【ディープラーニング自由研究】LSTM+Transformer モデルによるテキスト生成

Abstract
• Transformer モデルをテキスト生成タスクで使用する場合、計算コストに難がある
• 計算コストを抑えつつ Transformer の予測性能を活かすために、Positional Encoding を LSTM に置き換えた LSTM+Transformer モデルを考案
• 生成にかかる時間を Transformer の約 1/3(CPU 実行時)に抑えることができた
はじめに
Transformer は現在の自然言語処理分野における代表的な深層学習モデルの1つです。さまざまなベンチマークを総なめにした Google の BERT とその派生系 (XLNet, ALBERT, etc.) や、OpenAI の GPT-2 など、最近の研究のベースにあるのが Transformer です。
Transformer の特徴として、LSTM などの従来の RNN にあった再帰構造を排除し Attention を使用することで、学習過程における処理の並列化・高速化を実現している点が挙げられます。また、翻訳などのタスクにおいて、LSTM を上回る精度を出すことも報告されています。精度向上の一因には、過去のステップの情報を直接的に参照できる Attention の仕組みが寄与していると考えられます。
RNN に比べて優位性の多い Transformer ですが、テキスト生成タスクでの活用を考える場合、弱点が1つあります。通常の Transformer は、内部で状態を保持しないため、代わりに Positional Encoding(位置エンコーディング)を用いてトークンの順序性を表現します。この仕組みが原因で、Transformer は生成時において、ステップごとに履歴全体を何度も再計算することになり、RNN よりも多くの計算コストがかかります。
筆者は、上記の弱点に対処するため、Transformer の Positional Encoding を LSTM に置き換えた LSTM+Transformer モデルを考案しました。構造の改良はシンプルながらも、このハイブリッドモデルを使用することで、生成にかかる計算コストを抑えつつ Transformer の予測性能を活かすことができるのではと考え、モデルの実装と実験を行ってみました。
本記事では Transformer の詳細は説明しません。オリジナルの論文を読むのが一番ですが、日本語の文献だと次の記事が参考になります。
• 論文解説 Attention Is All You Need
• 作って理解する Transformer / Attention
計算コスト削減のための LSTM+Transformer モデル
先に述べた通り、Transformer は RNN に比べてテキスト生成における計算コストが増大してしまいます。この点についてもう少し詳しく見ていきます。
図1に RNN と Transformer のテキスト生成における処理を模式化しました。赤色の線で示している箇所がそのステップにおける計算部分を表しています。
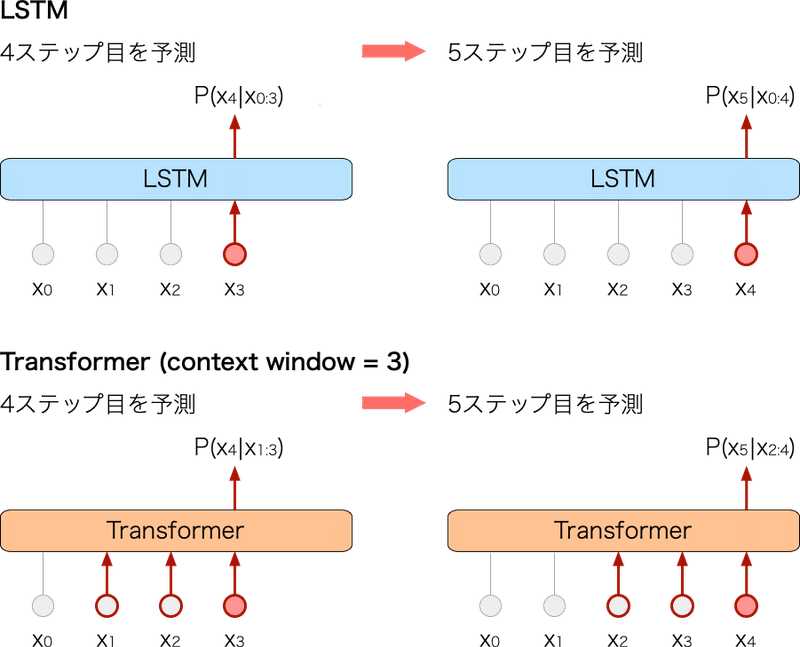
▲図1: LSTM と Transformer のテキスト生成における処理方法の比較
RNN は隠れ状態を保持するため、あるステップの出力を予測する際には、その1ステップ前のトークンを入力するだけで OK です。一方 Transformer は隠れ状態をもたず、位置がスライドすると Positional Encoding の結果が変わってしまうため、同じトークンを何度も入力して計算を行う必要が生じます。この再計算の処理が無駄に感じます。また、コンテキストウィンドウを拡大すればするほど、問題は顕著になります。
そこで、筆者は Positional Encoding の部分を LSTM に置き換え、ステートフルな Transformer を実現することで上記の問題が解決できると考えました。つまり、LSTM をトークンの順序の管理に利用するという企みです。
この考えにもとづいてできたモデルが LSTM+Transformer です(なかなか安易なネーミングです)。
図2にモデルの構成を示します。Transformer の構造を大きく変化させることを避けるため、LSTM は1層を想定しています。
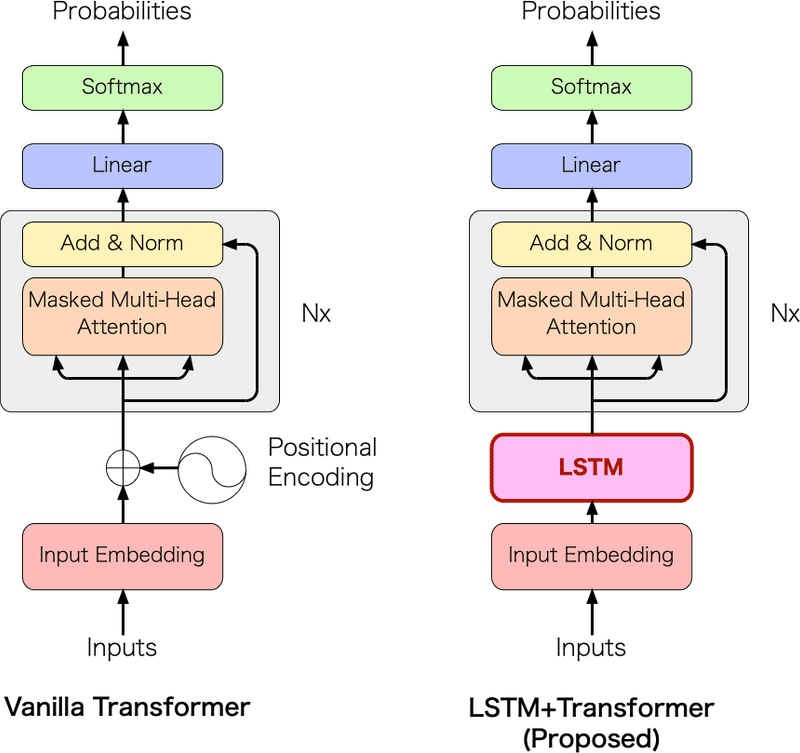
▲図2: Transformer と提案モデル LSTM+Transformer の構成
この LSTM と Transformer のハイブリッド構成により、図1の LSTM のように1ステップずつの入力を繰り返していくだけで良くなりました。もちろん、コンテキストウィンドウを拡大しても入力部分の計算コストは変わりません(ただし Attention の計算には影響します)。
実装
今回は PyTorch 公式の Examples(以降、リポジトリ名の "pytorch/examples" と表記)にある Word-level language modeling をベースに拡張しました。モデルの定義以外にも pytorch/examples のコードからいろいろと変更を加えています。主な変更点は次の通りです。
• LSTM+Transformer モデルを実装
• Validation のタイミングをエポック単位からイテレーション単位に変更(デフォルト 5000 iter.)
• Optimizer と学習率のスケジューラを導入
• TensorBoard 形式のログ出力を実装
今回実装したコードはこちらにあります。
https://github.com/tanikawa04/lstm-transformer
評価実験
提案モデル [LSTM+Transformer] が実際にうまく機能するか検証しました。精度の指標としては単純に Perplexity を用いました。また、実行速度についても計測しました。比較対象として [Transformer], [LSTM] の2種類の性能も確認しました。
■データセット
pytorch/examples ではデータセットとして Wikitext-2 が使われていますが、Wikitext-2 は評価するには規模が小さく、過学習しがちだったので、代わりに Wikitext-103 を用いました。Wikitext-103 のデータの概要を表1に示します。
▼表1: Wikitext-103 の概要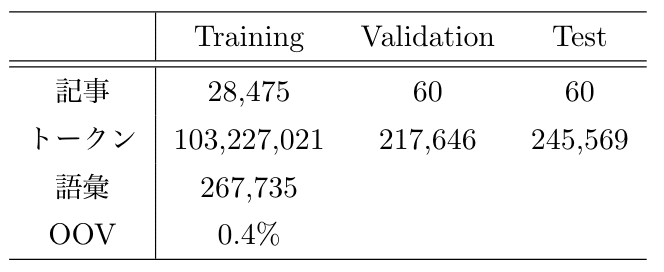
■学習の設定
各モデルのパラメータは次の通りとしました。
[LSTM+Transformer]
1層の LSTM と5層の Transformer layer で構成しました。LSTM の隠れ層および Transformer のサイズは512次元、Transformer のフィードフォワード層は1024次元としました。アテンションヘッドの数は8としました。
[Transformer]
6層の Transformer layer で構成しました。[LSTM+Transformer] での LSTM 1層分を Transformer layer に割り当てたこと以外は同上です。
[LSTM]
3層の LSTM で構成しました。隠れ層のサイズは512次元としました。
3つのモデルの共通設定として、エポック数は5、バッチサイズは16、一度に入力する系列長は64としました。学習に使用した GPU は GeForce RTX 2080 Ti (11GB) ですが、3つのモデルとも上記の設定でメモリにギリギリ載るといった感じです。また、Optimizer には Adam を使用し、次の式にもとづいて学習率のスケジューリングを行いました(このスケジューリング方式は Transformer のオリジナル論文の設定に従っています)。
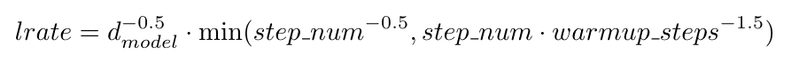
その他、ハイパーパラメータの詳細はリポジトリの train.sh をご参照ください。
Perplexity による評価
学習の結果として、Training set と Validation set による Perplexity の推移を図3に示します。
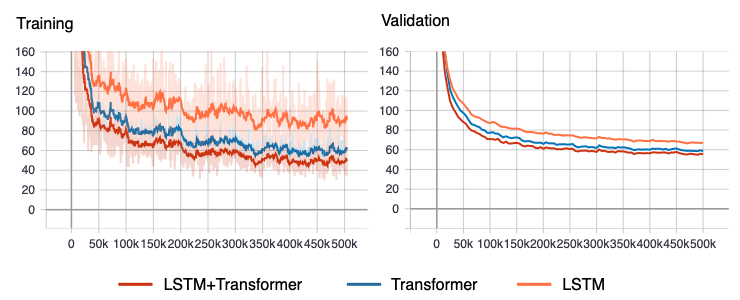
▲図3: Perplexity の推移
どのモデルも順調に Perplexity が減少していきました。ただ、学習の打ち切りが若干早すぎた気がしています。実際にはもう少し Perplexity が下がると思います(とはいえ、学習率がどんどん減少していくのでここから劇的に下がる可能性は低いです)。
Validation の Perplexity が最小となったチェックポイントを使用して Test set で評価しました。結果を表2に示します。
▼表2: Test set による Perplexity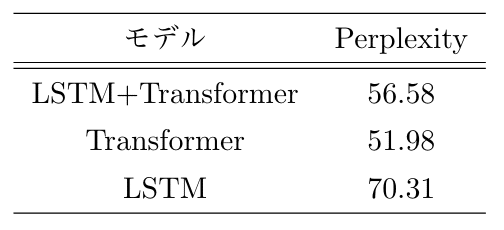
[Transformer] の Perplexity がもっとも低いですが、[LSTM+Transformer] も [LSTM] と比べると良好な結果でした。精度面ではひとまず問題なさそうなので安心しました。
実行速度に関する評価
テキスト生成の実行速度を確認するために、1000ステップ分のトークンの生成にかかる時間を計測しました。GPU (GeForce RTX 2080 Ti) と CPU (Core i5-6500) の双方で10回ずつ計測し、平均値を出しました。結果を表3に示します。
▼表3: 1000トークンの生成にかかる処理時間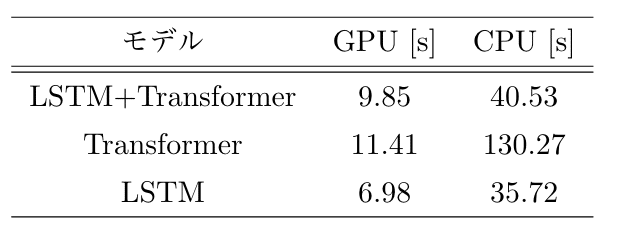
[LSTM+Transformer] の処理時間は、[Transformer] から GPU で 14%、CPU で 69% 削減できました。CPU では [LSTM+Transformer] が [LSTM] に迫る速さが出ていて驚きました(逆にいえることとして、GPU での処理で何かしらボトルネックになっている箇所がありそうです)。
生成文の確認
モデルが実際に生成した文を確認しました。すべてを掲載すると、あまりにも記事が長くなりすぎるので、[LSTM+Transformer] の文の一部のみ抜粋して示します。全容を見たい方は こちらのページ をご参照ください。
■ LSTM+Transformer モデルの生成文の例
= = = 20th anniversary edition = = =
In addition to the whole length , the authors of the trilogy developed the framework for the sixth 1943 , but those existing before . Four volumes were released as series multiple episodes . Ten volumes were released on December 7 , 1955 appear . Time on February 20 , 1956 , similar onto the counting of the DVDs was serialized between July 26 and February 25 , each containing two volumes of fiction " to sign " The Daily Modern anthology in the series . A digital volume collection containing Tom Buckley This was the last page of the script . The following day , another half of The Cockpit was released in the UK as an A @-@ side free anthology DVD .
On March 31 , 2011 , New Moon called it a " space book " and contained images of hangars and toilets . demonstrating the special effects , reviewer stereotype shown in Radiohead 's Kid A , and number 8 of Radiohead 's Radiohead releases since most arrangements were Kylie 's " Parachutes " — based on drawings from Radiohead record Roy Orbison and Stephen reissued " We 're Not Gonna Take It " .
In November 2013 , Radiohead again received 106 @,@ 321 points , at the Cotton Club Play report .
確かに文章らしきものが生成されていますが、内容に一貫性がなく流暢な文にはほど遠いです。これはモデルというよりも、パラメータやコーパスが現状の規模では不十分なのだと思います。
おわりに
計算コストの削減し、Transformer の予測性能を活かすための LSTM+Transformer モデルを考案し、その性能を評価しました。考案したモデルが Transformer に近い予測精度を出しつつも Transformer を上回る処理速度を出すことを確認しました。
実際に生成した文は自然なものとはいえず、まだまだ改善の余地があります。事前学習を活用するなど、より大規模なコーパスで学習するといった工夫が必要だと考えます。
余談ですが、おそらく Transformer において精度向上に大きく寄与しているのが Attention だと考えられるので、本記事のようにわざわざ Transformer を使わなくても、LSTM に Self-Attention を載せる方法もありだと思っています(今回は既存のコードからの拡張が容易だったので LSTM+Transformer の構成にしました)。
今後の予定として、今回の非ネイティブな英語の生成文では詳細な分析が難しいので、近日中に日本語のデータセットを用いて再度評価することを計画しています。また、もう少し流暢な文が生成できるのであれば、個人開発している歌詞生成サービスにこのモデルを組み込みたいと思っています。
----------------------------------------
本文は以上ですが、おまけとして有料コンテンツの領域に本記事の PDF 版を置いておきます。レポート形式のデザイン + 一部加筆している点が差分になりますが、購入してまで読む必要はないと思います。
読者さま側の直接的なメリットは特にありませんが、作者が今後も研究を続けていき、このような記事を発信していくモチベーションにはなるので、支援しても良いという方は購入していただけると幸いです。
▼ PDF サンプル
ここから先は
¥ 300
研究・開発の資金として活用させていただきます。 Chord Worker https://chordworker.diatonic.codes Shikaki http://shikaki.diatonic.codes