
宣言的 Blue/Green デプロイで EKS バージョンライフサイクルに立ち向かう話

こんにちは、グロービスで SRE をしている @yukin01 です。
私たちがサービスの実行基盤として導入を進めている Amazon EKS について、いかに認知負荷を下げつつ Kubernetes バージョンのライフサイクルに向き合っているか、を話します。
インプレースアップグレード
Kubernetes 自体は年に3〜4回の頻度でマイナーバージョンがリリースされます。そのマネージドサービスである EKS はアップストリームのリリースからしばらく経ったあとにサポートが開始されて、そのサポートは少なくとも14ヶ月間続きます。詳細についてはドキュメントをご覧ください。
サポート終了まで特定バージョンを使い続けるのは極力避けたいところですが、かといって数ヶ月ごとに CHANGELOG を追いかけつつ、デグレを防ぎながらアップグレードし続けるのもなかなか大変な話です。
実際 AWS 側もアップグレードの計画が重要だと発信していて、GUI からマネージドで実行できるインプレースアップグレードが用意されています。
ただし、この操作は不可逆なので、デグレが発生した場合に切り戻しができません。また、1つずつしかバージョンを上げられないため、飛び級でアップグレードしたいときに少し不便です。
基本的にはインプレースアップグレードで問題ありませんが、プロダクション運用を見据えた際に先ほどの懸念が出てきました。
Blue/Green デプロイによるアップグレード
現在、弊チームではクラスタの Blue/Green デプロイを用いたアップグレード戦略を取っています。
かなり簡略化して説明すると、AWS Load Balancer Controller (ALBC) の TargetGroupBinding を使いつつ、ターゲットグループの重み付けで2つのクラスタを切り替える形でアップグレードを実現しています。
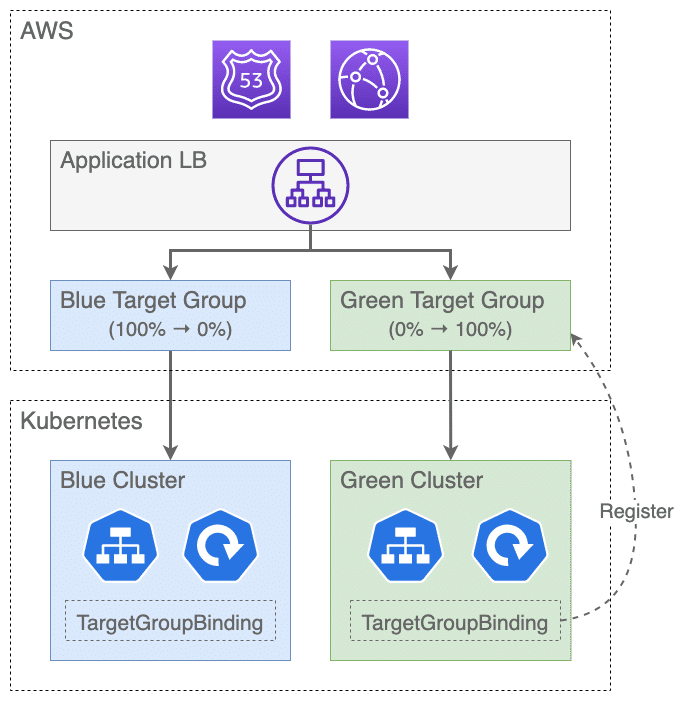
この方式だとターゲットグループの重み付けで自由にロールバックできますし、クラスタを2つ用意するので任意のバージョンにアップグレードできます。めでたくインプレースデプロイの懸念点を解消できましたが、もちろんこれはデメリットなしの銀の弾丸ではありません。
EKS クラスタを運用したことのある方ならもう察しているかもしれませんが、アップグレードの度にクラスタを一から立ち上げる必要があるので、そこを工夫しないとかなりの工数と認知負荷がかかってしまいます。
そこで、EKS クラスタを可能な限り少ない工数で宣言的に立ち上げて、Blue/Green デプロイの心理的ハードルを下げるためにやっている取り組みを1つずつ紹介していきます。
Terraform と Argo CD の責任分界点について
宣言的な IaC や GitOps を実現するツールとして Terraform と Argo CD を利用していますが、任意のリソースが両方のツールで管理できてしまうため、使い方に気をつけないと責任範囲が重複してしまいます。
よって、弊チームでは基本的に以下の2つの原則に従うようにしています。
・AWS リソースは Terraform で管理する
・Kubernetes リソースは Argo CD で管理する
そもそも、AWS リソースである EKS クラスタを立ち上げることで初めて Kubernetes リソースのデプロイ先が確定する、という時間的な依存関係が存在するため、全体的な依存関係を一方向に保つためにはこの原則に従う必要があります。
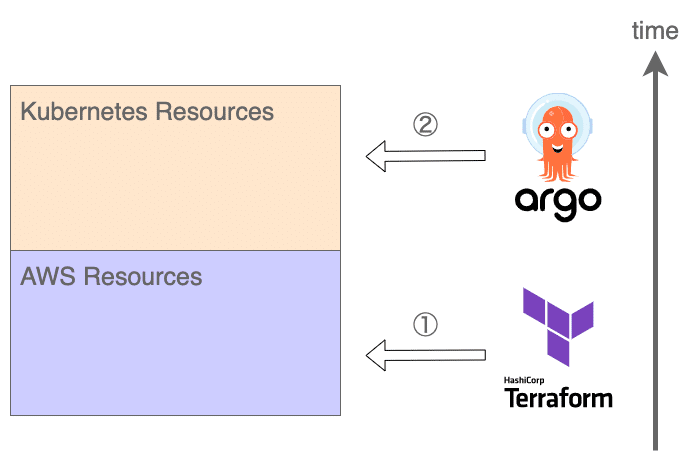
このように責任分界点をシンプルにすることで、認知負荷の削減に繋げています。
EKS はステートレスなアプリケーションのみ動かす
クラスタを頻繁に入れ替えるためにはイミュータブルである方が圧倒的に扱いやすいので、データストアとしてのコンテナは使わずに、RDS や ElastiCache などのマネージドサービスを利用するようにしています。もちろん、開発環境のような揮発しても良い環境では Redis コンテナを使う場合もあります。
ステートレスなアプリケーションのみ動かすのであれば他のマネージドサービスとの連携が取りやすい ECS の方が適しているのではないかという気はしますが、それでも EKS を選定した理由についてはこちらの記事で取り上げています。
運用のためのクラスタを分離する
Blue/Green デプロイの場合、切り替え前後のクラスタが共存する状態が発生します。そのため、アプリケーションコンテナと Argo CD コンテナを同じクラスタに乗せてしまうと、各クラスタを管理するための Argo CD コンテナが複数存在することになり、Web UI にアクセスするための FQDN が1つに特定できなくなってしまいます。
もちろんその形で運用する方法もあるとは思いますが、今回は Argo CD を独立したクラスタ(= Ops クラスタ)にホストすることで、FQDN を一意に定めつつ、Blue/Green 両方のクラスタを一元管理できるようにしました。
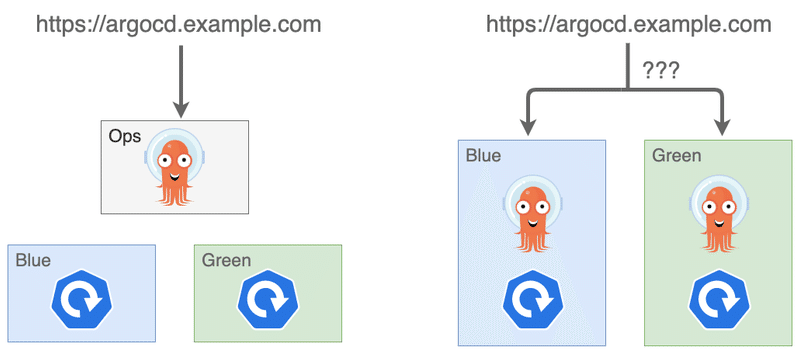
ちなみに、Ops クラスタは上記の理由から Blue/Green デプロイに適さないので、インプレースアップグレードを採用しています。
Terraform AWS modules を積極的に使う
これまで大まかな方針について紹介してきましたが、ここからは各ツールの具体的なプラクティスを紹介します。
クラスタ構築のためのツールとして eksctl が有名ですが、Terraform AWS modules を組み合わせても同じことが実現できます。(クラスタ本体には terraform-aws-eks を、IRSA には terraform-aws-iam を使う形)
公式ドキュメントでは eksctl を使った手順が紹介されていることが多いですが、作られるリソースから逆算すれば Terraform AWS modules で置き換えられます。また、EKS 以外の AWS リソースは Terraform を使って宣言的に管理しているので、この方が結果的にコードの設計をシンプルに保てると考えていますし、現状特に不便は感じていません。
クラスタの命名規則
切り替え前後のクラスタが共存し得るので、名前をユニークにするためにサフィックスとして日付(YYYYMMDD)を付け加えています。1日に2回以上アップグレードを行うことは基本的にしないので、これで十分運用できると判断しました。
責任分界点のルールを違反して作る Kubernetes リソース
クラスタ本体を作成したあとは Argo CD で Kubernetes リソースを管理するフェーズですが、その前に Argo CD が依存している Kubernetes リソースを先にデプロイする必要があります。
Argo CD がまだ使えない状態でのデプロイなので、この作業を宣言的に管理するためには別のツールを使うか、もしくは諦めて手作業で行う必要があります。今回の構成で必要なリソースは以下の通りです。
・AWS Load Balancer Controller
・Argo CD の Web UI をインターネットに公開するため
・GitHub 関連の Secret
・プライベートリポジトリにアクセスするため
・GitHub OAuth App を利用したログイン連携を実現するため
AWS Load Balancer Controller については Terraform の Helm Provider で管理しています。他の Helm Chart は Argo CD で管理しているので統一感がなくなってしまいますが、将来的に EKS add-ons で管理できるようになることを考えると、Terraform 管理の方が移行コストがかからないので悪い選択ではないと認識しています。
resource "helm_release" "albc" {
name = "aws-load-balancer-controller"
repository = "https://aws.github.io/eks-charts"
chart = "aws-load-balancer-controller"
version = "1.1.0"
namespace = "kube-system"
values = [yamlencode(
{
clusterName = module.eks_ops_20201204.cluster_id
serviceAccount = {
name = "aws-load-balancer-controller"
annotations = {
"eks.amazonaws.com/role-arn" = module.irsa_aws_load_balancer_controller.iam_role_arn
}
}
}
)]
provider = helm.ops_20201204
}Secret については Terraform の Kubernetes Provider で管理しています。基本的には Kubernetes External Secrets を使ってパラメータストアと連携しているのですが、依存リソースが余計に増えてしまうので例外的に直接 Terraform で定義しています。
resource "kubernetes_secret" "argocd_github_repo" {
metadata {
name = "github-repo-secret"
namespace = kubernetes_namespace.argocd.metadata[0].name
labels = {
"argocd.argoproj.io/secret-type" = "repo-creds"
}
}
data = {
url = "https://github.com/globis-org"
username = local.secrets.github_username
password = local.secrets.github_token
}
type = "Opaque"
provider = kubernetes.ops_20201204
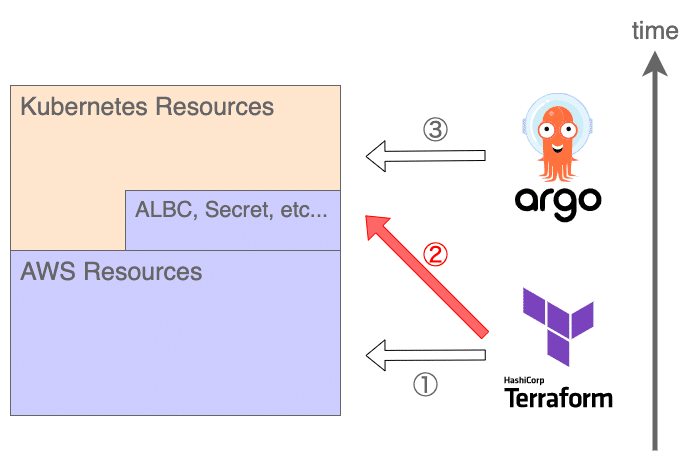
}ちなみに、Kubernetes リソースを Terraform で管理すると責任分界点のルールに違反することになってしまいますが(下図の②)、俯瞰したときの時間的な依存関係は一方向に保たれているので許容しています。
Argo CD の初回デプロイについて
Argo CD 本体のデプロイも Argo CD では管理できない作業の1つです。正確には、2回目以降の Argo CD デプロイは Argo CD 自身で管理する方式を採用しているので、初回デプロイだけが問題となります。
この初回デプロイについて、先ほどと同様に Terraform を使う方法もありますが、二重管理を防ぐために現状は手作業で対応しています。最低限、デプロイコマンド自体はシェルスクリプトとしてコード化しています。
App of Apps Pattern を活用する
Argo CD では、Kubernetes リソースを Application という単位でまとめてデプロイします。クラスタを立ち上げるタイミングではこの application を大量にデプロイする必要があり、効率良く管理するために App of Apps Pattern が紹介されています。
弊チームではこのパターンを取り入れつつ、クラスタ全体を複数の application や app of apps に分割して、さらにこれらを中央集権的な app of apps で管理しています。
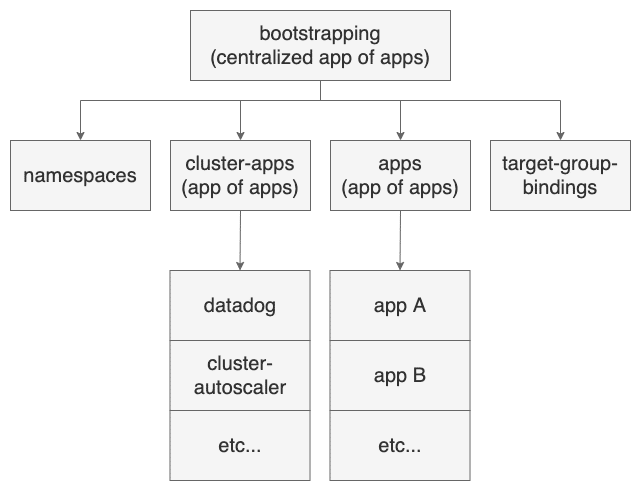
各要素の詳細は割愛しますが、app of apps は Helm によって構成されており、フラグを使って子要素のデプロイタイミングを制御できるようにしています。こうすることで、最初の app of apps さえ手動でデプロイしてしまえば、あとは PR ベースで段階的にデプロイすることが可能となり、失敗したときの原因の切り分けやロールバックが容易になります。
ちなみに、最近では App of Apps Pattern よりも柔軟に Application を管理できる ApplicationSet Controller が開発されているので、将来的には置き換えていきたいと考えています。
Helm Subchart を活用する
マニフェストの構築には Kustomize と Helm を使い分けていますが、サードパーティのツールは Helm Chart として公開されていることが多いので、その場合は Helm を使っています。
ここで、外部の Helm Chart を Application のマニフェストに直接定義するのではなく、ローカル Helm Chart の Subchart として定義すると扱いやすくなります。具体的には、Chart に渡すパラメータの関心を Application の定義から分離したり、追加のリソースを定義したりできるようになるので自由度が上がります。公式のサンプルリポジトリでも helm-dependency として実装されていました。
また、この方式では helm template コマンドを実行することで、実際に Argo CD がデプロイするマニフェストと同じ形に展開することができるので、透明性も確保できます。
まとめ
このような設計上のプラクティスを取り入れることで、宣言的にクラスタを立ち上げつつ、Blue/Green デプロイによるアップグレードが容易に実施できるようになりました。
もちろん設計だけ作り込んでも作業自体が属人化してしまっては意味がないので、ドキュメントを充実させたり、作業担当者を持ち回りで割り振ったりすることで知識の平準化を図っています。
駆け足で説明してしまいましたが、細かい設計の意図を伝えきれなかった部分や、もっと良くしていきたいところがたくさんあるので、少しでも興味を持っていただけた方は Twitter で @_yukin01 かチームリーダーの @chroju まで一言声をかけてくださると嬉しいです。ぜひカジュアルにお話ししましょう!
この記事が気に入ったらサポートをしてみませんか?