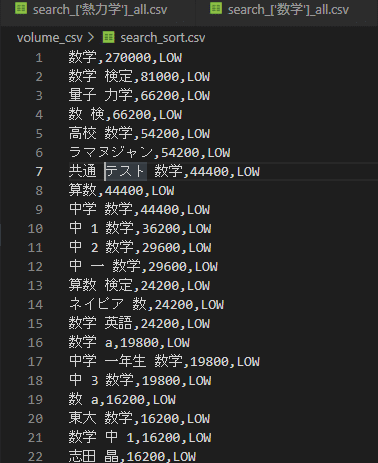
このようになりました(^^)/
こーしさんにも試しに使ってもらいました。
カマキリさんお手製のプログラムを使って、検索ボリュームを #python で調べてみました。
— こーし⚡️ケミカルエンジニア (@mimikousi) April 5, 2021
教科書の目次を.txtに貼り付け、pythonを実行すると、こんな感じの結果が出力されました。
ちなみに、統計学実践ワークブック(準1級)の目次です。
最高のツールを手に入れました😊 https://t.co/9mwOj61brx pic.twitter.com/WXvUR17HLE
前回の記事を読んで自身のキーワードプランナーのidとアクセスキーでお試しください。
Pythonはこちらの参考書を辞書代わりに使っています。
Twitter➡@t_kun_kamakiri
Instagram➡kamakiri1225
ブログ➡宇宙に入ったカマキリ(物理ブログ)
ココナラ➡物理の質問サポートサービス
コミュニティ➡製造業ブロガー
この記事が気に入ったらサポートをしてみませんか?