
オープンデータについて考えてみたけど、結局データベース化しか思いつかなかった

先日、#こんな社会だったらいいなのコンテストでオープンデータについて語ってみました。
夜中の勢いで書いてみた翌日に見返してみたところ、完全に他責状態で投げっぱなしでしたので、今回は具体的にどうなっていればオープンデータが利活用されるのか、具体策を提示するお話になります。
書きっぱなしで苦言のみ言うだけだとなんだこいつだし、そもそも何も解決しないし、頑張ってリリースしている方々にも申し訳ない。
— Kazuya Araki (@kazuya_araki_jp) September 12, 2019
オープンデータのアイデア編を今晩書こう。 https://t.co/c4ZVq0w1SD
はじめに
最終ゴールは、データクレンジングが限りなく0となる状態です。データアナリストがデータ分析する工数の9割がデータクレンジングといっても過言ではないので、データに振り回されず、きれいな状態で提供されるのが理想です。
前回の再掲ですが、きれいなデータとは以下の状態です。
RFCに準拠したCSV
欠損項目がない(カラムデータが全てNULLではない)
時系列データに抜け漏れや尺度の違いがない
データ齟齬がない
そのためは少なくない工数とエンジニアリソースを、官公庁の場合は追加でシステムエンジニアやITコンサルタントのコストを投下することになります。完全に理想論ですので、この状態に到達する難易度は高いです。
やることの前にやめること
アイデアの前に、今あるものでやめないといけないものがいくつかあります。
事実、データ活用を阻害していることだらけなので、リストとしてあげてみました。
先に挙げたきれいなデータを目指すよりも幾分難易度は易しいものもあるので、可能な限り実践しておくことを勧めます。
.xls形式のExcelファイル
世はまさにビッグデータの時代。
1日どころかものの1時間で1億レコード、1TBのデータサイズを捌く要件がある時代です。
このような時代に、65536行、256列しか対応していないExcel 2003のファイル(.xls形式)を一体誰が求めているのでしょうか?
そもそも、Office 2003のサポートはすでに終了しています。サポート切れているロストテクノロジーの製品にまで忖度する必要はないと思います。)
仮に、Excel 2003のファイルをサポートするとしても、65536行が限界です。
さらに言うと、Excelは有償のツールです。
企業や省庁でOffice製品を導入しているのであれば課題はありませんが、ことオープンデータで括った場合、Excelを利用できないユーザーは多く存在します。そのため、オープンデータに限って言えば、Excelファイルはユーザーフレンドリーなデータではありません。。
私はメインで利用しているOSはMacOSです。MacユーザーはExcelを使用せず、Numbers、Google Sheetといった無料の表計算ソフトを利用することが多いです。
クロス表フォーマット
オープンデータをExcelで提供している際にありがちなケースが、クロス集計済みの表形式となっているものがあります。残念ながら加工済みのデータとしては最悪の部類に入る事例です。
例えばこのようなデータ。
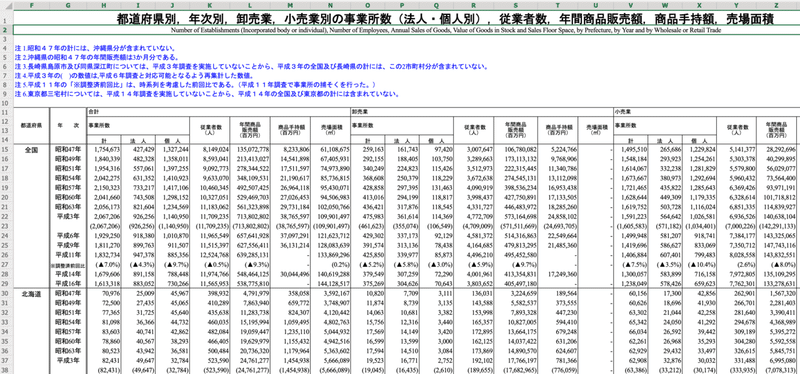
問題点
クロス表として完結したデータのため、このファイルをもとにグラフを作成したり、個別に集計することが困難である・
メタデータ(タイトル、ヘッダー、フッター、注釈)が情報として含まれているため、BIツールからファイルを読み込めない(あるいは特別な設定が必要)。
行ヘッダー、列ヘッダーともにセル結合しているため、行ごとにデータ抽出した際にヘッダー情報が欠損する。
と問題点を挙げるとキリがないので、ここまでにしておきます。
オープンデータは利活用者にとって都合の良いテーブル形式で提供していただけることを祈っています。
RFCに準拠していないCSV
個人的にはExcelファイルよりも怒り心頭な事案として、CSVの件を挙げます。
難しいことは言いません。オープンデータ提供者はまずRFC4180に記載の内容を読んで理解してください。
もう一度言います。オープンデータ提供者はまずRFC4180に記載の内容を読んで理解した上でCSVを提供してください。
e.g. bad practice
データの区切りがtab。CSVは”Comma Separated Value(s)”の略です!!
メタデータ(タイトル、ヘッダー、フッター、注釈など)が情報として含まれている。Excel以外のツールでデータ読み込みすることができません。
特殊文字の処理をしていない。データ読み込みエラーが発生してとても困ります。
改行を含むデータをダブルクォーテーションなどの文字で括っていない。
オープンデータとして正しいCSVフォーマットでファイルが提供できないならば、CSVの提供はやめてください。はっきり言いますがとても迷惑です。
データアナリスト、データエンジニアはこうしたおかしなデータに立ち向かい、無駄な時間を費やす羽目になります。間違ったCSVフォーマットは彼らの貴重な時間を奪います。
2023年9月26日追記: 文字コード
都知事杯オープンデータ・ハッカソンの参加者のお手伝いをしていました。
#都知事杯オープンデータハッカソン にてコミュニティの力を示したいと考えています!Tableauコミュニティの力をアピールしたいと考えておりますのでぜひみなさんのお力をお貸しください!東京都のオープンデータを可視化し、#オープンデータスゴイ をつけて発信いただきたいです🙏 https://t.co/KZUaYTSxz4
— Yuta Sakai(さかぴー) (@unbosoms) September 24, 2023
とあるデータを年度またぎでマージするためにPythonでコーディングしている際に事件がおきました。
> 令和4年度 都立文化施設事業一覧
— 𝙆𝙖𝙯𝙪𝙮𝙖 𝘼𝙧𝙖𝙠𝙞|荒木 和也 | 🫧🖼📊📈🥠🗾 (@kazuya_araki_jp) September 25, 2023
UTF-8 with BOMhttps://t.co/6IZbgq3IxX
> 令和5年度 都立文化施設事業一覧
Shift-JIShttps://t.co/KfUz2lOimK
ふざけてやがる👹 #TokyoOpenData
WindowsとMacOS間でファイルをやり取りする際に文字化けするという昔ながらの古典的な事象はあるのですが、オープンデータで文字コードが異なる事案は初めての体験でした。
正直、OS互換で生じる文字コード差分は諦めている慣れているので、絶対にUTF-8でファイルを寄越せ!とは言いません。
ですが、同じカラム構造を持つデータに対してファイルごとに異なる文字コードを提供するのはレギュレーション違反甚だしい行為です。絶対に避けていただきたいです。
2023年9月28日追記: エンティティフォーマットエラー
上記の続編です。
エンティティとは何か?については別記事を書く予定なのでここでは割愛させていただきます。
まずはこちらをご覧ください。

赤線の箇所は緯度を示すデータになりますが、最後の文字がカンマになっています。
このCSVをGoogle Sheetsで開いてみましょう。
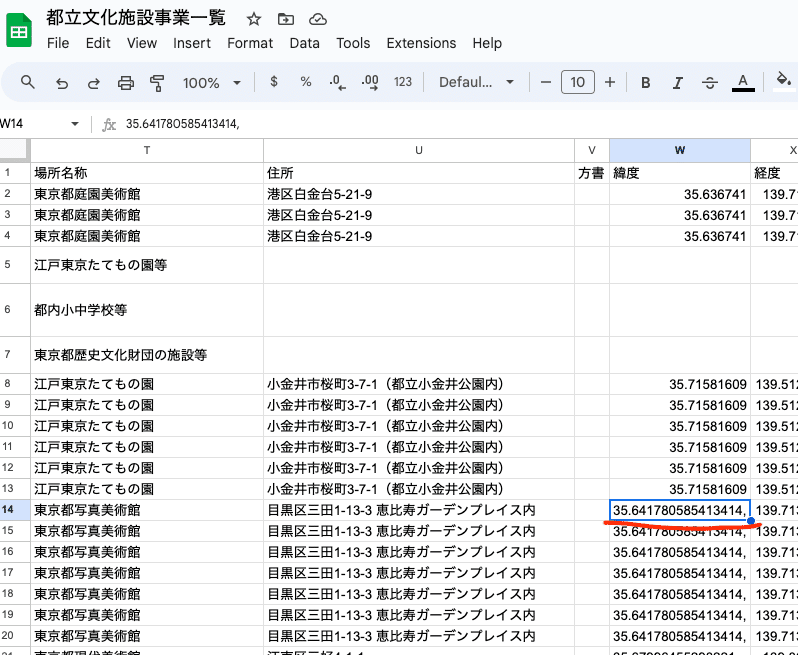
この状態だと何が発生するかと言いますと、W列のデータが緯度として認識しないという事態に陥ることになります。
実際、上記のGoogle Sheetsでも、元のCSVでも良いのでBIツールで読み込むと、
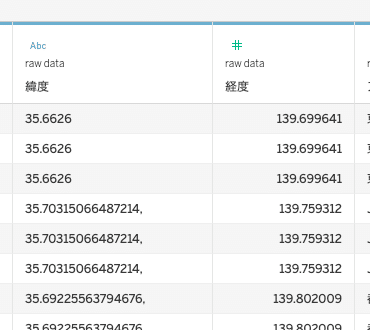

と、このように本来数値として取り扱わないといけない緯度のデータが文字列として認識されてしまうという罠に陥ります。
地理情報というエンティティである緯度は数値で取り扱わないといけませんが、こうした少しのミスで大きなエラーとなります。
今回のケースでは100数行程度のレコード数でしたから目視確認でこのバグを見つけることができましたが、実業務で数億単位のレコード数を目視確認で、と言われたらと思うと恐ろしいです。
閑話休題: データベース化しよう、いやデータベース化しろ
ここからが具体的な提言です。
タイトルで完全にネタバレしていますがずばり、オープンデータのデータベース化(パブリックデータ化)を提言します。
どういうことだってばよ?
例えば、e-StatデータをGoogle BigQueryに移行する。以下の画像は、bigquery-public-dataというプロジェクトにあるNew Yorkにあるシティバイク置き場のデータ(だそうです)。
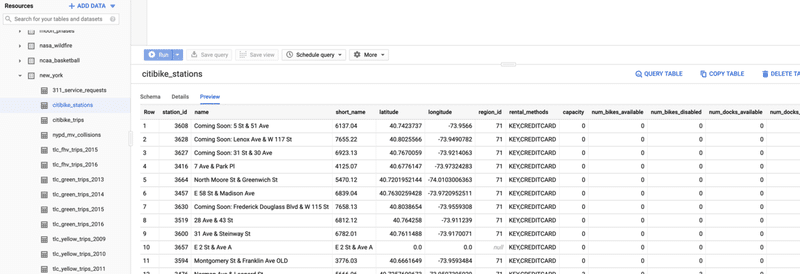
仮に、BigQueryにパブリックデータとして政府のデータが提供されたら、BigQueryを利用している人々、企業すべてが恩恵を受けます。BigQueryというエコシステムの利点を最大限活用できますし、BigQuery MLなど、他のGCPサービスと連携してさらなる利活用が臨めます。
これを実現するにはコストの課題、ユーザー管理の課題が払拭できないのであくまで机上の空論ですが、もし実現できたらインパクトは大きいと考えています。
余談: APIでもいいがデータアナリスト向けではない
e-Statでも提供が進んでいるAPIですが、正直な話、データ分析には向かない提供方法かなと個人的には思います。
理由は、APIからデータを取得する技術が必ずしもデータアナリストのスキルとは限らないからです。
(尤も、Pythonゴリゴリ書いているデータアナリストに対しては釈迦に説法です。個人的観測範囲では、データアナリストがAPIを苦もなく駆使している事例はあまり聞かなくて、どちらかというとエンジニア寄りなのかなと思います。)
ちなみに、e-StatのAPIについては、以下のマニュアルがありますが、BigQuery APIのようにもう少し体系立ったマニュアル構成になっていただけると解読が楽なのですが。。。
さいごに
結局、色々考え、加筆修正してみたものの、ジャストアイデアは思いつかず。
いいわけ
昨晩書くと言ったがな、あれは嘘だ。
— Kazuya Araki (@kazuya_araki_jp) September 13, 2019
訳: アイデアmoc作ってたらいつのまにか太陽が出ていたでござる😇 https://t.co/XbxrCI88Er
2023年9月26日追記
前回書きましたが、Analytics HubやSnowflakeマーケットプレイスで日本のオープンデータを提供しませんか?
ベンダーサイドのGoogle、Snowflakeも政府と協働でオープンデータをリリースできる体制を組めたりできないのでしょうか?
新しいデータプラットフォームの未来を描くのはそう難しいものなのでしょうか?
ここから先は
¥ 100
読んでいただきましてありがとうございます。 サポート代は次回の執筆の投資に使わせていただきます。 https://twitter.com/kazuya_araki_jp https://public.tableau.com/profile/kazuya.araki#!/