
trocco®開発ログ 2022/06「データカタログのクエリエディタ、他」

マネージド ETL&ワークフローサービスの trocco® を開発している primeNumber社エンジニアの森田です(自己紹介記事)。trocco® はデータエンジニアの方々の様々な手間を削減し、より価値ある業務に集中していただくためのプロダクトです。BigQueryなどを中心にした分析基盤構築をサポートします。
今回は trocco® で2022年の6月にリリースした機能をいくつか紹介します。
trocco® とは?

https://trocco.io/lp/index.html
trocco® は、MySQL や S3 などのデータを BigQuery を始めとしたデータウェアハウス(DWH)に統合し、分析基盤を構築するためのデータエンジニアリングサービス です。大企業からスタートアップまで様々な企業にご利用いただいており、お客様からは「trocco® 無しでは分析基盤構築は考えられない」など、嬉しいフィードバックを多々頂いてます。
trocco® が解決する課題
BigQuery などを利用して分析基盤を構築する会社は増えていますが、多くの場合、データ統合(MySQL や S3 のデータを BigQuery に転送する)のパイプラインはデータエンジニアの方が自前で開発しています。安定したパイプラインを構築・運用するのは非常に手間がかかり、データエンジニアがより戦略的な業務に時間を割きにくいという課題がありました。
trocco® を利用することで、データ統合部分をまるっと任せることができます。
現在はデータ統合だけでなく、データエンジニアリング周辺の様々な業務までカバー領域を広げていて、分析基盤構築については全てを trocco® に任せられる状態を目指しています。
リリース機能 1「転送設定: 転送元Google Ad Managerのユニット指定方法が選択可能に」
まずは、trocco® のメイン機能である、データ転送機能の改修を紹介します。
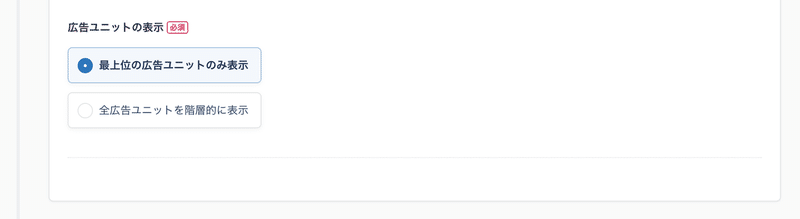
データ転送機能の「転送元Google Ad Manager」にて、最上位の広告ユニットとユニットのいずれを表示するか指定できるようになりました。
転送元Google Ad Managerは、Google Ad Managerで管理しているデータを別のサービスに転送することができる機能となります。
trocco®のデータ転送の多くにおいて、OSS の Embulk を利用しています。
Embulk はプラグインアーキテクチャ構造になっており、転送元/転送先それぞれ Embulk のインターフェースに従って Java や Ruby でプラグインを開発することで、データ転送を行うことができます。
転送元Google Ad Managerで使用しているEmbulkプラグインは、primeNumberのエンジニアメンバーがRubyで開発をしております。
trocco®のアプリケーション開発については、サーバーサイドはRails、フロントエンドはReact(TypeScript)で開発されています。ユーザーが実際に触る画面側や API、Embulk をキックする部分などの改修を行うことで、実際にユーザーに対して機能を提供することが可能です。
リリース機能 2「データカタログ: クエリエディタにてON句のサジェスト対応」
分析者が DWH 上のデータをより楽に分析できるように、trocco® では様々なメタデータの可視化を行うデータカタログ機能を開発しています。
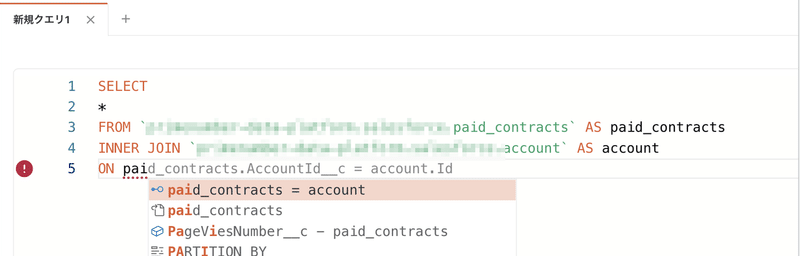
データカタログ機能ではクエリエディタを開き、BigQuery のクエリを実行することができます。今回のアップデートでON句のクエリ入力時にサジェストが表示されるようになりました。
データカタログは、リードエンジニアの中根さん、新卒2年目の上原さん、プロダクトオーナー小林さん、デザイナー飯田さんの4人体制で開発を進めています。
データカタログはデファクトが無い領域です。実際のお客様の声をいただきつつ、自分たちがデファクトになれるように開発を進めています。
リリース機能 3「ワークフロー: trocco®一括登録が可能に」
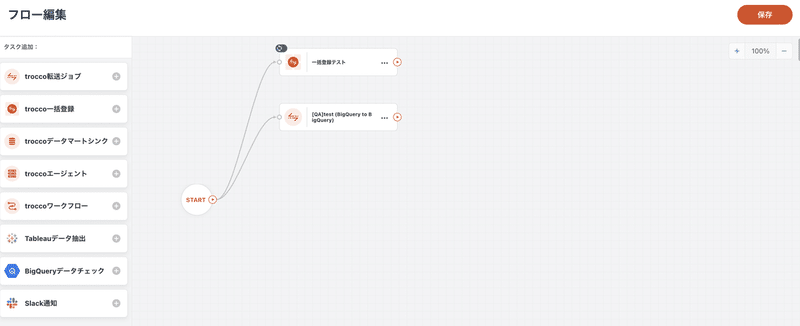
trocco® には、転送設定やSlack通知などに依存関係を持たせてジョブを実行することができる「ワークフロー」機能があります。
下記の画像のようにGUI形式で転送設定などの依存関係をシンプルに定義することができます。
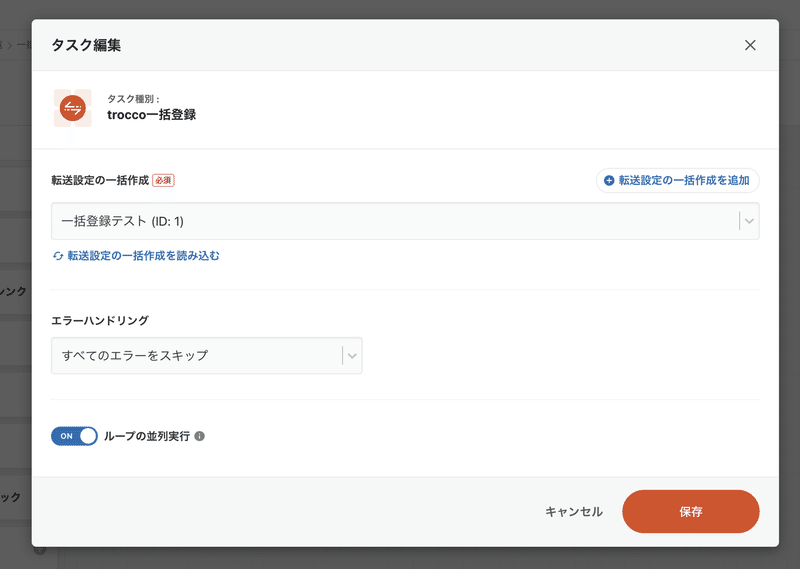
また、転送元MySQL・転送先BigQuery間の転送設定を一括で作成することができる「一括登録」機能があります。
今回のアップデートでは、一括登録機能を使って作成した転送設定を、ワークフローにも一括で定義することができるようになりました。
MySQLのデータベース内にある全てのテーブルをそれぞれBigQueryに転送する設定を一括で作成することができます。
例えば、MySQLのデータベース内に3つのテーブルがあるとします。
これらのデータをBigQueryに転送するために、従来は転送設定を3つそれぞれ作成する必要がありましたが、一括登録機能を使うことで一括で3つ作成することができるようになります。
trocco®のワークフローや先ほど紹介したデータ転送機能は、trocco®改善チームのエンジニアメンバーがタスクの優先度に応じて開発をおこなっております。
タスク管理には、GitHub のプロジェクトボードを使い、優先度をメンバーがひと目で分かるよう管理をしています。
Data Engineering Study #15 開催
データ分析基盤について学ぶ Data Engineering Studyの最新回が2022年8月に公開されます。今回はReverse ETL 特集回となります。
primeNumber からは CPO の小林が登壇します。
新入社員インタビュー公開🎉
3月に入社した岡陽介さんと串田佑介さんのインタビュー記事が公開されました。primeNumber への転職を決めた理由や普段の仕事内容についてお話しています。
primeNumber: 会社紹介
現在募集中のエンジニア職種
もちろん、カジュアル面談からでもOKです!
その他、エンジニア以外の職種も絶賛募集中です
この記事が気に入ったらサポートをしてみませんか?