[CHI2019採択] 教師なし学習で会話中の挙動をリアルタイムに解析し、会話の質を向上させるシステム

2019年には、ヒューマンコンピューターインタラクション(HCI)のトップ国際会議のひとつである ACM CHI 2019 に、荒川(東京大学)と矢倉(筑波大学)が共同で執筆した挙動解析に関する論文 “REsCUE: A framework for REal-time feedback on behavioral CUEs using multimodal anomaly detection” が Full paper で採択され、Glasgow で口頭発表を行いました。本記事ではその内容について簡単に紹介したいと思います。
論文はこちら: https://arxiv.org/abs/1903.11485
1. 背景
他人のささいな身振り手振りなどから、その人が何を考えているのか、あるいはどういう状態なのかを推察できるというのは、人間に備わっている一つの能力です。中にはこの能力に特に秀でている人もいて、メンタリストなんて呼ばれたりもしますよね。このように人の内的状態と挙動の関係性については、古くから研究が行われており、あの有名なダーウィンの論文 [1] にまで遡ることができます。

画像出典: https://www.tvnz.co.nz/shows/the-mentalist
ではコンピューターによって人の挙動から内的状態を推察することはできるのでしょうか? SF映画などでは、AIがそのような能力を持っていて、自然に人とコミュニケーションしている様子なども描かれていたりしますよね。
先行研究を調べてみると Social Signal Processing [2] や 会話情報学 といったキーワードが出てきます。近年では機械学習の発達もあり、画像から表情・顔の向きなどの様々な情報を取得できるようになってきたため、それらを活用して会話を分析する研究も行われています。例えば、Samroseら [3] は会話中の表情や声の明るさを自動で分析して可視化するシステムを開発しています。
[2] Figure 5 から抜粋
しかし、このように表情や声の明るさなどの分かりやすい側面だけに着目して解析を続けていくことで、冒頭に挙げたような「人の心を読む」という方向性は達成できるのでしょうか? 人の会話というのはそのような単純なものではないはずです。表面上は微笑んでいても、本音は全く逆だったりとか。相手の内的状態を汲み取るのが得意な人は、きっと前後の文脈やパターン化できないような機微にさらなるヒントを見つけているはずです。
先行研究を調べる中でぶつかったこのような疑問から本研究は始まりました。どのようにして人の会話の複雑なダイナミクスにコンピューターが立ち入っていけるのかについて、一つの方向性を示した論文になります。
2. 問題設定: コーチング
今回の研究では、会話相手の複雑な内的状態を推し量ることが求められる具体的なシチュエーションとして、コーチングに着目しました。コーチングとは、プロのコーチとそのクライアントが対話を通じて、クライアントの学習、成長、変化を促す育成方法の一つです。コーチは直接アドバイスを与えるのではなく、クライアントの潜在的な考えを引き出すような質問を投げかけることが重要 [4] とされています。そしてコーチは会話を継続させながらも、相手の細かい挙動に注意を向け、深堀りを行うべきポイントを見極めます。

つまり、コーチにはクライアントとの会話を継続させながら、さらに相手の細かな挙動に注意を向け、次の質問を考え出すという困難なスキルが要求されます。このうちの一部でもコンピューターの力を借りることができれば、コーチにはとてもありがたいはずです。
しかしそれには、先行研究が扱っているような「相手が微笑んでいるかどうか」等の表面的なシグナルを超えて、それぞれの相手の傾向や癖も踏まえた、複雑で扱いづらい領域までを考慮する必要があります。実際、現場のコーチに表情分析を行うプロトタイプを使ってもらったこともあるのですが、全く参考にならないし、むしろ会話中に可視化結果を表示されても邪魔だという声が返ってきました。
3. アイデア
どうにかコーチとコンピューターが手を取り合える方法はないのか。そう考えた我々は、一つの結論にたどり着きました。それは、観察と解釈を分離するということです。
コンピューターは文脈を読み取ることができません。会話相手が腕を組み始めたとしても、それが考え込んでのことなのか、それとも無意識のうちに防御的な姿勢を取っているのかを解釈することはできません。だからこそ既存研究は、微笑んでいるかどうかのような、分かりやすい側面だけに着目してきたのでした。
一方で、コーチにとってそうした解釈はお手の物です。経験を積めば、そうしたシグナルが何を意味しているのか瞬時に判断することができます。むしろ難しいのは、シグナルを見落とさないようにすることです。会話を続けながら冷静に観察し続けるということはなかなか大変です。クライアントの話を聞き、次の質問を考えているうちに、相手を観察するのがおろそかになってしまうこともあります。
コンピューターは観察が得意だが解釈が苦手、そしてコーチは解釈が得意だが観察が苦手。これらそれぞれの得意を組み合わせることで、ちゃんと使えるシステムが作れるのではないかと考えました。
4. 提案システム
そうして我々が開発したのは、教師なしの異常検知モデルによって会話相手の挙動を観察し、シグナルを見つけ出すというアルゴリズムです。教師なし異常検知を使うことによって、そもそも「微笑んでればOK」「腕を組んでいればNG」といったパターンに縛られることなく、相手それぞれの傾向を考慮しながら、急な挙動の変化をシグナルとして見つけ出すことができるようになるのです。
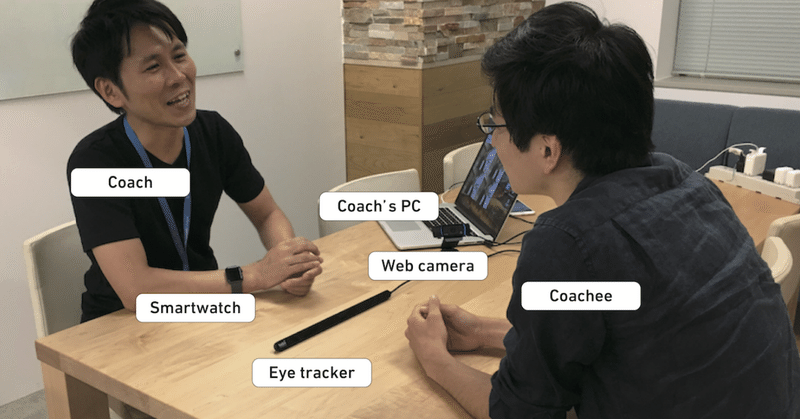
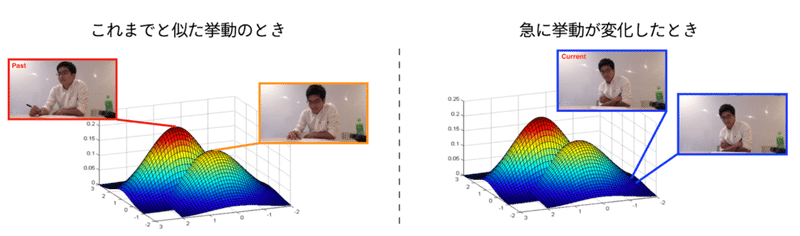
具体的には、Webカメラから取得した会話相手の姿勢や表情と、アイトラッカーから取得した視線方向を、混合ガウス分布(GMM)に基づく異常検知モデル [5] に入力します。そうすることで、左図のように相手のよくある挙動を見つけ出しながら、右図のように急な変化が起きた場面があれば検知することができるようになります。
また、コーチの観察を肩代わりするという点では、こうしたシグナルを見つけたときにそれをリアルタイムに伝えてあげなければなりません。しかし、コーチの会話の邪魔になってしまっては元も子もありません。そこで、我々はスマートウォッチを使って、シグナルを検知したときにコーチにそれとなく知らせることができるようにしました。
もちろんそれだけでは不十分です。例えば、相手が急に腕を組んだのを検知し、それをスマートウォッチで知らされたとしても、コーチにとってはあまり参考にならないでしょう。なぜなら、シグナルとして解釈する上で重要なのは「挙動がどう変わったか」という点だからです。ここで再びGMMの出番です。下図のように、GMMから得られるこれまでの代表的な挙動と検知された挙動とを並べて表示することで、会話中にパッと画面をみただけで変化を知ることができます。

以上の仕組みを組み合わせて、1台のPCとWebカメラ、アイトラッカー、スマートウォッチで動作するシステム REsCUE を実装しました。
5. 実験と結果
まずは、事前実験としてどのような特徴量を解析すべきかを検証しました。詳細は論文に任せますが、結果としては視線と姿勢の組み合わせが良いということが判定されました。これの特徴量を用いて検知された挙動の例を以下に示します。

例えば椅子に寄りかかる、手を腰に当てる、違う方向を向く、といった挙動が抽出されています。確かに、こういった挙動を検出する機械学習モデルを個別に用意することはできますが、コーチにとって有用であろうシグナルすべてを網羅するのはほぼ不可能です。その点において、教師なし異常検知に基づく本手法の有効性が確認できます。同様に、コーチングのセッションごとにモデルが学習されるため、毎回カメラの位置や向きが変化しても問題なく動作することも利点です。
次にこの組み合わせを使ったシステムを実際のコーチングに使ってもらい、コーチに使用感などを聞いてみました。その結果、ほとんどのコーチが REsCUE のサポートが有用だったとコメントしました。詳細な議論は論文に委ねますが、REsCUE が実際の現場でもコーチをサポートすることを確認できました。
6. 結論と今後
まとめると本論文では、以下のような貢献をしました。
・会話中の視線・姿勢といった非言語情報に対して、教師なし学習に基づく異常検知手法を適用し、重要な挙動の変化をリアルタイムに検出するアルゴリズムを提案
・そのアルゴリズムに基づき、コーチング中にリアルタイムに可視化・フィードバックを行うことで、コーチをサポートするシステム REsCUE を開発
・実際のコーチとクライアントを交えた状況で評価を行い、コーチが会話を維持しながら、同時にクライアントの内面の状態を推測するのに REsCUE が役立つことを確認
今後の展望として、提案したアルゴリズムはコーチングに限らず幅広いドメインに応用が可能だと考えています。これは、先行研究と異なり、ルールベースのアルゴリズムではないためです。例えば、認知症のセラピーの場でも、患者さんとの会話とその様子の観察というのは重要であるため、同様にサポートが可能であると思います。また、COVID-19 によって進んでいるオンラインコミュニケーション(例えばオンライン面談)などにも適用が期待されます。
さらなる方向性としては、リアルタイムにではなく、後から会話を振り返る・要約するために使うということも考えられます。例えば、コーチングの現場では行ったセッションの動画を見ながら、コーチが次のセッションの組み立て方を考えることがあります。また、別のコーチがその動画を見て、担当コーチにアドバイスをするというケースもあります。このような時に動画を始めから最後まで見るのではなく、REsCUE が推定した重要シーンだけを抜粋する形で見ることで効率化できないでしょうか? 実は REsCUE の発展版として、振り返り効率化のための INWARD というツールを開発し、その研究は翌年の CHI2020 に採択されました。次回の note ではそちらを解説していきたいと思います。
7. FAQ
Q1. なぜ異常検知手法の中でもGMMを使ったのですか?
A1. GMMにおいて、各コンポーネントの正規分布の中心はそれまでの挙動から学習された代表的な様子を表しています。これらの画像と、異常と判断されたフレーム画像とを並べて可視化することで、コーチが画像を比較しながら異常の意味を解釈できるのが、GMMを用いる利点です。コンポーネントの数だけ代表的な姿勢を抽出できますが、数が多いと一度に複数の比較を強いられるため、リアルタイムの使用には不向きです。システムを作る過程で、コンポーネント数を2とするのがちょうど良いと判断しました。
Q2. 表情はなぜあまり効果がなかったのでしょうか?
A2. 表情が上手くいかなかった理由としては、会話中の表情認識が難しいという点が考えられます。今回のアルゴリズムは一枚一枚のフレームごとに推論を行っています。例えば普通に話しているが、口が開いている時の画像を表情認識にかけると、怒っているなどの誤推定をされてしまうケースが観察されました。そのため、特徴を上手く抽出することができなかったと考えています。
しかし、もちろん表情は重要な非言語情報の一つです。近年では複数のフレームから感情を推定するビデオ表情認識 [6] のような技術も登場しています。これらを使うことで、より会話中の挙動情報を組み込んでいくことが期待されます。提案したアルゴリズムは入力データに対する仮定を設けておらず、さらに教師なし学習であるため、再学習の必要なく入力特徴量を変えて改善していくという柔軟な開発を可能にします。
Q3. 音声は使わないんですか?
A3. 言語情報を使うことでより会話のコンテキストを解析できるため、強力なサポートシステムの作成が期待されます。しかし、現状の日本語音声認識、特にリアルタイムで動くもので精度の良いものがなかったため、言語情報は使用しませんでした(今回の実験ではコーチングは日本語で行われました)。
音声から得られる別の情報として、強弱や抑揚などの準言語情報の解析も考えられます。しかし、コーチとクライアントがそれぞれ話している中で、リアルタイムにそれぞれが話している音声を分離するのは難しく、またピンマイク等を装着するのも現実的でないと考えたため、準言語情報も使用しませんでした。
Q4. コーチングの会話を撮影されているのは、クライアントにとっては嫌じゃないですか?
A4. コーチングでは前述の通り、振り返りを行うために録画をすることもあります。そのような場合には撮影の許諾を得ています。本研究においても、参加者の同意のもとに実験を行いました。
8. 余談: 本研究に至るまで
本研究のミソは、ルールベースで表情などの単純なシグナルを解析するのではなく、解釈は人に任せて、コンピューターは観察を行うのが、人とAIの協調の適切な姿なのではないかと考えたところです。もちろんいきなり思いついた訳ではなく、この着想に至るまでには試行錯誤がありました。
このプロジェクトは元々、論文化などを考える前に、著者らが会話の情報を解析するツールを趣味的に作ってみたところから始まりました。その時のプロトタイプのデザインがこちらです。

表情・発話度・顔の向きなどを解析して可視化するシステム “Providence”
参加者の表情・発話度・顔の向きなどを可視化するツールで、会話中の様々な情報を可視化しようというビジョンのもと Providence と名付けました。上の図では開発陣4人で使用してみた時のものです。合宿をしながら意気込んで作ったものでしたが、率直な感想としては、「情報量が多い」「本当に必要な情報?」「怒っているかなどの情報は相手の顔を見たらわかる」といったように、散々でした。まさしく本文でも紹介したような、ルールベース解析というアンチパターンを踏んでしまっていた訳です。
この合宿の後、荒川と矢倉が反省会をする中で、「コンピューターが会話の全てを理解するのは無理なので、解釈は人に任せよう」というミソのアイデアに辿り着きました。その後サーベイをしたり、プロトタイプを作ったりする中で、研究としての新規性が言えると判断し、共同で研究を開始しました。当時は、二人合わせて2‐3本しか論文の執筆経験がない中で右往左往しながら実験デザインや原稿を作り上げていくなど苦労も多かったのですが、二人の中では始まりの研究であり、思い入れの強いプロジェクトです。
参考文献
[1] C. Darwin. 1872. The Expression of the Emotions in Man and Animals. John Murray, London.
[2] J. K. Burgoon, et al. 2017. Social Signal Processing. Cambridge University Press, Cambridge.
[3] S. Samrose, et al. 2017. CoCo: Collaboration Coach for Understanding Team Dynamics during Video Conferencing. Proc. ACM Hum.-Comput. Interact. 1, 4, 39:1–39:24.
[4] G. S. Bloom, et al. 2005. Blended Coaching: Skills and Strategies to Support Principal Development. Corwin Press, Thousand Oaks, CA.
[5] K. Yamanishi, et al. 2004. On-Line Unsupervised Outlier Detection Using Finite Mixtures with Discounting Learning Algorithms. Data. Min. Knowl. Discov. 8, 3, 275–300.
[6] S. Zhang, et al. 2019. Learning affective video features for facial expression recognition via hybrid deep learning. IEEE Access 7, 32297–32304.
この記事が気に入ったらサポートをしてみませんか?