BigDataの4Vについて

こんにちは。@hayata_yamamotoです。
普段は、データマイニング関連の仕事をしています。データをどう伝えていけば、多くの人がデータからいろんな学びを得ることができるか、知らなかった事実に気づけるかが最近のテーマです。
はじめに
今回のトピックは、私が片手間によくパラ見してる以下の本の一章に出てくる "The four V's of Big Data" について書いてみます。余談ですが、データをどうやってとるかから、データベースの話、データマイニングについてなど、幅広いトピックを扱っていてこの本は面白いです。私自身は、まだまだ理解できていない部分が多いのですが、一章だけでも読む価値があるなあと思っています。ご興味ある方はぜひ。
The four V's of Big Data

1. Variety / 多様性
構造化/非構造化データ、異なるデータソースなどデータの多様性があること。最終的には、複数のデータセットを混ぜてマージして、指標を作ったりすることもある。
2. Velocity / 速度
加工が必要になるようなデータの発生頻度。あまりにも速度の早いデータはバッチ処理だけでは対応が難しい。サービス形態によって速度はまちまち。
3. Veracity / 正確性
データの信ぴょう性。データが取れたからと言って、曖昧なデータや不正確なデータをためていては勿体無い。あまりにも信ぴょう性がないと、「今計算してるUUは、本当にUUですか?」となってしまう(怖いね)
4. Volume / 容量
取得できるデータ数や格納できるデータ容量。お金でどうにかできる可能性は高い。
背景と動機
多くのプロダクトにおいて、主な分析対象となるのはユーザーが何か行動を起こしたログやそれによって発生するイベントになります。すごくオーソドックスなテーマですが、これだけでできることは結構あります。
通常、これらの様子を可視化する方法として、カスタマージャーニーマップやプロセスモデリング、システム構成図などが利用され、この資料を元に、私たち分析者は「ふむふむなるほど、データはこういう感じで溜まってるのね」という理解をしています。
岩崎は「統計的因果推論」の中で、変数間の相関関係や因果関係などをデータ分析で適切に扱うのために、
データ= 数値 + 背景知識
とデータをシンプルに説明し、背景知識の必要性を述べています。これは、数値だけみたときに擬似相関を相関と誤解してしまう可能性を防ぐために必要になる概念です。
カスタマージャーニーマップやシステム構成図を見れば、交絡変数の存在(例えば、イベントとイベントの間に別のイベントがあるとか)を発見することができたり、加工済みデータを扱っている際には、「加工のせいで」統計的有意と出てしまっているだけで、本当はそうでないというケースを考慮に入れられたりします。
とはいえ、現実的に「すでに良い状態でデータが存在するケース」はほとんどありません。もし運良くそのような組織にいたとしたら、とても幸せなことだと思いますし、そのノウハウを色々得ること自体がとても有意義です。
では、(将来的な分析を見据えた上で)できるだけ良い状態でデータを貯める為に私たちには何ができるでしょうか?
私たちに何ができるか
先ほどの4Vを二つにカテゴリ分けしてみます。
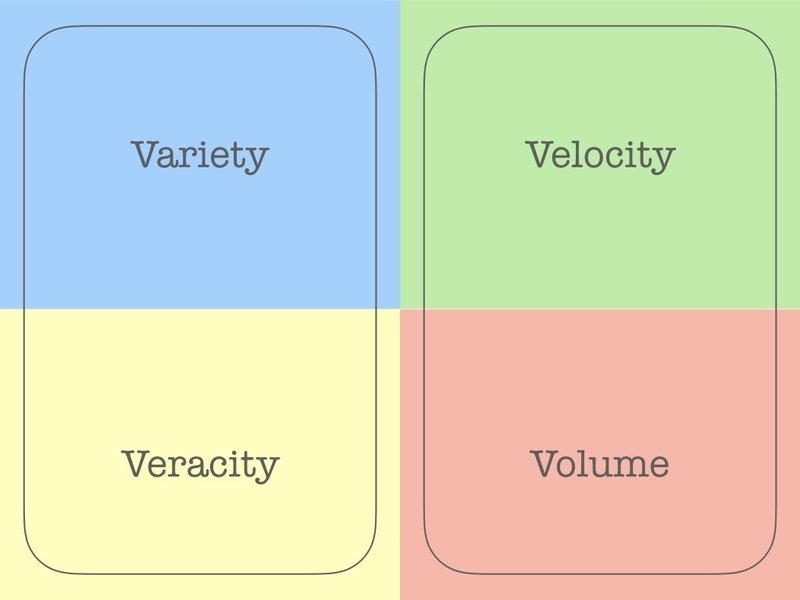
カテゴリわけの意図は、以下の通りです
左:抽象的、技術以外の領域が絡む、定性的(どちらかといえば)
右:具体的、技術的解決が可能そう、定量的(どちらかといえば)
このとき、右側の技術的解決はDBやログ収集の開発をしているエンジニアに頼むとより、具体的でかつ効率的な方法を提案してもらえそうです。どちらかといえば、この領域で技術的に専門でない(人の多い)私たちが右側の領域に入ると苦労する可能性や、ボトルネックになってしまう可能性があります。
そうすると、ターゲットは左側に絞るのが良いのではないでしょうか

データの多様性については、ビジネス要件や開発のフィードバックに必要なKPIを定義する際に、「どのようなデータが必要だ」とか「こういう施策をやっている」というドメイン知識と定量的な視点を合わせることで、何かしら役にたつ意見を出すことができます。
もちろん、実装等に関してはエンジニアさんにやってもらうことが多いので、技術面での議論を深めていく必要がありますが、最終的な利用想定まで考えた上で実装を進められることは、開発する側、依頼する側どちらにとってもメリットがあります。ある意味、ビジネスで使うためのデータを、エンジニアリングがわかる分析者が代弁するようなイメージですかね。
正確性に関しては、私たちの知見を共有することでいろんなリスクをヘッジできます。例えば、データ容量の削減や処理の効率化の為に、何かしらの処理が入るとして、その処理は一体どういうことをやっていて、どういう情報の損失が存在するのか、そこから何が言えなくなりそうかを考えることができるのは価値があります。
必要な要件に対して、これからやろうとしている開発やデータ収集が本当に目的の達成の為に十分なものなのかを判断する役割を担う必要が有るでしょう。その際には、データ収集度合いのメトリクスをダッシュボードなどで共有して、いろんな人が見えるようにすることも重要な役割です。
まとめ
* Variety, Velocity, Veracity, Volumeがビックデータの4Vです。
* その役割を大まかな2つのカテゴリに分けました。
* (少なくとも)分析者が役立てるのは、Variety, Veracityの2つです。
* エンジニアさんほんといつも助かっています(涙目)
読了ありがとうございます。よければいいねも!