クエリエディターとは?

PowerBIでレポートを作ったり、データモデルを作成するために、何らかの形で利用することになる「クエリエディター」ですが、検索エンジンなどで調べると、似たような機能が「Power Query」と表現されていたり、どこからどこまでの機能が「クエリエディター」なのかちょっとわかりづらい機能です。
今回の記事では、初心者・初級者向けに「クエリエディター」がどんな機能で、何ができるのかといったことを整理してみたいと思います。
中級者以上の方も、「クエリエディター」機能の位置づけの再確認などにご活用ください。
クエリエディターは、PowerBIの「接続・抽出」、「変換・加工」、「ロード」(ETL)機能
クエリエディターは、さまざまなデータを分析目的に応じて、取り込んで加工するための機能です。
システム的な説明を行うとすると、Power BI Desktop内に含まれるデータの接続、変換・加工、ロード(DBへの書き込み)を実行・管理するための機能モジュールといえるでしょう。
このようなデータ処理は、近年のセルフサービスBIのためだけでなく、会計や販売管理システムといった基幹系システムからデータを抽出し、必要な形に加工して、データ分析のためのデータベースであるDWH(データウェアハウス)にデータを集約するために、古くから行われてきました。
そして、基幹系システムのDBからのデータの抽出(Extract)・変換・加工(Transform)・分析用データベースへのロード(Load)の頭文字をとって、ETL処理と呼ばれ、ETL処理を簡易に作成・管理するためのツールは、ETLツールと呼ばれています。
分析用のデータベースとBIツールが別々のツールとして扱われていた、トラディッショナルな分析環境では、BIツールとETLツールも基本的には別のツールとして販売、利用や運用も別々に実施され、運用する担当者も分かれているという状況が長く続いており、いまでも大規模なデータ分析環境では、同様の運用が行われています。
しかし、近年のセルフサービスBIの流れから、分析モデルの作成・見直しとレポートやダッシュボード作成・改善のサイクルが短くなり、多種多様なデータを臨機応変に組み合わせていくニーズが高まっている現在においては、データをビジュアライズして分析するBIツールと、データを抽出加工するツールが一つのソフトウェア内に同居することが珍しくなくなり、PowerBIにおいても、Power BI Desktop内に、BIツールとETLツールの機能が含まれています。
まとめると、「クエリエディターは、Power BIの中のETL処理を実行・管理するための機能である」という理解をしていただければ、位置づけの認識としては問題ないでしょう。
ETL機能の具体的なイメージ
ここからは具体的にクエリエディターが持つ機能をETL処理の流れに沿って説明していきます。
ちなみに、Power BI Desktopのホームメニュー内では、以下のメニューがクエリエディターの関連機能です。

実際にデータの加工処理を定義するなど、詳細な設定などを行う際には、通常のPower BI Desktopの画面に加え、クエリエディター専用の管理画面が別ウィンドウとして開かれて、そちらで操作を行います。
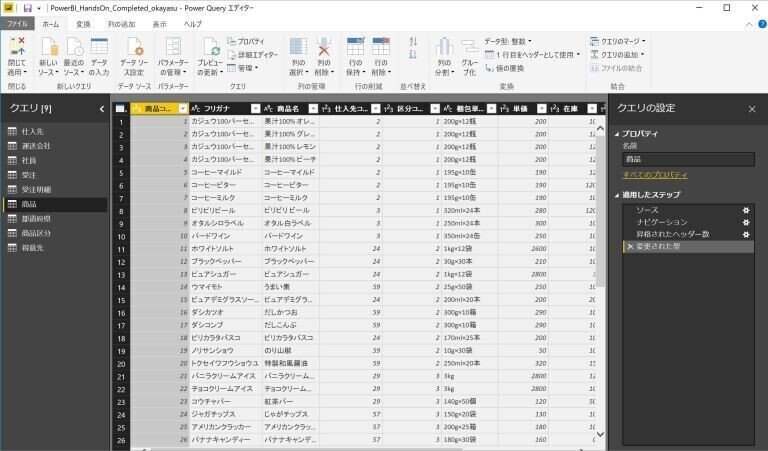
データソースの指定などは、ホームメニューからも実施できますが、クエリエディターの管理画面を立ち上げ(ホームリボンの「クエリを編集するボタン」をクリックし)て、クエリエディターの管理画面内で各種操作を実施するのがわかりやすいと思います。
1.データ抽出(Extract)機能
まずはさまざまなデータやデータベースに接続し、必要なデータを抽出する、データ抽出機能です。
PowerBIでは、基幹系システムで利用されるデータベース、予算や目標管理などで使われるExcelシート、クラウドサービスのデータベース、他のシステムからデータを抽出されたCSVファイルなど、さまざまなデータを取り込むことが可能です。
PowerBIで接続可能なデータについては、Power BI Desktop のデータ ソースを確認してください。
PowerBIがサポートしているデータやデータベースであれば、接続自体は難しくはありません。
ファイルであれば、保存場所を指定してあげればよいですし、データベースであれば接続するための情報を入力すれば簡単にデータに接続できます。
ただし、多くの企業では、セキュリティ上の問題から直接データベースにつなげることがNGであったり、顧客の個人情報などはデータを抽出することが禁止されていることがほとんどです。
そのため、基幹系システムや顧客管理システムから、活用するのが問題ない項目だけをCSVファイルや分析用のデータベースなどに書き出して、利用するということが行われています。
なお、データの抽出時には、セキュリティやなどの観点から活用するのに問題がない、データ容量や処理時間が許す限りの最大限のデータ項目を抽出しておくのがおすすめです。
データの抽出とその後の加工処理は、1から作る場合はエラーの発生が少ないですが、データの項目が増えたり、列の順番が変わったりすると、抽出処理の再定義を行わないといけなくなり、エラーも発生しやすく二度手間になってしまいます。
なんでもかんでもデータを抽出するのがよいわけではありませんが、使う可能性が高そうなデータはあらかじめ指定しておきましょう。
2.データ変換・加工(Transform)機能
次は、抽出したデータを加工する、データ変換・加工処理機能です。
変換・加工処理は、分析担当者が理解しづらい名称になっていたり、計算を行わないといけない項目がある場合や、そのままではエラーとなってしまうデータが含まれる場合などに実行する必要があります。
変換・加工とあえて分けて呼ばれることが一般的ですが、どちらがどっちの処理なのかなどは気にする必要はありません。
実際には、
・変換:Aという文字列をaに変換する、大文字を小文字に変換する、データの型を文字列から整数に変換する、列のピボットの解除(横持ちのデータを縦持ちに変換する)
・加工:単価と数量を掛けて、売上金額を計算する、先頭4文字だけを残す
・追加:同一項目の月ごとの受注明細データを結合(ユニオン)する、受注明細の商品コードを元に商品名や商品カテゴリを列として追加する、列を分割する
・削除:空白列や不要な列の削除、空白行やエラーデータ(行)の削除
などが行われます。
加工や追加は、クエリエディターではなく、DAX関数を使って実施することも可能です。
データの追加をどこで行うのかは、データの使い方などによる部分がありますので、詳しくは、当サイトのブログ記事「PowerBIでデータ項目を追加する4つの方法」を参考としてください。
なお、PowerBIでは、データを抽出した時点で、最低限の変換処理が自動で実行されます。
例えば、ExcelやCSVのデータを取り込んだ場合、
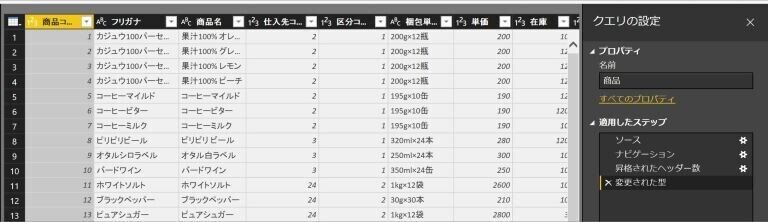
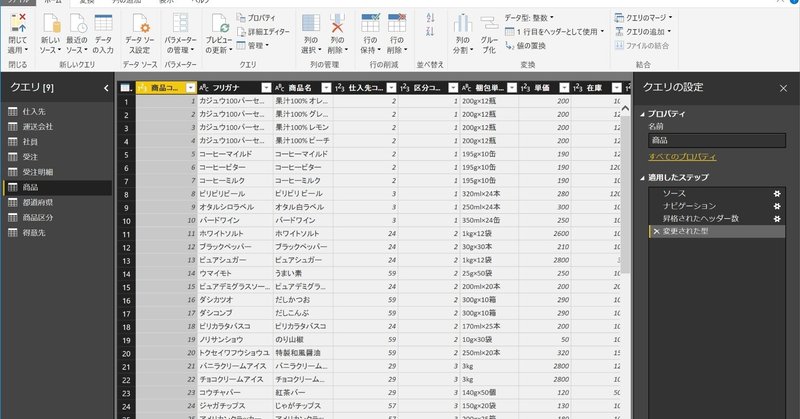
のように1行名がヘッダー(列名)として扱われたり、各列のデータの中身によってデータ型が自動で選択されます。
具体的にどのような変換・加工処理が自動で行われたかは、クエリエディター管理画面の右側「適用したステップ」で確認可能です。
上記の画面のステップ(処理)を簡単に説明すると
a.ソース:データベースやデータファイルを指定
b.ナビゲーション:データベースやファイルの中で取り込むテーブルやシートを指定
c.昇格されたヘッダー数:1行目のデータをヘッダーとして扱う
d.変換された型:データの中身によっては、整数やテキスト型などを判別してデータ型を変換
といったことが行われています。(a.b.の処理は抽出処理の時点で定義が行われています)
適用したステップは、その名の通り、処理のステップですので、各ステップを指定(クリック)すると、そのステップが実行されたところまでの時点のデータが中央に表示されます。
自動で行われた処理以外に処理(ステップ)の追加を行う場合は、列や行、セルを指定して、上部のメニューか右クリック後のメニューから実行したい処理を選択します。
例えば、商品コードの1~10だけを抽出したいといった場合は、
『該当行(ここでは商品コード)の列名の右横にある▽ボタンをクリックし、抽出したいデータだけを選択して、OKボタンをクリック』
を行うことで実行できます。
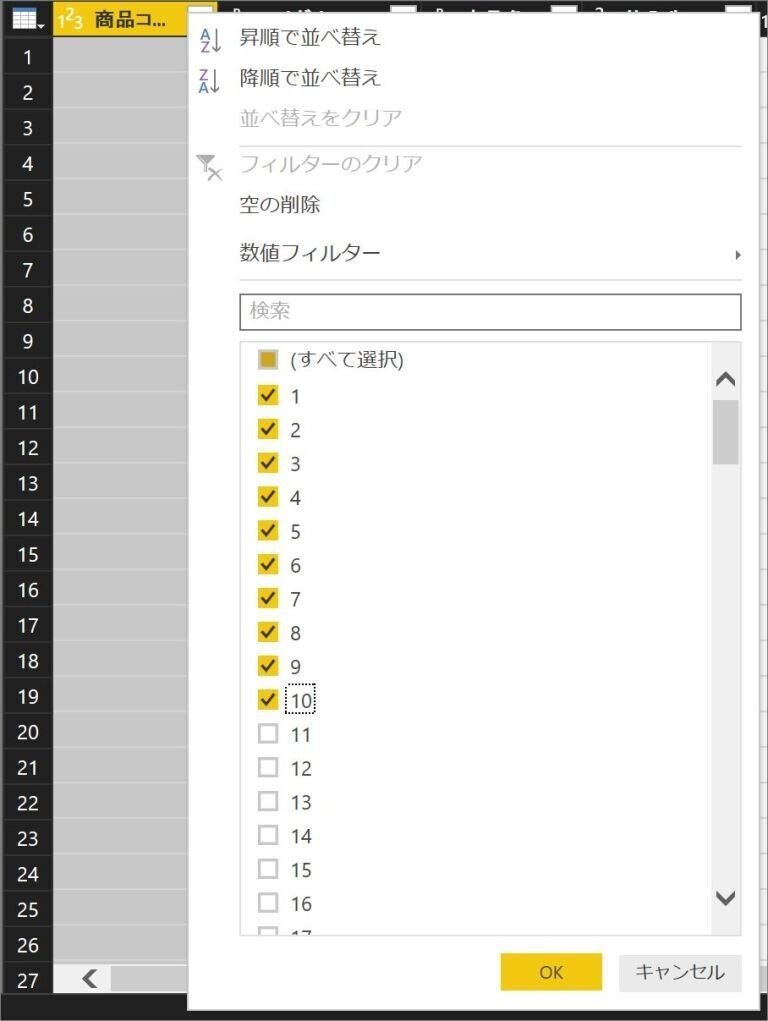
すると先ほど指定した内容に応じて、データがフィルタされます。
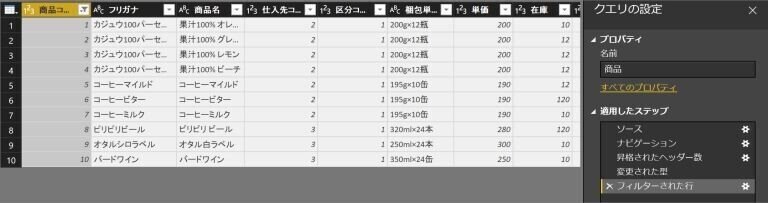
このようにクエリエディターでは、Excelに似た操作感で、さまざまな処理を簡単に定義することが可能です。
なお、定義したクエリは、各処理がステップとして保存され、一度定義したステップと順番は、毎回のデータ取り込みの際に繰り返し実行されます。
このデータ加工などの処理を行うのに気を付けなければいけないのは、処理の順番です。
例えばデータ型の変換を行う場合、テキスト型を整数型に行う処理は、データが読み込まれた後であれば、どのタイミングでもステップとして定義可能です。
しかし、整数型に変換したい列に文字列が含まれていた場合、整数型の変換に失敗し、エラーとなってしまいます。
そのため、まずは該当の列で文字列となっているデータを何らかの数字に変換するか、削除(フィルタ)したのちに、データ型の変換を行うといったステップが必要となります。
このように、どの順番でデータを処理すればのぞむ形のデータとなるのかを意識しながら設定していく必要があります。
ちなみに、GUIベースでのステップの設定は、非常にわかりやすいというメリットがある反面、同じデータを別のレポート作成時に定義するためには、また1から操作しなければならないというデメリットも存在します。
しかし、PowerBIには、同じ変換・加工処理をいちいち手動で設定しなくても、簡単にコピーする方法が存在します。
クエリエディターで定義された処理は、M言語というスクリプト言語で記述され、保存されています。
M言語として保存されたスクリプトは、表示メニューの詳細エディターを選択することで表示が可能です。
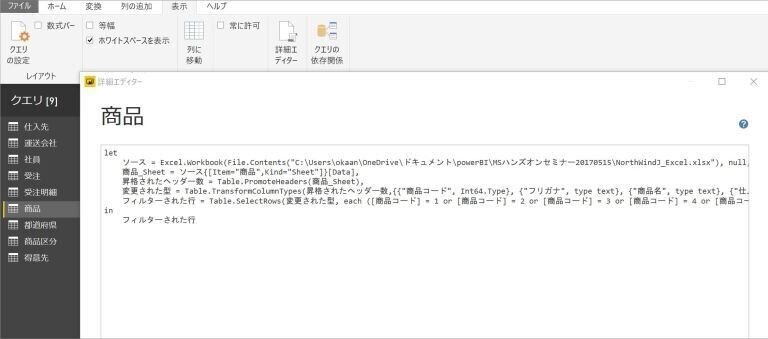
意外にシンプルな内容で記述されていることがわかるかと思いますが、この記述内容をコピーして、別のクエリの詳細エディター上に貼り付けることで、まったく同じ処理を再現することが可能となっています。
おまけ情報ですが、クエリエディターでは、まれに設定した処理がM言語の記述内容にうまく反映されないことがあります。(一度エラーが発生した場合に、修正しても、そのエラー原因となる記述が残ってしまうことがあるようです)
そのような場合は、1から処理を作成しなおすか、直接M言語の記述を修正することで、問題を回避できますので、正しい処理をしているはずなのにエラーが発生するというときには、お試しください。
3.ロード(Load)
さて、最後のロード(データの書き込み)処理です。
PowerBIでは、データベースが別にあるわけではなく、PowerBI内にデータを書き込みますので、書き込み処理について、新たな設定を行う必要はありません。
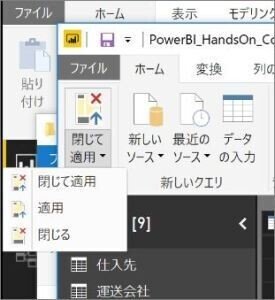
クエリエディターのメニュー「閉じて適用」をクリックすると、ここまで設定内容に従って、PowerBI内に、処理済みのデータが保存されます。(適用を選ぶとクエリエディターの管理画面を表示させたまま適用が実行されます)
なお、この時点でデータの抽出や加工処理内にエラーが含まれている場合、処理が止まり、データが取り込まれません。(適用開始前の状態にもどります)
エラーが出てしまった場合には、エラーメッセージの内容に従って、処理を定義しなおして、再度適用を実行する必要があります。
データ間のリレーションについて
なお、取り込んだ各データ間のリレーション(つながり)については、クエリエディターとは別の機能である「リレーションシップの管理」から定義する必要があります。
同じ名称で、データ型が同じであれば、自動でリレーションが構築されますので、マスタデータとトランザクションデータ間の結合があらかじめわかっている場合には、列名を合わせるなどしておくと、手間が省けます。
リレーションシップの詳細については、改めてブログ記事を投稿する予定です。
より詳しく学びたい方は
いかがでしたでしょうか?
Microsoft Power BIで使用されるクエリエディターがどのようなものかのざっくりとしたイメージはもっていただけたのではないかと思います。
もっと詳しく、体系的にPower BIを学びたいという方は、ぜひ
「Microsoft Power BI 実践ハンズオン 応用編」
の受講を検討してみてください。
この記事が気に入ったらサポートをしてみませんか?