
コンテンツ分類のカードソーティングを階層的クラスタリングで定量化した話

はじめに
はじめまして!グロービスでデータサイエンティストとして働いている永沢・菅沼です。
ビジネススキルを動画で学べる GLOBIS 学び放題 というサービスについて、行動ログやアンケート調査データの分析を担当しています。
この記事では、GLOBIS学び放題の動画コンテンツのカテゴリ分類に、カードソーティングというUXリサーチ手法と階層的クラスタリングという機械学習を組み合わせて適用した事例をご紹介できればと思います。
尚、カードソーティングはUXリサーチャーが担当し、その結果を用いた階層的クラスタリングはデータサイエンティストが担当しています。
動画コンテンツのカテゴリ分類に関する課題
GLOBIS学び放題では動画コンテンツを、「思考」「戦略・マーケティング」など、MBA科目に対応した複数のカテゴリに分類していました。
他方で、ユーザーやクライアント企業からの要望を受けて、既存カテゴリに収まらない多様な種類の動画コンテンツを制作する見通しになり、そうした新しい動画コンテンツを適切に配置できる新たなカテゴリ体系が必要となりました。
カードソーティングによる新カテゴリ分類検討
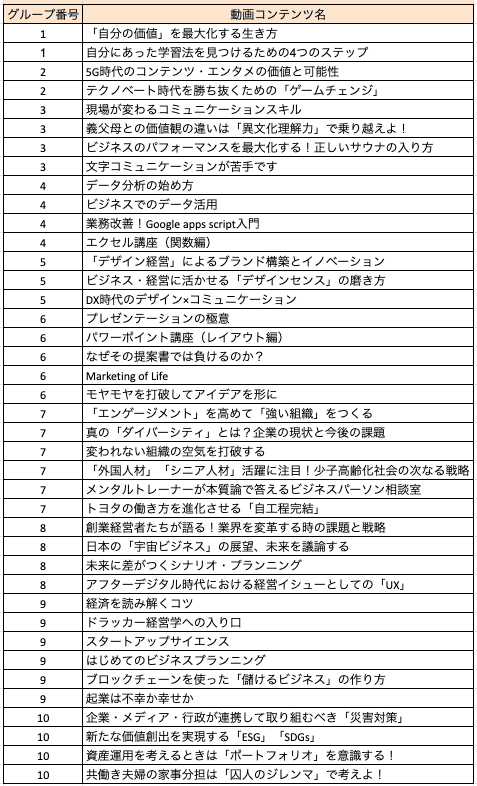
新しいカテゴリ分類設定にあたり、まず最初にカードソーティングというUXリサーチ手法で、ユーザーが新しい動画コンテンツについて、どのコンテンツとどのコンテンツが内容的に同じグループだと感じるかを調査をします。
具体的には、被験者として募集した15名のユーザーに、あらかじめ選んだ40種類の新動画コンテンツを、コンテンツの内容が似ているかという判断基準で、個々のユーザーの主観で自由に分類してもらいます。この時、分類するグループの数も、ユーザーごとの判断に任されます。
そうすると、ユーザーごとに、下記のような動画コンテンツの分類結果が得られます。
15名ユーザーがいれば、15名分の異なる分類結果が手に入ります。
カードソーティング結果への機械学習の適用
カードソーティングによる分類はユーザーの主観にもとづくので、分類結果はユーザーによって、まちまちです。
とはいえ、「多くのユーザーが、動画コンテンツAと動画コンテンツBを同じグループに入れている」といった大半のユーザーに共通するグルーピングの傾向があります。こうしたグルーピングの傾向を読み取ることで、新しいカテゴリ分類の参考にすることができます。
しかし複数のユーザーの分類結果を人が読み込んで傾向を理解するのは、調査対象ユーザーが多いほど、労力がかかりますし、精度も悪くなります。
そこで複数のユーザーの分類結果を機械学習で処理することで、動画コンテンツのグルーピングに関する一定の傾向を、効率的に抽出できないか、試してみることにしました。
距離行列の作成
機械学習による処理を考えたときに、カードソーティング結果を用いて、動画コンテンツ間の類似性を表現したデータを作成できれば、クラスタリングなどの手法に持ち込み、動画コンテンツのグルーピングをすることができるのではないか、と思い付きました。
動画コンテンツ間の類似性は、ある二つの動画コンテンツを同じグループに入れているユーザーが多いほど、その両コンテンツの類似性は高くなるという基準で判断することにしました。このとき、類似度は下記のように定義できます。
類似度 = 二つの動画コンテンツを同じグループに入れたユーザー数
ただし、この定義式の場合、数値が大きいほど類似度が高くなりますが、数値が小さいほど類似度が高い方が、距離行列として扱えるため、機械学習での処理にかけやすいです。そこで動画コンテンツ間の距離を下記のように定義しました。
距離 = 被験者となったユーザー数 ー 二つの動画コンテンツを同じグループに入れたユーザー数
その上で、動画コンテンツ間の距離を要素とする下記の距離行列を作成しました。
(尚、今回の分析では、40種類の動画コンテンツの中で、どのコンテンツにも関連性が低い2コンテンツについては、分析のノイズになる懸念があると判断し、対象外とした上で、距離行列を作成しています。)

階層的クラスタリング
作成した距離行列に基づいて動画コンテンツをグルーピングをするために、今回は階層的クラスタリングのウォード法という手法を用いることにしました。階層的クラスタリングは、動画コンテンツ間の距離をトーナメント表のようなデンドログラムというグラフとして図示することができます。
階層的クラスタリングの実装には、pythonライブラリであるscipyのscipy.cluster.hierarchy.linkageを使いました。
クラスタリングの妥当性評価には、コーフェン相関係数という指標を用いました。コーフェン相関係数が高いほどクラスタの歪みがなく、その余事象1-コーフェン相関係数でどのくらい不純物が紛れているかが分かります。今回の分析ではコーフェン相関係数が0.7となり、一般的に妥当とされる基準値に近い結果となりました。
動画コンテンツのグループ分けは、デンドログラムをもとに人為的に判断をする必要があります。ただしscipyのdendrogramという関数でcolor_thresholdパラメータを指定することで、グループ間距離に応じたグループの識別を行えます。このパラメータ値はデフォルトは60ですが、今回は30にしたところ、納得感のあるグルーピングになったので、そちらを採用しています。
以下、実装時のコードとなります。
from scipy.cluster.hierarchy import dendrogram, linkage
from scipy.cluster.hierarchy import cophenet, set_link_color_palette
from scipy.spatial.distance import squareform
import matplotlib.pyplot as plt
# ユークリッド距離によるウォード法での階層的クラスタリング実行
linked_remove = linkage(distance_matrix_remove,#distance_matrix_removeは距離行列
metric='euclidean', method='ward')
# グループ識別のための色設定
set_link_color_palette(['green', 'navy', 'red', 'purple', 'lawngreen', 'orange', 'deeppink' ])
# デンドログラムの作図
plt.figure(figsize=(36, 10))
dendrogram(linked_remove,
orientation='top',
labels=distance_matrix_remove.index,
distance_sort='descending',
show_leaf_counts=True,
color_threshold=30) # color_thresholdで閾値距離を設定
plt.title("③関連性が低い2コースを除きグループ間距離30を閾値としたグループ分け",fontsize=30)
plt.xticks(rotation=90,fontsize=30)
plt.ylabel("グループ間距離",fontsize=30)
plt.tight_layout()
plt.legend()
plt.show();
# 距離行列をcophenetの引数として入力するためにsquareformに通す
pdist_remove = squareform(distance_matrix_remove)
# コーフェン相関係数算出(第1戻り値)
total_c_remove, d_remove = cophenet(linked_remove, pdist_remove)
print(f'コーフェン係数: {total_c_remove:.3f}')
print(f'グループに歪みが含まれているかもしれない割合は{1-total_c_remove:.3f}')
分析結果
階層的クラスタリングにより以下のデンドログラムを出力することができました。
各テキストは、動画コンテンツのタイトルです。

color_thresholdパラメータ指定によるグループ分けが、色分けとして表示されています。
グループごとの特徴を見てみると
緑色のグループは時事ネタ
紺色のグループはDX
赤色のグループはツール
紫色のグループは起業・経営
黄緑色のグループはプレゼン・コミュニケーション
黄色のグループは内省・メンタル
ピンク色は組織・人間関係
と解釈できそうです。
階層的クラスタリングにより、おおよそ特徴が明確になったグループを作成することができたと思います。このように比較的分かりやすい結果になったのは、カードソーティングで、多くのユーザーが似通った分類を行っていたためと考えられます。
尚、近しい動画コンテンツをグループに分類することはできましたが、新しいカテゴリ分類自体は、この結果を参考材料にして、最終的にはUXデザイナーなどのビジネスサイドが総合的に判断することになります。カードソーティングを定量化することで、UXデザインとデータサイエンスのハイブリッドでカテゴリ分類新設が実施できた事例と言えます。
終わりに
一般的にUXリサーチとデータサイエンスは無関係な別物として扱われることが多いですが、今回の事例のように、データサイエンスの手法を活用することで、UXリサーチで得られた複数ユーザーの調査結果を、より適切かつ効率的に定量化できることがあります。
ユーザー心理の調査はUXリサーチが得意とするところです。ただし、それだけではユーザー心理を定量的に把握できないのですが、場合によっては、その欠点をデータサイエンスによって補うことができるのです。
プロダクトのUXデザインを積極的に進めるためにも、今後も、定性的なUXリサーチと定量的なデータサイエンスを上手く融合し、シナジー効果を発揮させて行きたいと考えています。
参考文献
書籍名:「はじめてのパターン認識」 著者:平井有三 出版社:森北出版株式会社 pp-157-164
グロービスで一緒に働く仲間を募集しています!
グロービスのデータサイエンスチームでは、一緒に働けるデータサイエンティストを探しています!
まずは、カジュアル面談を通して、あなたに合う組織かどうか確かめてみませんか?
https://recruiting-tech-globis.wraptas.site/
この記事が気に入ったらサポートをしてみませんか?