The world is a game. ゲームから自動運転そして汎用人工知能への道

② この世界はゲームだ。
— 山本一成🚙自動運転TURINGのCEO🌕 (@issei_y) November 20, 2021
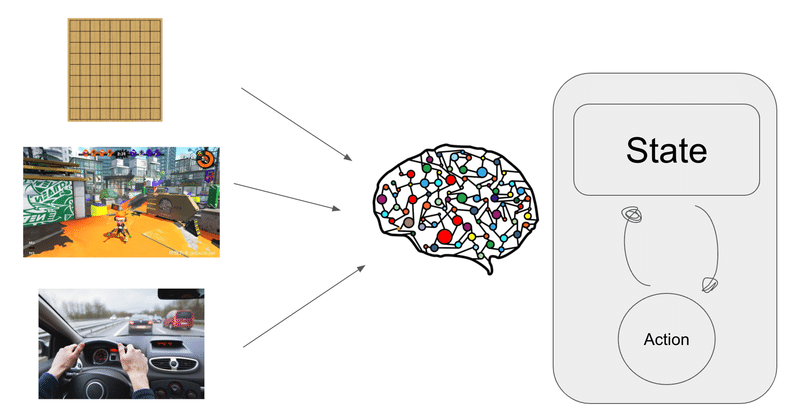
知能とは環境の中で自分がどういったアクションを取れば欲しい結果が得られる予想する機構である。運転を含む様々な問題を人間の脳は単一の機構で解決している。我々は将棋の領域で人間を上回る機構を作った。運転も類似した機構で達成可能と確信している。
知能とは予想する機能
将棋も囲碁もテレビゲームもとても楽しいものだ。その楽しさの一端は自分の行動でより良い未来を獲得するというプロセスだ。私が将棋プログラムPonanzaを作っていた時も同じようなプロセス、強化学習で評価関数を学習させていた。評価関数は盤面を入力にその勝率を推定する関数だ。
しかし単純に評価関数を強化するというプロセスでは強さに限界がある。現在もっとも強いDeep Learning系の評価関数を使っても、それだけで人間棋士を倒すのはなかなか困難であろう。そう探索も必要だ。
将棋や囲碁での探索は極めて強力だ。探索を加えるとELOレーティングが1000点以上あがる。これはA(評価関数だけ) にほぼ100%勝てるBに対してC(評価関数+探索)はほぼ100%勝てるというレベル感だ。
エミュレータと探索
探索を行うのは素晴らしい。しかしそれは将棋や囲碁だからできる性質のものである。将棋や囲碁はルールが完全に書かれているので完全なエミュレータをプログラム上で作成することができる。きわめて高速で動作するエミュレータがあるから、Ponanza含むプログラム達は自己対戦を通して高速に強化学習できるわけだ。
しかしテレビゲームや実際の運転はそうはいかない。最新のテレビゲームをプレイするのは多くの計算量が必要なものが一般的だ。また運転のエミュレータもたくさんあるが限定的だしなにより不正確だ。(この辺の実空間シミュレーションを行うDLの研究がより進むの期待してます!)
Hidden state と探索
DeepMindのMuZero や Tesla (Teslaは今なにを目指しているのか) はどうやら単純にはエミュレートができないテレビゲームや運転も探索問題に落とし込もうとしている。それは問題の空間をHidden state(or Space vector)という比較的低次元の圧縮されたベクトルに変換し、そのベクトルのまま探索するということだ。
# 雰囲気を伝えたいだけの本当に適当なMuzeroの探索に関する疑似コード
Search(HiddenState)
{
# 圧縮されたベクトルをみて今の価値と次のAction候補の可能性を出す
Value, GoodActions = Predict(HiddenState)
if(SearchShouldBeEnd)
UpdateSearchTreeTable(HiddenState, Value) # 調べて情報を次のPickNextActionなどに活かす
return Value
# 探索と報酬のジレンマ
# 単純に良さそうなActionではなく、すでにどれくらい調べたかなどを見て次のActionを選ぶ
Action = PickNextAction(GoodActions)
# State と Action を入れたら新しい State がでてくる(!!!!)
NewHiddenState = Dynamics(HiddenState, Action)
Value = Search(NewHiddenState)
UpdateSearchTreeTable(HiddenState, Value)
return Value
}驚愕するべき点は圧縮されたHidden stateをそのまま更新する関数Dynamicsの存在だ。これはResnetやTransformerが実際の実装だと思われるが、Hidden StateとActionを入れれば、なんと進行した新しいHidden Stateが得られるわけだ。
もちろんこれはゲームや運転に関するすべての情報を保持しているとは限らない(おそらく運転などではかなり欠損することになる)が逆に次のActionやValueを考える上ではむしろ好都合である可能性すらあるとDeepMindは言っている。
確かに運転のとき、脇になる木の葉っぱの形状を詳細に理解することはナンセンスだろう。また多くの場合、歩行者の服の柄を運転手が理解する必要もないだろう。
未来の予想とはエミュレートと評価との繰り返し
近年の古典的ボードゲームのコンピュータの偉大な成功は評価関数の機械学習化だけでなく、機械学習前提の評価関数を探索と融合させた事だ。我々はこのアプローチが多くの現実領域でも成功すると信じて自動運転EVスタートアップTuringを作った。またこのアプローチの先に汎用人工知能の可能性があると思っている。
未来を信じるAIエンジニアの応募を待っている。
この記事が気に入ったらサポートをしてみませんか?