
「Deep Learning」って何? 復習します! パラメータ更新!

ニューラルネットワークの学習についての手順を確認します。
1 データを取得、訓練データを取り込みます。このときにバッチ処理を行うと大量のデータから効率よく進みます。(高速化)
2 偏微分をすることで勾配を求めて、損失関数が最小になる方向を示します。
3 パラメーターの更新します。
この1,2,3を繰り返すことで訓練データに適応するようにパラメータを設定していきます。この一連の動作を学習と言います。
作成したネットワークにバッチ処理した訓練データを流し込むことで学習を効率よく行えるということです。
パラメータの更新を行うためには、
訓練データ
ネットワーク
を使ってミニバッチ学習で行います。ミニバッチ学習というのは訓練データから無作為にデータを取り出して行う処理です。
まず必要なminist(訓練データ)のデータ、ネットワークを読み込みます。ColabでGoogleDriveからデータを取り込みます。
import sys, os
sys.path.append('/content/drive/My Drive/deep-learning-from-scratch')
from dataset.mnist import load_mnistこれで、ネットワークと訓練データを簡単に実装しています。
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
パラメータの設定です。
iters_num = 10000 ・・・更新の回数
train_size = x_train.shape[0] ・・・ランダムに抽出される数字の幅
batch_size = 100 ・・・抽出される数字の数(ミニバッチの数)
learning_rate = 0.1 ・・・学習率
60,000の訓練データ(train_size)からランダムに100個のデータ(batch_size)を抜き出します。
10,000回(iters_num)繰り返します。
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
そして勾配の計算。
grad = network.gradient(x_batch, t_batch)
最後に更新。
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
確認です。
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# データの読み込み
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000 # 繰り返しの回数を適宜設定する
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 勾配の計算
#grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# パラメータの更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# グラフの描画
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
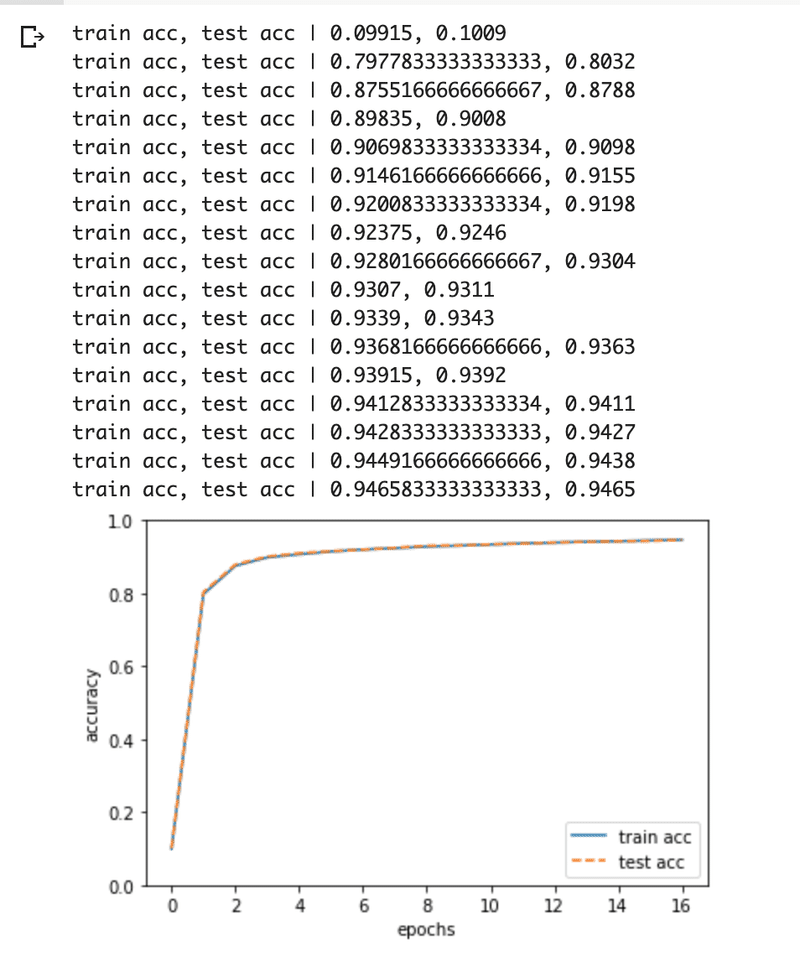
訓練データと認識精度は両方共に向上していることがわかります。
この記事が気に入ったらサポートをしてみませんか?