機械学習の評価指標(まとめ)

Kaggleで勝つデータ分析の第二章評価指標の分野が終了したので簡単にまとめます。ここら辺の分野は実際にモデルを動かした方が理解しやすいので簡単にデータを作ってやっていきます。
まず評価指標とは何かについて紹介します。評価指標とは学習させたモデルの性能やその予測値の良し悪しを測る指標のことです。
・回帰問題における評価指標
まず回帰における評価指標を紹介します。
・RMSE
・RMSLE
・MAE
・決定係数
では少し掘り下げていきます。
・RMSE(Root Mean Squared Error, 平均平方二乗誤差)
回帰問題で最も代表的な評価指標です。観測値と予測値との距離(つまり誤差)の二乗を足したものです。観測値と予測値の差が大きいとRMSEの値が大きくなります。仮に外れ値があるとRMSEは著しく大きくなるので、外れ値の影響受けやすくなります。
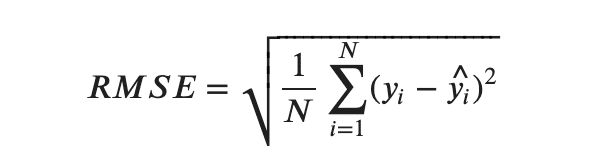
・RMSLE(Root Mean Squared Logarithmic Error)
観測値と予測値の対数をそれぞれとった後の差の二乗平均の平方根によって計算される評価指標です。値の範囲が大きな場合やで賜与されることが多いです。RMSEとRMSLEどちらも似ていますが各々の違いは後ほど紹介します。
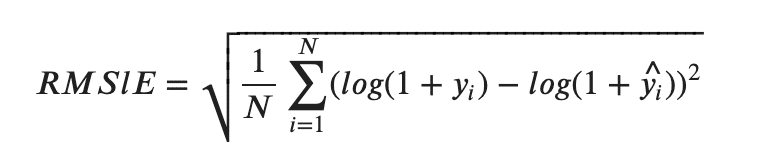
・MAE(Mean Absolute Error, 平均絶対誤差)
MAEは観測値と予測値の差の絶対値の平均によって計算される評価指標です。誤差を二乗しないので外れ値の影響を受けにくいと言うメリットがあります。
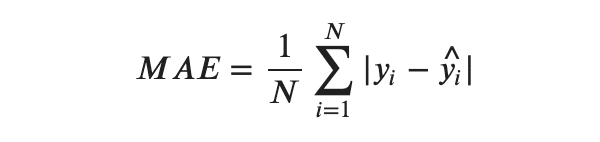
・R^2(決定係数)
この指標は0から1を取り、1に近づくほど精度の高い予測ができます。(0から1とは限らないようで実際にマイナスにもなったりします。)
この指標を最大化することはRMSEを最小化することと同じ意味です。
・二値分類における評価指標
次に分類における指標を紹介しますが、分類モデル(ニ値分類)には評価指標の分け方が二つあります。
・混合行列を元にした評価指標
・確率を元にした評価指標
・混合行列を元にした評価指標
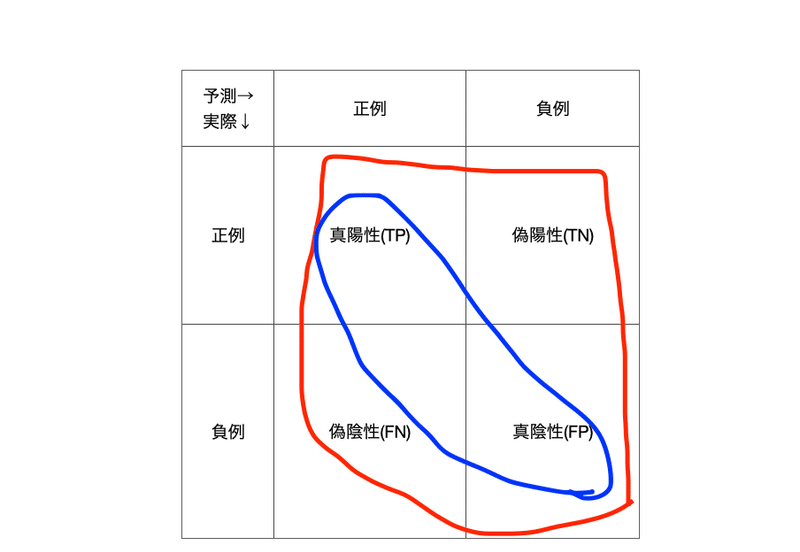
この評価指標では正例であるか負例であるかを予測値とします。例えば医療の場合を例に挙げてみます。腫瘍がある場合は正例とし、腫瘍がない場合は負例とします。そうすると四つの組み合わせができると思います。
・TP(True Positive、真陽性):予測値を正例として、その予測が正しい場合
・TN(True Negative、真陰性):予測値を負例として、その予測が正しい場合
・FP(False Positive、偽陽性):予測値を正例として、その予測が誤り場合
・FN(False Negative、偽陰性):予測値を負例として、その予測が誤り場合
例えばTPの場合は予測では陽性と判断されて、実際に腫瘍があった場合を指します。一方FPは予測ではあると出たが、実際に腫瘍がなかった場合を指します。これを次の表にしたものを混同行列と言います。
またこれらのTPやFPなどを使用して様々な指標を求めることができます。次にそれらを紹介していきます。
・正答率と誤答率(accuracyとerror)
上記のような式を使用して予測の正しい割合を求めることができます。
図を元に考えると次のようになります。赤が分母、青が分子となります。
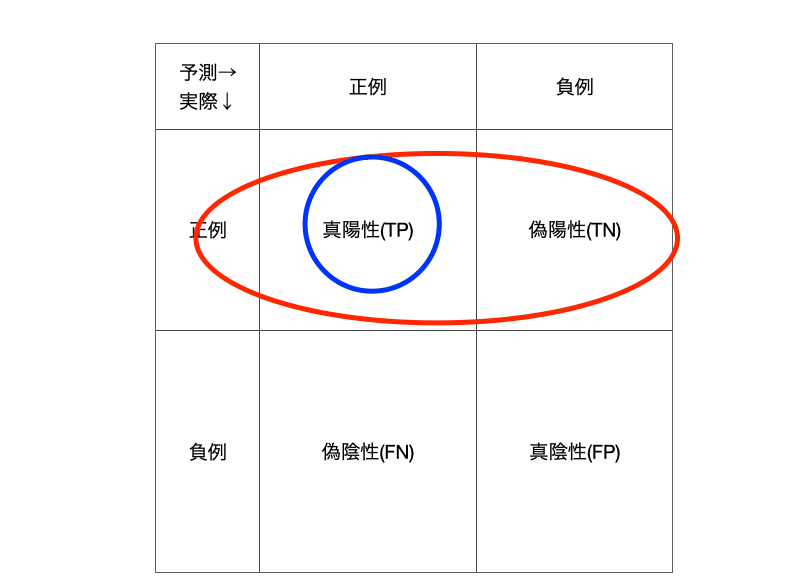
・適合率
正例と予測したもののうち真の値も正例の割合のことです。例えば陽性と予測したデータのうち、本当に陽性である割合を求める際に使用します。
図で表現すると次のようになります。
・再現率
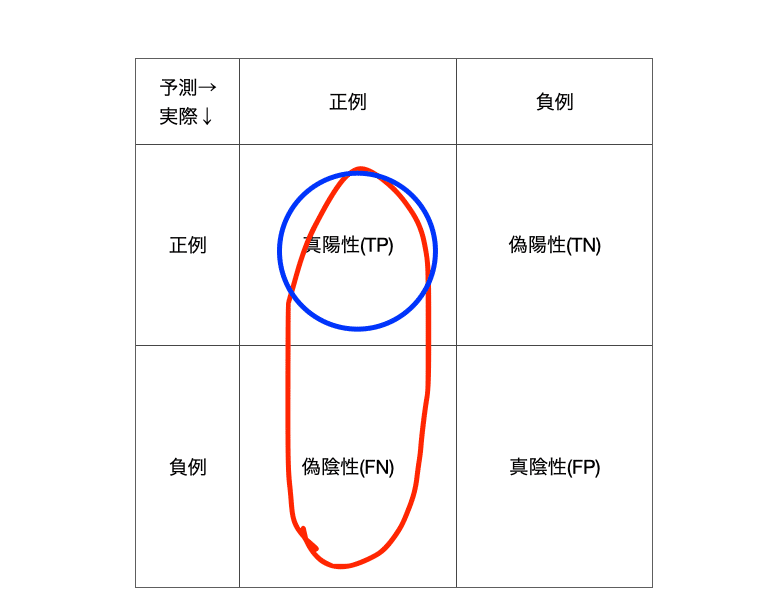
真の値が正例のもののうちどの程度を正例の予測として含めることができているかの割合のことです。例えば実際に陽性と判断されたデータのうち予測・実際とも陽性である割合を求めたい際に使用します。
図で表現すると次のようになります。
・F値
先ほどの適合率と再現率は互いにトレードオフの関係になっています。どちらかを高くした場合、一方は小さくなります。ここで登場するのがF値と言うものです。これは適合率と再現率の調和平均と言うものです。調和平均とはなんぞやと思いますが。これは観測値の逆数の平均と言うことです。主に平均時速を求める際に使用されることが多いです。適合率と再現率のバランスを取りたい際に使用します。
・MCC(Matthews Correlation Coefficient, マシューズ相関係数)
次に紹介するのがMCCと言う指標です。この指標は不均衡データに対して使用されることが多いです。
・確率を元にした評価指標
次に紹介していくのが二値分類におけるもう一つのケースである、正例である確率を予測値する際の評価指標について紹介していきます。
・logloss
分類問題で代表的な指標であり、又の名をエントロピーと呼びます。
・AUC(Area Under The ROC Curve)
AUCとは分類モデルの良し悪しを判断する指標です。AUCは0から1を取り、1だとそのモデルは良いということになります。例を挙げると説明変数がAの場合のAUCが0.80で説明変数Bを使ったモデルのAUCが0.4だった場合どちらを使用した方が良いでしょう。もちろんAの説明変数ですね。回帰モデルの決定係数と似ていますね。このAUCはROC曲線で囲まれた面積を計算することで値を求めることができます。
では先にROC曲線について説明します。ROC曲線とはReceiver operating characteristic curveといい、予測値を正例とする閾値を1から0に動かし、その時の偽陽性率・真陽性率(x, y)としてプロットすることで描くことができる。
ちょっと自分は理解が難しかったのでとても分かりやすかった動画を載せておきます。
この方の動画を参考に説明していきます。
どうやらロジスティック回帰を使用してみると理解しやすいらしいので使ってみます。例えば次のように腫瘍のサイズによってその腫瘍が悪性か良性か判断した図を用意します。これにロジスティック回帰をプロットしたら、次に閾値を決めます。今回は閾値を0.5としてもし閾値が0.5よりも大きいなら、腫瘍が悪性としそれ以下なら良性とします。
この閾値を境に真陽性率と偽陽性率を求めていきます。これを閾値を何回かずらしてその結果をグラフにプロットしていくとROC曲線が完成します。今回はデータが少ないので曲線にはなりませんが、増やせばイメージ図のような曲線になります。そして最後にこのROC曲線とx軸(偽陽性率)、y軸(真陽性率)で囲まれた面積を求めればAUCの値が求まります。これがAUCです。
・まとめ
最後に簡単にまとめます。
・評価指標とはモデルの良し悪しを測定する指標
・回帰問題と分類問題にそれぞれ指標があり、分類モデルには混同行列と確率を元にした指標がある。
この記事が気に入ったらサポートをしてみませんか?